DuckDB 不同于其他数据库,并没有使用 B+ 树作为主要索引结构,而是使用 ART (Adaptive Radix Tree) 作为它内部的主要索引结构,本文介绍这一索引。
ART (Adaptive Radix Tree)#
ART ↗ 索引是由 Viktor Leis, Alfons Kemper, Thomas Neumann 等人提出,它相比于 B+ 树的主要区别在于 B+ 树是面向磁盘的,而 ART 则是面向内存的,即 ART 索引是需要全部加载到内存中的。DuckDB 之所以选择这个索引有以下几方面的考虑:
- 随着内存越来越大,并且价格也越来越便宜,我们可以使用纯内存的索引,从而避免磁盘 I/O,提升性能
- ART 索引可以很大程度上节省空间
- ART 索引支持范围查询
- ART 索引有着较高的性能
后续本文会先介绍 ART 这一数据结构,然后配合着 DuckDB 的代码描述 ART 是如何实现的。
Trie 数据结构#
在讲 ART 索引之前,我们先看一下 Trie 树🌲
如果你不知道 Trie 树,可以参考 Wikipedia:https://en.wikipedia.org/wiki/Trie ↗
✅ LeetCode 上也有「206. 实现 Trie(前缀树) ↗」算法题可供参考:
- 请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
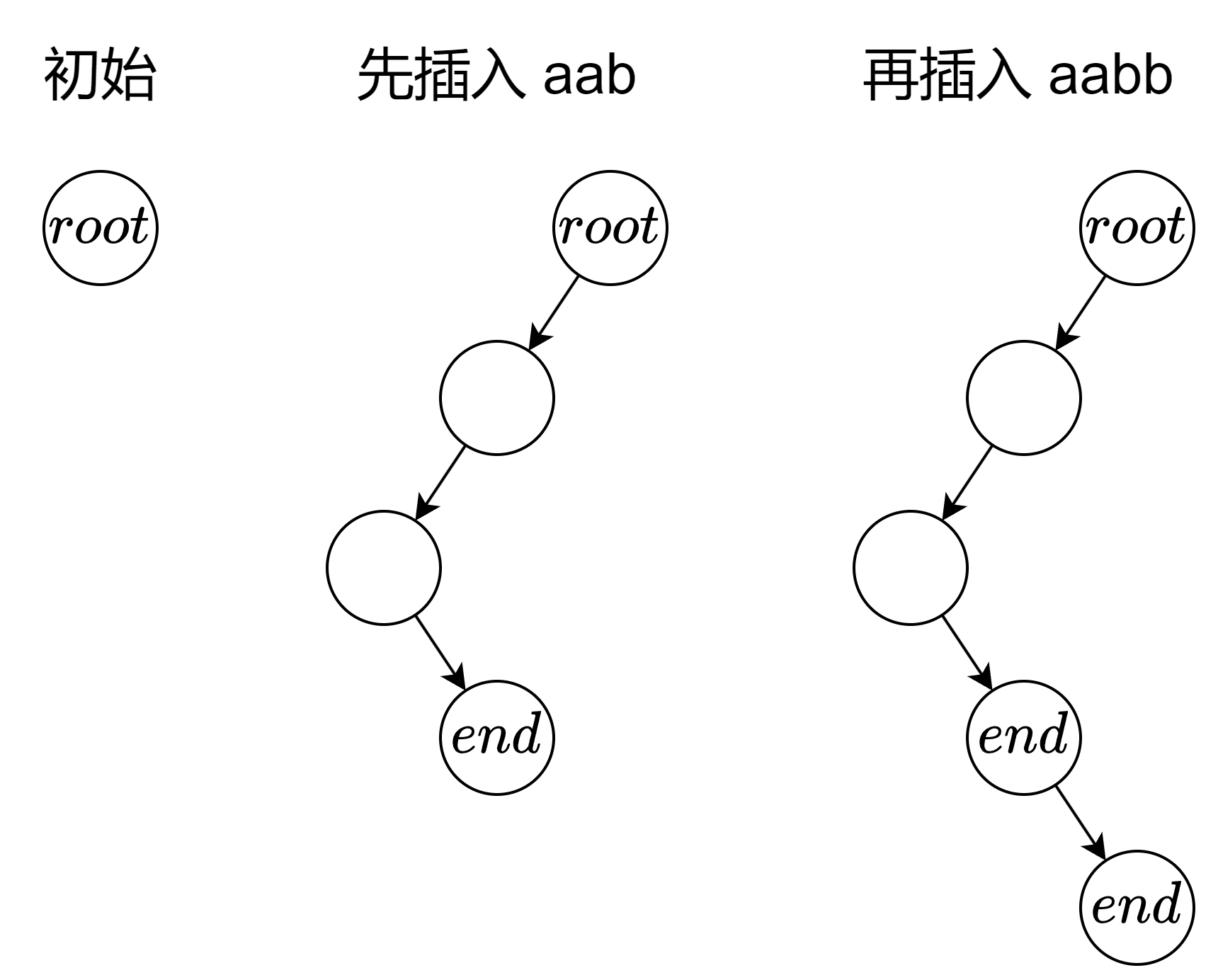
假设字符串里面只有 a 和 b 两种字符。
insert:例如插入字符串 aab,相当于生成了一条移动方向为「左-左-右」的路径。标记最后一个节点为终止节点。再插入字符串 aabb,相当于生成了一条移动方向为「左-左-右-右」的路径。标记最后一个节点为终止节点。
search:例如查找字符串 aab,相当于查找二叉树中是否存在一条移动方向为「左-左-右」的路径,且最后一个节点是终止节点。
startsWith:例如查找前缀 aa,相当于查找二叉树中是否存在一条移动方向为「左-左」的路径,无其他要求。
推广到 26 种字母,其实就是一棵 26 叉树,对于 26 叉树的每个节点,可以用哈希表,或者长为 26 的数组来存储子节点。
struct Node {
Node* son[26]{};
bool end = false;
};
class Trie {
private:
Node* root = new Node();
int find(string word) {
Node* cur = root;
for (char c : word) {
c -= 'a';
if (cur->son[c] == nullptr) {
return 0; // not found
}
cur = cur->son[c];
}
return cur->end ? 2 : 1;
}
public:
Trie() {}
void insert(string word) {
Node* cur = root;
for (char c : word) {
c -= 'a';
if (cur->son[c] == nullptr) {
cur->son[c] = new Node();
}
cur = cur->son[c];
}
cur->end = true;
}
bool search(string word) {
return find(word) == 2;
}
bool startsWith(string prefix) {
return find(prefix) != 0;
}
};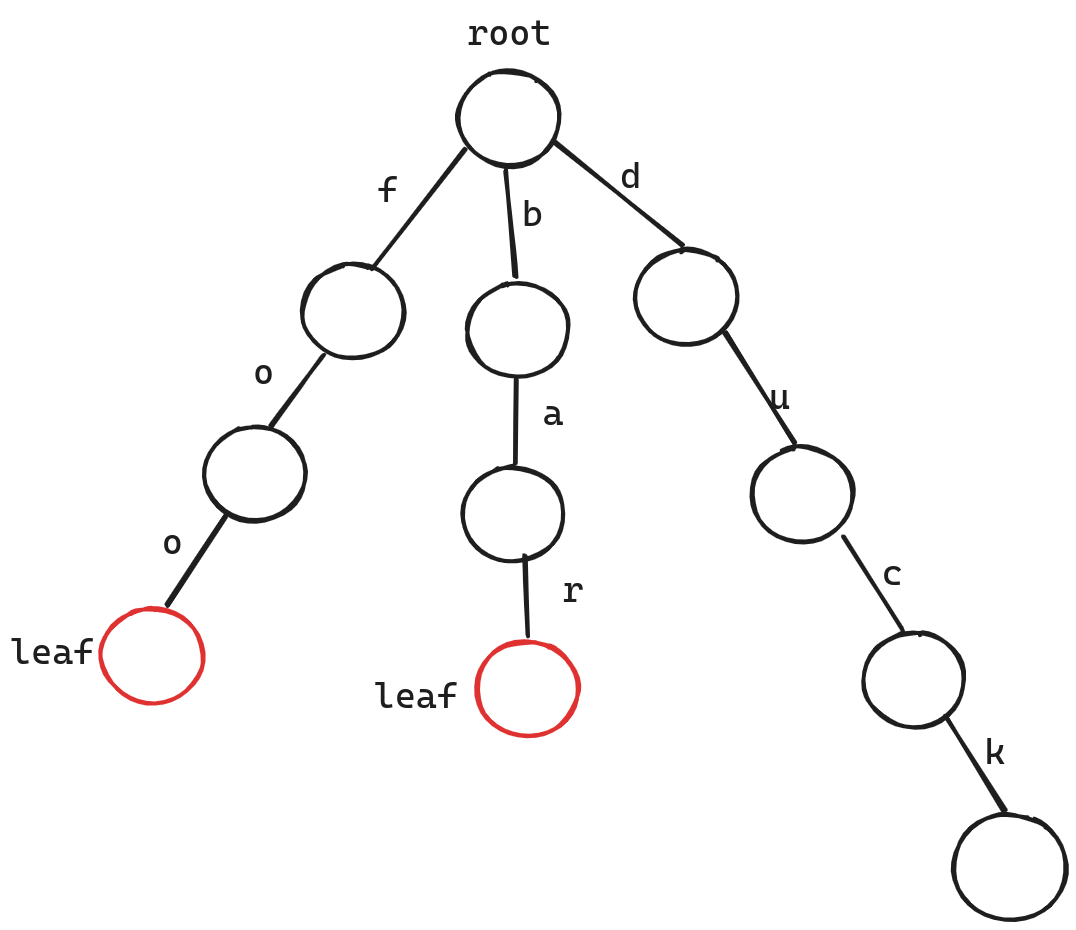
我们可以看到 Trie 树在检索时的优点是,它的检索时间仅与最长的字符串长度有关,而与存储的字符数量无关,这一特性在数据量极大的情况下十分优秀,但是它的缺点是浪费空间,即每个内部节点都需要保存固定数量的指针,即使它仅有极少的子节点。
比如图中的 root 节点,尽管它只有三个子节点,但是它仍然需要保存指向 a,b,c,d,e... 的空指针,这十分浪费空间,其次 Trie 树仅支持保存字符串。
ART 则是在 Trie 树的基础上,解决了它缺点的同时,保留了它的优点,下面来介绍 ART 索引。
对于一个索引而言,我们希望它有以下两个特点:
- 查询速度快
- 空间占用小
但是如果我们使用 Trie 树做索引(ART 是 Trie 的一个变种),我们就要面临取舍:
- 如果内部节点拥有的最大子节点越多(空间占据越多),那么它的高度也越低(速度越快)
- 如果内部节点拥有的最大子节点越少(空间占据越少),那么它的高度也越高(速度越慢)
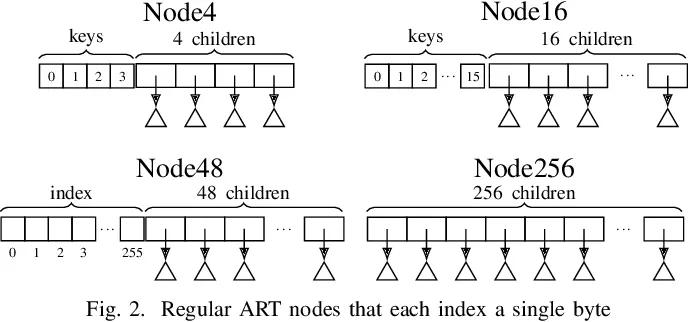
ART 树选择每个内部节点的大小为 8bit(子节点的数量为 256),刚好是一个 Byte。这样的好处是免去了内存对齐的问题,同时在空间与速度上取得了一个较好的平衡,我们称内部节点所占据的位宽为 span。
尽管如此,面对稀疏的数据时,每个节点有 256 个子节点仍然会浪费空间,为了解决这个问题,ART 将内部节点进一步细分为以下四类,我们分别来对其进行介绍:
- Node 4
- Node 16
- Node 48
- Node 256
Node 4#
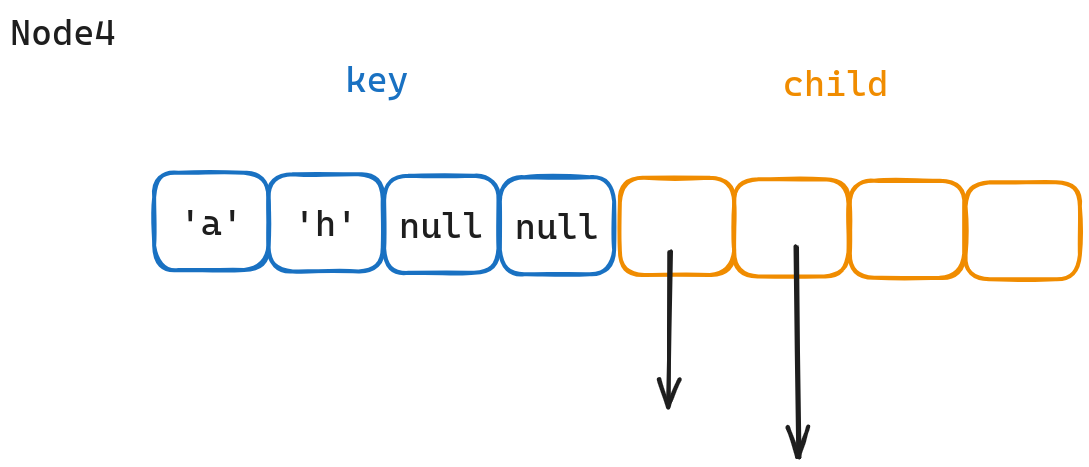
从图中可以看出,Node 4 分为两个部分,一个是 key 数组,一个是 child 数组。
key数组存放 key 的部分内容(也就是 key 的一个 Byte)child数组则是保存对应的子节点的指针
注意,我们为了可以范围查询,key 数组要求顺序存储。
Node 16#
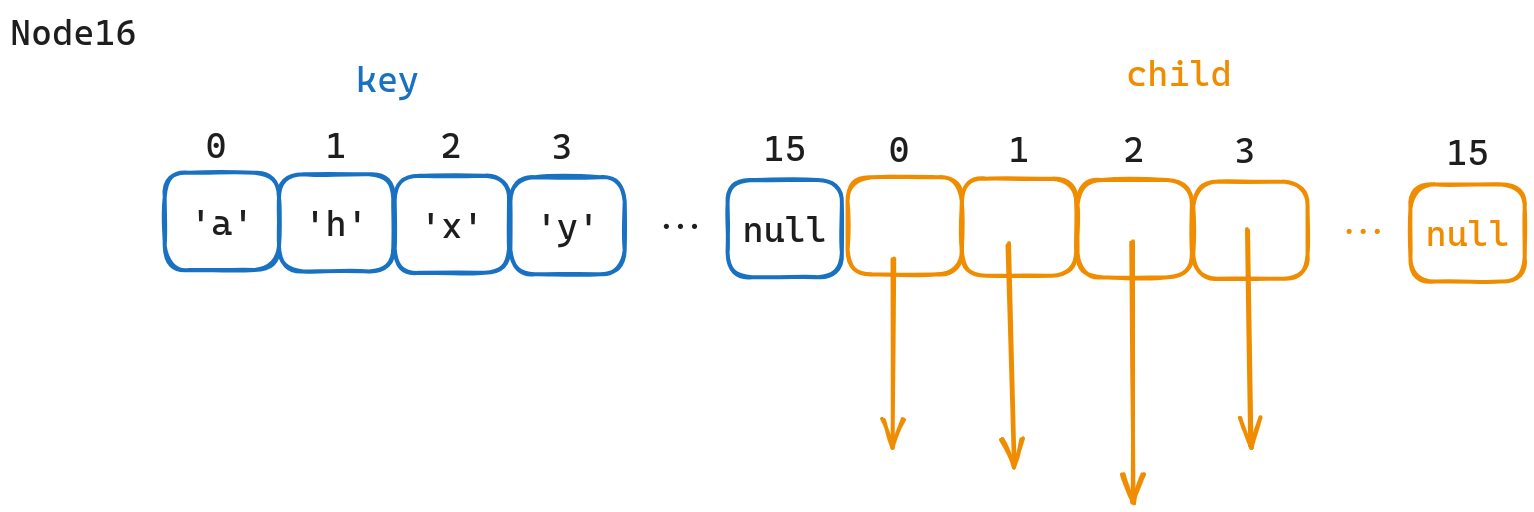
Node 16 和 Node 4 几乎一样,区别只是从 4 个 slot 变成 16 个 slot。
Node 48#
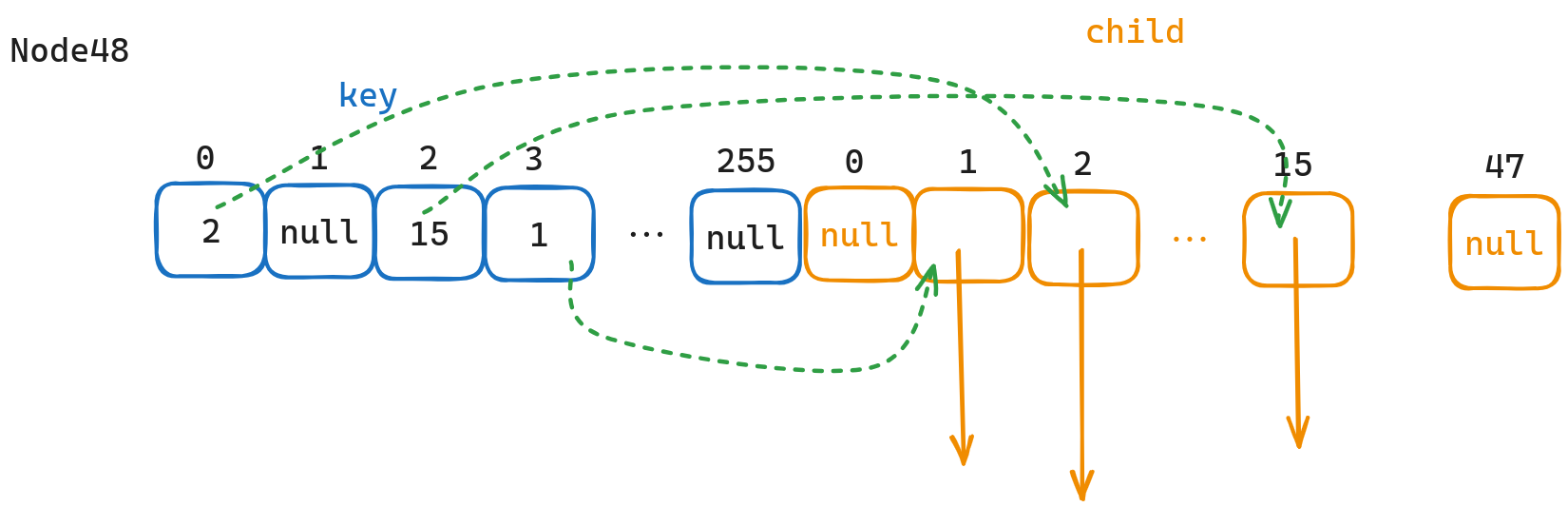
Node 48 和之前介绍的 Node 一样也是分为 key 数组和 child 数组,区别在于 Node 48 的 key 数组长度为 256,且内部 key slot 存放的是指针,指向对应子节点在 child 数组中的位置,这样我们就无需通过遍历找到对应的数组,而是可以直接通过 key 的二进制值作为下标直接定位到对应的 key slot。
实际查询仅需要 child_array[key_array[key]] 即可。
Node 256#
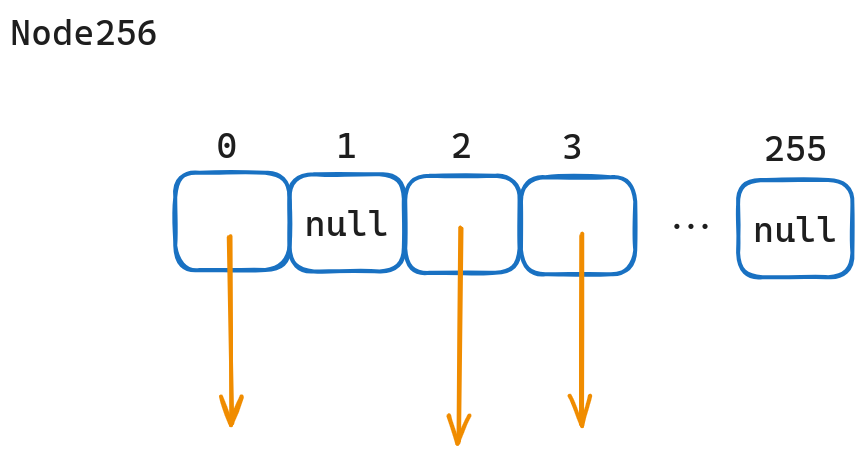
Node 256 就是「Trie 树」原始的内部节点表示形式,仅需要一个数组,数组的下标即为 key,数组中存放的就是子节点的指针。
各种不同类型的 Node 可以相互转换,如果子节点数量超过限制容量就向上转换,如果节点数量相较于限制容量太小就向下转换。
Leaf#
ART 中的叶节点存放的就是 Key 对应的 Value 值,ART 的叶节点可以采用三种形式:
- 单独有一个叶节点类型专门保存 Value
- 和中间节点保持一致的类型,唯一区别则是 child 数组不保存指针而是保存值
- 如果值足够小可以通过位操作和指针一起保存,那么我们可以将值直接存放在内部节点中
🔥 DuckDB 采用的是第一种方式。
Optimization#
在解决了 ART 的空间问题,我们希望可以进一步优化查询速度,即减少树的高度。
论文中有两种方式,但实际上我们可以通过一种简单的做法同时获得这两种优化,每个节点加上 Prefix 标识。
1. Lazy Expansion#
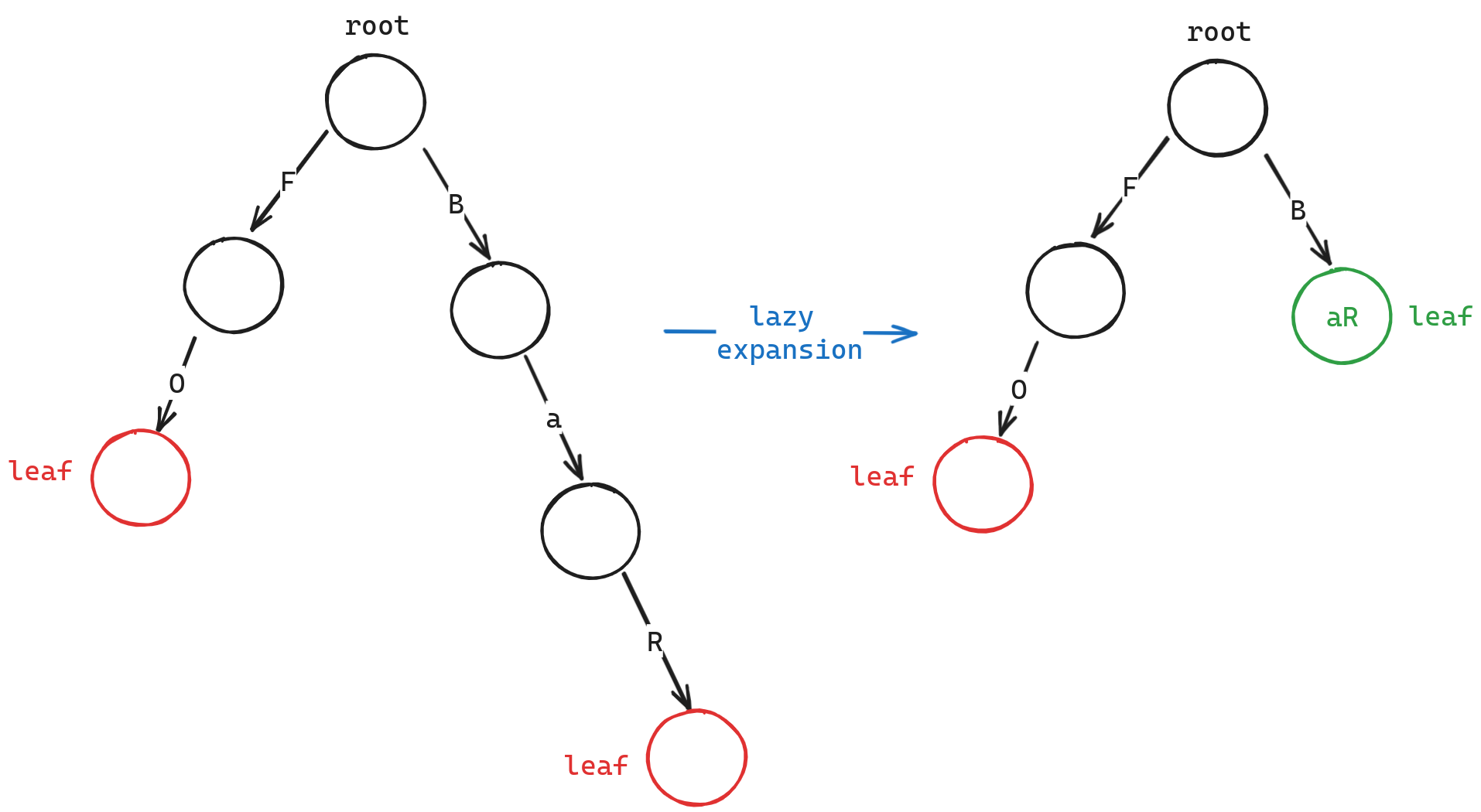
其实这个优化相当简单,我们只需 Leaf 可以保存多个 byte 即可,这样子对于多个只有一个子节点的路径来说,我们可以将其都保存在 Leaf 中,从而减少树的高度。
2. Path Compression#
这个优化和 Lazy Expansion 类似,我们只需让 内部节点 可以保存多个 byte 即可。即如果内部节点有相同的前缀,我们可以将其保存在 Prefix 中,key 数组仅仅只对 key 不同的部分作区分。这样也可以有效地减少树的高度。
如果这里没看懂也没关系,后续我会分析 DuckDB 的代码,那样会更加清晰。
数据转换#
对于 ART 来说,前面介绍的都是对于字符串类型 string,如果作为一个广泛使用的索引,也需要支持不同类型的数据。而 ART 索引实际上是把 Key 作为数据流进行处理的,也就是说如果想要通过 ART 进行范围搜索,我们需要让 Key 保持一个性质,即二进制的大小与该类型的语义大小相同:
因此我们需要对某些数字进行转换。
unsigned int#
无需转化,已经满足需求。
signed int#
将符号为 flip 即可。
float#
static inline uint32_t EncodeFloat(float x) {
uint64_t buff;
//! zero
if (x == 0) {
buff = 0;
buff |= (1u << 31);
return buff;
}
// nan
if (Value::IsNan(x)) {
return UINT_MAX;
}
//! infinity
if (x > FLT_MAX) {
return UINT_MAX - 1;
}
//! -infinity
if (x < -FLT_MAX) {
return 0;
}
buff = Load<uint32_t>(const_data_ptr_cast(&x));
if ((buff & (1u << 31)) == 0) { //! +0 and positive numbers
buff |= (1u << 31);
} else { //! negative numbers
buff = ~buff; //! complement 1
}
return buff;
}char#
UCA 算法 ↗已经做出了定义。
Unicode Collation Algorithm (UCA) 是 Unicode 规定的如何比较两个字符串大小的算法。
null#
可以将该值设置为比最大位数仍多 1 位。
compound keys#
按照其包含的基本类型进行拼接即可。
DuckDB 源码分析#
DuckDB 代码链接:https://github.com/duckdb/duckdb/tree/main/src/execution/index/art ↗
其他参考:
- 论文
- 《The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases》
- 《SMART: A High-Performance Adaptive Radix Tree for Disaggregated Memory》
- 相关代码
这一章通过阅读 DuckDB 的源码,来看一下 ART 索引的实现。
ART 索引的相关实现都在 art.cpp 和 art.hpp,我们主要关注 Insert 和 Find,其他函数留给读者自行了解。
Insert#
bool ART::Insert(Node &node, const ARTKey &key, idx_t depth, const row_t &row_id) {
if (!node.IsSet()) {
// node is currently empty, create a leaf here with the key
Leaf::New(*this, node, key, depth, row_id);
return true;
}
if (node.DecodeARTNodeType() == NType::LEAF) {
// add a row ID to a leaf, if they have the same key
auto &leaf = Leaf::Get(*this, node);
auto mismatch_position = leaf.prefix.KeyMismatchPosition(*this, key, depth);
// identical equal
if (mismatch_position == leaf.prefix.count && depth + leaf.prefix.count == key.len) {
return InsertToLeaf(node, row_id);
}
// example:
// prefix : hello
// key[depth] : heel;
// mismatch_position = 2
// replace leaf with Node4 and store both leaves in it
auto old_node = node;
auto &new_n4 = Node4::New(*this, node);
// new prefix
// new_n4's prefix is he
new_n4.prefix.Initialize(*this, key, depth, mismatch_position);
// old_node's prefix change to llo
auto key_byte = old_node.GetPrefix(*this).Reduce(*this, mismatch_position);
// add child
Node4::InsertChild(*this, node, key_byte, old_node);
Node leaf_node;
Leaf::New(*this, leaf_node, key, depth + mismatch_position + 1, row_id);
// add child
Node4::InsertChild(*this, node, key[depth + mismatch_position], leaf_node);
return true;
}
// handle prefix of inner node
auto &old_node_prefix = node.GetPrefix(*this);
if (old_node_prefix.count) {
auto mismatch_position = old_node_prefix.KeyMismatchPosition(*this, key, depth);
if (mismatch_position != old_node_prefix.count) {
// prefix differs, create new node
auto old_node = node;
auto &new_n4 = Node4::New(*this, node);
new_n4.prefix.Initialize(*this, key, depth, mismatch_position);
auto key_byte = old_node_prefix.Reduce(*this, mismatch_position);
Node4::InsertChild(*this, node, key_byte, old_node);
Node leaf_node;
Leaf::New(*this, leaf_node, key, depth + mismatch_position + 1, row_id);
Node4::InsertChild(*this, node, key[depth + mismatch_position], leaf_node);
return true;
}
depth += node.GetPrefix(*this).count;
}
// recurse
D_ASSERT(depth < key.len);
auto child = node.GetChild(*this, key[depth]);
if (child) {
bool success = Insert(*child, key, depth + 1, row_id);
node.ReplaceChild(*this, key[depth], *child);
return success;
}
// insert at position
Node leaf_node;
Leaf::New(*this, leaf_node, key, depth + 1, row_id);
Node::InsertChild(*this, node, key[depth], leaf_node);
return true;
}参数含义:
node即为当前要进行插入的节点key即为要插入的 keydepth:即当前已经处理到 key 的第几个 byte,举个例子,key 为hello,depth 为 3,那么说明he已经保存在了 node 的祖先节点中,我们当前要处理的是lrow_id即为 key 对应的 value 值
bool ART::Insert(Node &node, const ARTKey &key, idx_t depth, const row_t &row_id) {
if (!node.IsSet()) {
// node is currently empty, create a leaf here with the key
Leaf::New(*this, node, key, depth, row_id);
return true;
}
}如果当前节点为空,那么直接设置该节点为叶节点,并且将 row_id 进行保存,注意这里我们会使用 lazy-expansion,即将 key 剩余未处理的字符全部保存在叶节点中。
bool ART::Insert(Node &node, const ARTKey &key, idx_t depth, const row_t &row_id) {
// .... skip
if (node.DecodeARTNodeType() == NType::LEAF) {
// add a row ID to a leaf, if they have the same key
auto &leaf = Leaf::Get(*this, node);
auto mismatch_position = leaf.prefix.KeyMismatchPosition(*this, key, depth);
// identical equal
if (mismatch_position == leaf.prefix.count && depth + leaf.prefix.count == key.len) {
return InsertToLeaf(node, row_id);
}
// example:
// prefix : hello
// key[depth] : heel;
// mismatch_position = 2
// replace leaf with Node4 and store both leaves in it
auto old_node = node;
auto &new_n4 = Node4::New(*this, node);
// new prefix
// new_n4's prefix is he
new_n4.prefix.Initialize(*this, key, depth, mismatch_position);
// old_node's prefix change to llo
auto key_byte = old_node.GetPrefix(*this).Reduce(*this, mismatch_position);
// add child
Node4::InsertChild(*this, node, key_byte, old_node);
Node leaf_node;
Leaf::New(*this, leaf_node, key, depth + mismatch_position + 1, row_id);
// add child
Node4::InsertChild(*this, node, key[depth + mismatch_position], leaf_node);
return true;
}
//skip....
}如果当前遇到的是叶节点,同时 key 完全相同,那么我们可以直接将 row_id 插入叶节点中。不然的话,我们需要将叶节点变成内部节点,同时将不同的部分作为该内部节点的叶节点,如下图所示。
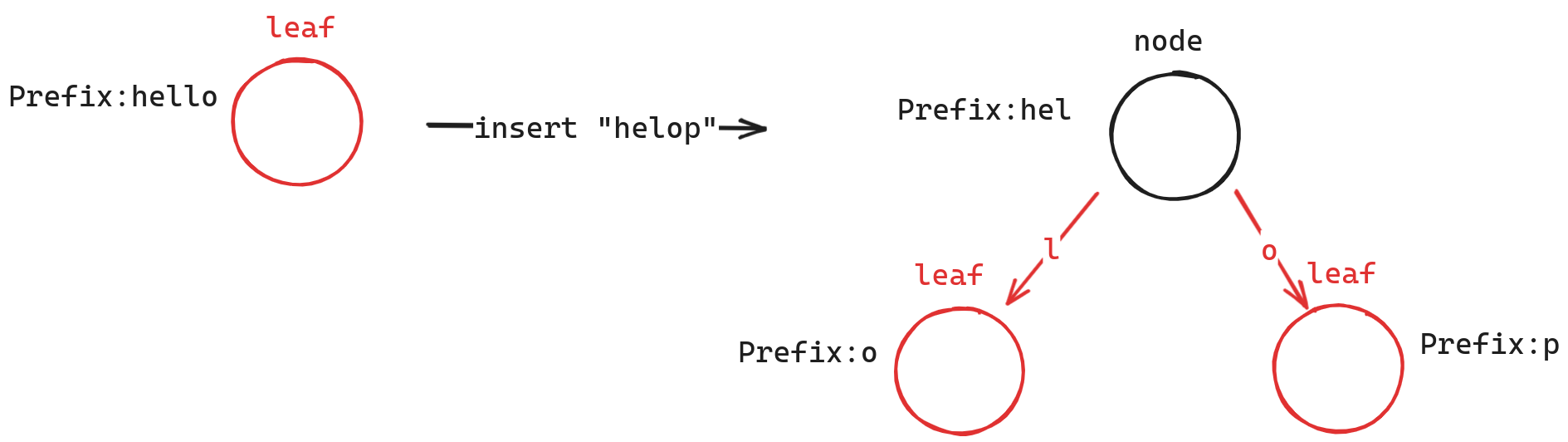
bool ART::Insert(Node &node, const ARTKey &key, idx_t depth, const row_t &row_id) {
// skip ....
// handle prefix of inner node
auto &old_node_prefix = node.GetPrefix(*this);
if (old_node_prefix.count) {
auto mismatch_position = old_node_prefix.KeyMismatchPosition(*this, key, depth);
if (mismatch_position != old_node_prefix.count) {
// prefix differs, create new node
auto old_node = node;
auto &new_n4 = Node4::New(*this, node);
new_n4.prefix.Initialize(*this, key, depth, mismatch_position);
auto key_byte = old_node_prefix.Reduce(*this, mismatch_position);
Node4::InsertChild(*this, node, key_byte, old_node);
Node leaf_node;
Leaf::New(*this, leaf_node, key, depth + mismatch_position + 1, row_id);
Node4::InsertChild(*this, node, key[depth + mismatch_position], leaf_node);
return true;
}
depth += node.GetPrefix(*this).count;
}
// recurse
D_ASSERT(depth < key.len);
auto child = node.GetChild(*this, key[depth]);
if (child) {
bool success = Insert(*child, key, depth + 1, row_id);
node.ReplaceChild(*this, key[depth], *child);
return success;
}
// insert at position
Node leaf_node;
Leaf::New(*this, leaf_node, key, depth + 1, row_id);
Node::InsertChild(*this, node, key[depth], leaf_node);
return true;
}如果是内部节点,那我们需要讨论:
- 如果前缀完全相同,即 “hello” 和 “hellopxxx”。那么我们仅需要找出子节点进行插入即可

- 如果前缀有不同之处,即 “hello” 和 “helopxxx”。那么我们需要创建一个新的节点,并将两个节点作为子节点进行插入
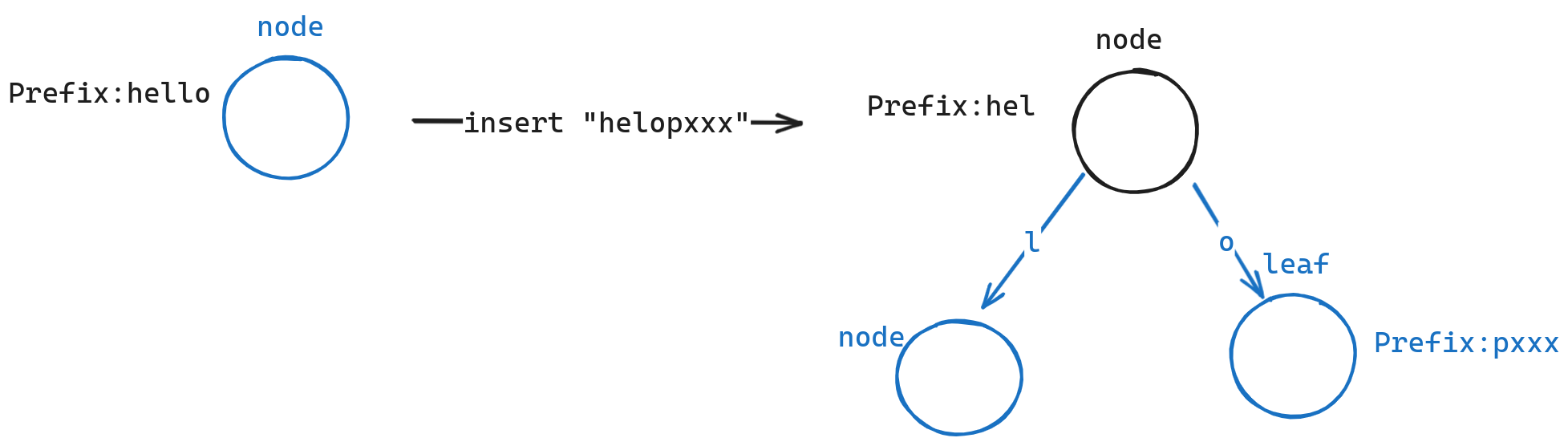
可以看到我们只需要在内部节点和叶节点中支持存储多个字符后,便天然支持上述的优化方案。
Find#
Node ART::Lookup(Node node, const ARTKey &key, idx_t depth) {
while (node.IsSet()) {
if (node.DecodeARTNodeType() == NType::LEAF) {
auto &leaf = Leaf::Get(*this, node);
// check if leaf contains key
for (idx_t i = 0; i < leaf.prefix.count; i++) {
if (leaf.prefix.GetByte(*this, i) != key[i + depth]) {
return Node();
}
}
return node;
}
auto &node_prefix = node.GetPrefix(*this);
if (node_prefix.count) {
for (idx_t pos = 0; pos < node_prefix.count; pos++) {
if (key[depth + pos] != node_prefix.GetByte(*this, pos)) {
// prefix mismatch, subtree of node does not contain key
return Node();
}
}
depth += node_prefix.count;
}
// prefix matches key, but no child at byte, does not contain key
auto child = node.GetChild(*this, key[depth]);
if (!child) {
return Node();
}
// recurse into child
node = *child;
D_ASSERT(node.IsSet());
depth++;
}
return Node();
}查找的代码相对来说比较简单:
- 查找到了
Leaf节点,检查Prefix是否匹配,如果不匹配说明 Key 不存在,若匹配直接返回该叶节点即可 - 查找到了
内部节点,检查Prefix是否匹配,如果不匹配说明 Key 不存在,若匹配则继续搜索对应的子节点
最后#
本文介绍了 DuckDB 的 ART 索引,可以看到尽管 ART 索引的树会比 B+ 树更高,因此如果是面向磁盘的情况下,B+ 树会比 ART 索引优势更大,但是如果是内存索引的情况下,ART 索引更加紧凑,同时它的渐进时间复杂度仅与 key 的长度有关,可能也更加 Cache friendly?它的节点相较于 B+ 树更加的小,可以更多的保存在 Cache 中。从论文中的实验来看,它的性能会比 B+ 树更好。相较于 Hash table,它支持范围查询。基于此,DuckDB 将 ART 索引作为其的主要索引。