
✍️ C++ 11 新特性大全:https://zhuanlan.zhihu.com/p/139515439 ↗
1. GCC 编译流程|编译与汇编的区别#
一段高级语言代码经过四个阶段的处理形成可执行的目标二进制代码。
预处理器→编译器→汇编器→链接器:最难理解的是编译与汇编的区别。
这里采用《深入理解计算机系统》的说法。
预处理阶段:预处理阶段主要处理 #include 指令、宏替换、条件编译等,生成 .i 文件。
- 展开头文件:将
#include指定的文件插入到源代码中 - 宏替换:替换所有
#define定义的宏 - 条件编译:根据预处理指令(如
#ifdef)选择性地编译代码 - 去除注释:删除源代码中的注释内容
写好的高级语言的程序文本比如
hello.c,预处理器根据#开头的命令,修改原始的程序,如#include<stdio.h>将把系统中的头文件插入到程序文本中,通常是以.i结尾的文件。
gcc -E source.c -o source.i编译阶段:编译阶段对源代码进行语法语义检查,生成汇编代码,产生 .s 文件。
编译器将
hello.i文件翻译成汇编语言程序hello.s,不同的高级语言翻译的汇编语言相同。
gcc -S source.i -o source.s汇编阶段:汇编阶段将汇编代码翻译成机器码(机器可识别的目标代码),生成 .o 目标文件。
汇编器将汇编代码
hello.s翻译成机器语言指令。把这些指令打包成可重定位目标程序,即.o文件。hello.o是一个二进制文件,它的字节码是机器语言指令,不再是字符,前面两个阶段都还有字符。
gcc -c source.s -o source.o链接阶段: 链接阶段将多个目标文件和库文件链接在一起,生成最终的可执行文件,链接过程还可能会调用外部的动态或静态库。
比如
hello程序调用printf程序,它是每个 C 编译器都会提供的标准库 C 的函数。这个函数存在于一个名叫printf.o的单独编译好的目标文件中,这个文件将以某种方式合并到hello.o中。链接器就负责这种合并,得到的是可执行目标文件。
gcc source.o -o executable关于编译优化:
GCC 和 G++ 提供了多种优化选项,开发者可以根据项目需求选择合适的优化级别
| 优化级别 | 描述 |
|---|---|
-O0 | 无优化(默认) |
-O1 | 基本优化 |
-O2 | 在不显著增加编译时间的前提下进行进一步优化 |
-O3 | 启用所有优化选项,可能导致代码体积增加 |
-Os | 优化代码体积,适用于存储受限的设备 |
2. C 和 C++ 区别(函数/类/struct/class)#
首先,C 和 C++ 在基本语句上没有过大的区别。
C++ 有新增的语法和关键字:
- 语法的区别有头文件的不同和命名空间的不同,C++ 允许我们自己定义自己的空间,C 中不可以。
- 关键字方面比如 C++ 与 C 动态管理内存的方式不同,C++ 中在
malloc和free的基础上增加了new和delete,而且 C++ 中在指针的基础上增加了引用的概念,关键字例如 C++中还增加了auto,explicit体现显示转换和隐式转换上的概念要求,还有dynamic_cast增加类型安全方面的内容。
函数方面 C++ 中有重载和虚函数的概念:
- C++ 支持函数重载而 C 不支持,是因为 C++ 函数的名字修饰与 C 不同,C++ 函数名字的修饰会将参数加在后面,例如,
int func(int, double)经过名字修饰之后会变成_func_int_double,而 C 中则会变成_func,所以 C++ 中会支持不同参数调用不同函数。 - C++ 还有虚函数概念,用以实现多态。
类方面,C 的 struct 和 C++ 的类也有很大不同:
- C++ 中的 struct 不仅可以有成员变量还可以成员函数,而且对于 struct 增加了权限访问的概念,struct 的默认成员访问权限和默认继承权限都是
public,C++ 中除了struct还有class表示类,struct 和 class 还有一点不同在于 class 的默认成员访问权限和默认继承权限都是private。
C++ 中增加了模板来重用代码,提供了更加强大的 STL 标准库。
最后补充一点就是 C 是一种结构化的语言,重点在于算法和数据结构。C 程序的设计首先考虑的是如何通过一个代码,一个过程对输入进行运算处理输出。而 C++ 首先考虑的是如何构造一个对象模型,让这个模型能够契合与之对应的问题领域,这样就能通过获取对象的状态信息得到输出。
C 的 struct 更适合看成是一个数据结构的实现体,而 C++ 的 class 更适合看成是一个对象的实现体。
3. C++ 和 JAVA 区别(语言特性、垃圾回收、应用场景等)#
本人 C++ 和 Java 都有染指。
指针:Java 让程序员没法找到指针来直接访问内存,没有指针的概念,并且有自动内存管理功能,从而有效地防止了 C++ 语言中的指针操作失误的影响。但并非 Java 中没有指针,Java 虚拟机内部中还是使用了指针,保证了 Java 程序的安全性。
多重继承:C++ 支持多重继承但 Java 不支持,但支持一个类继承多个接口,实现 C++ 中多重继承的功能,又避免了 C++ 的多重继承带来的不便。
数据类型和类:Java 是完全面向对象的语言,所有的函数和变量必须是类的一部分。除了基本数据类型之外,其余的都作为类对象,对象将数据和方法结合起来,把他们封装在类中,这样每个对象都可以实现自己的特点和行为。Java 中取消了 C++ 中的 struct 和 union。
自动内存管理:Java 程序中所有对象都是用 new 操作符建立在内存堆栈上,Java 自动进行无用内存回收操作,不需要程序员进行手动删除。而 C++ 中必须由程序员释放内存资源,增加了程序设计者的负担。Java 中当一个对象不再被使用时,无用内存回收器将给他们加上标签,Java 里无用内存回收程序是以线程方式在后台运行,利用空闲时间工作来删除。
Java 不支持操作符重载,操作符重载是 C++ 的突出特性。
Java 不支持预处理功能,C++ 在编译过程中都有一个预编译阶段,Java 没有预处理器,但它提供了 import,与 C++ 预处理器具有类似功能。
类型转换:C++ 中有数据类型隐含转换的机制,Java 中需要显式强制类型转换。
字符串:C++ 中字符串是以 NULL 终止符代表字符串的结束,而 Java 的字符串是用类对象(string 和 stringBuffer)来实现的。
Java 中不提供 goto 语句,虽然指定 goto 为关键字,但不支持使用它。
Java 的异常机制用于捕获例外事件,增强系统容错能力。
4. C++ 中 const 和 static 关键字的作用#
static#
static 作用:控制变量的存储方式和可见性。
1️⃣ 局部静态变量#
一般情况下,对于局部变量在程序中是存放在栈区的,并且局部的生命周期在包含语句块执行结束时便也结束了。但是如果用 static 关键字修饰,该变量会存放在静态数据区,作用域仍为局部作用域,但是当局部静态变量离开作用域后,并没有销毁,而是仍然驻留在内存当中,只不过我们不能再对它进行访问,直到该函数再次被调用,并且值不变。
2️⃣ 全局静态变量#
即 static 限制了全局变量的作用域(本文件)
对于一个全局变量,它既可以在本文件中被访问到,也可以在同一个工程其它源文件被访问(添加 extern 进行声明即可);而使用 static 对全局变量进行修饰改变了其作用域范围,由原来整个工程可见变成了本文件可见,同时也是存放在静态数据区,在整个程序运行期间一直存在。
3️⃣ 静态函数#
函数的定义和声明在默认情况下都是 extern 的,但静态函数只是在声明它的文件当中可见(与全局静态变量类似)
4️⃣ 类的静态成员/函数#
在类中,静态成员可以实现多个对象之间的数据共享,并且使用静态数据成员还不会破坏隐藏的原则,即保证了安全性。因此静态成员/函数是类中所有对象共享的成员/函数,而不是某个对象的成员/函数。
- 在模块内的 static 全局变量可以被模块内所有函数访问,但不能被模块外其它函数访问;
- 在类中的 static 成员变量属于整个类所拥有,对类的所有对象只有一份拷⻉;
- 在类中的 static 成员函数属于整个类所拥有,这个函数不接收 this 指针,因而只能访问类的 static 成员变量;
- static 类对象必须要在类外进行初始化,static 修饰的变量先于对象存在,所以 static 修饰的变量要在类外初始化;
- 由于 static 修饰的类成员属于类,不属于对象,因此 static 类成员函数是没有
this指针,this 指针是指向本对象的指针,正因为没有 this 指针,所以 static 类成员函数不能访问非 static 的类成员,只能访问 static 修饰的类成员; - static 成员函数不能被
virtual修饰,static 成员不属于任何对象或实例,所以加上 virtual 没有任何实际意义;静态成员函数没有 this 指针,虚函数的实现是为每一个对象分配一个 vptr 指针,而 vptr 是通过 this 指针调用的,所以不能为 virtual;虚函数的调用关系,this->vptr->ctable->virtual function。
const#
1️⃣ const 修饰基本数据类型#
修饰符 const 可以用在类型说明符前,也可以在类型说明符后,结果都是一样的,使用这些常量时,只要不改变这些常量的值即可。
2️⃣ const 修饰指针变量和引用变量#
引用同理
如果 const 位于 const T* 左侧,则 const 就是用来修饰指针所指向的变量,即指针指向为常量。
如果 const 位于 T* const 右侧,则 const 就是修饰指针本身,即指针本身是常量。
3️⃣ const 应用到函数中#
- 作为参数的 const 修饰符:调用函数时,用相应的变量初始化 const 常量,则在函数体中,按照 const 所修饰的部分进行常量化,保护了原对象的属性。
- 作为函数返回值的 const 修饰符:声明了返回值后,它意味着这个返回值是一个常量,不能被修改。
注意:参数 const 通常用于参数为指针或引用的情况。
4️⃣ const 在类中的用法#
- const 成员变量:只在某个对象生命周期内是常量,而对于整个类而言是可以改变的(因为类可以创建多个对象,不同对象其 const 数据成员值可以不同,所以不能在类的声明中初始化 const 数据成员,因为类对象在没有创建的时候,编译器不知道 const 数据成员的值是什么,const 数据成员的初始化只能在类的构造函数初始化列表中进行)
- const 成员函数:防止成员函数修改对象的内容,要注意,const 和 static 对于成员函数来说是不能同时使用的,因为 static 关键字修饰静态成员函数不含有 this 指针,即不能实例化,const 成员函数又必须具体到某一个函数。
补充:
- const 成员函数如果实在想修改某个变量,可以使用
mutable进行修饰; - 成员变量中如果想建立在整个类中都恒定的常量,应该用类中的
枚举常量来实现或者static const。
5️⃣ const 修饰类对象、定义常量函数#
const 常量对象只能调用 const 常量函数,非 const 成员函数都不能调用。
原因:对象调用成员函数时,在形参列表的最前面加一个形参 this,但这是隐式的。this 指针是默认指向调用函数的当前对象的,所以很自然,this 是一个常量指针 test * const,因为不可以修改 this 指针代表的地址。但当成员函数的参数列表后加了 const 关键字(void print() const;),此成员函数为常量成员函数,此时它的隐式 this 形参为 const test * const,表示指向常量对象的常量指针,即不可以通过 this 指针来改变指向对象的值。
非常量对象可以调用类中的 const 成员函数,也可以调用非 const 成员函数。
#include <iostream>
class Test {
public:
Test(int val) : value(val) {}
// 常量成员函数
void print() const {
std::cout << "Value: " << value << std::endl;
}
// 非常量成员函数
void setValue(int val) {
value = val;
}
private:
int value;
};
int main() {
const Test obj(10);
obj.print(); // OK,调用常量成员函数
// obj.setValue(20); // 错误,`const`对象不能调用非常量成员函数
return 0;
}⚠️ 注意区别 int print() const; 和 const int print();:
- 前者为常量成员函数,
const位于函数声明的末尾,只能由 const 常量对象来调用该 const 常量函数。 - 后者为普通成员函数,但是返回值为
const int(注意不能用 const 修饰 void,即const void print()会编译错误,所以这里用了int)
5. 说一说 C++ 中四种 cast 转换#
C++ 中四种类型转换是:static_cast、dynamic_cast、const_cast、reinterpret_cast
const_cast#
用于将 const 变量转为非 const 变量:常量指针转换为⾮常量指针,并且仍然指向原来的对象;常量引⽤被转换为⾮常量引⽤,并且仍然指向原来的对象。const_cast 去掉类型的 const 或 volatile 属性。
static_cast#
用于各种隐式转换,但是没有运行时类型检查来保证转换的安全性。
比如非 const 转 const,void* 转指针等,static_cast 还可以用于多态向上转换(如 Derived 转 Base,即子类转基类)
- 进行向上转换(把派生类指针或引用转换为基类)是安全的
- 进行向下转换(把基类指针或引用转换为派生类),由于没有运行时类型检查,所以是不安全的
// Base 是 Derived 的基类/父类
int main() {
Derived* d;
Base* base = static_cast<Base*>(d); // 向上类型转换
base->show();
return 0;
}dynamic_cast#
在进行向下转换时,dynamic_cast 具有类型检查(信息在虚函数中)的功能,比 static_cast 更安全。
只能用于含有虚函数的类,用于类层次间的向上和向下转换(基类转子类),只能转指针或引用,向下转换时:
- 对于指针,转换失败则返回
nullptr - 对于引用,转换失败则抛异常
int main() {
Base* base = new Derived; // 不使用 static_cast 也可以隐式向上转换
Derived* derive = dynamic_cast<Derived*>(base); // 向下类型转换,使用 dynamic_cast
if (derive) {
derive->show();
} else {
std::cout << "Conversion failed!" << std::endl;
}
delete base;
return 0;
}reinterpret_cast#
几乎什么都可以转,比如将 int 转指针,可能会出问题,尽量少用。
WARNING:reinterpret_cast 本质上依赖于机器,要想安全地使用 reinterpret_cast 必须对涉及的类型和编译器实现转换的过程都非常了解。
为什么不使用 C 的强制转换?#
C 的强制转换表面上看起来功能强大什么都能转,但是转化不够明确,不能进行错误检查,容易出错。
static_cast 与 dynamic_cast 之间的区别?#
dynamic_cast 和 static_cast 的主要区别在于类型检查的时间点和安全性:
- 类型检查时间点:
static_cast在编译时进行类型检查,而dynamic_cast在运行时进行类型检查。 - 安全性:
static_cast不执行运行时类型检查,因此如果在类层次结构中进行不安全的向下转换,可能导致未定义行为。相反,dynamic_cast会在运行时检查转换的安全性,如果转换不安全,则返回nullptr或抛出异常,提供更高的安全性。
6. C/C++ 的四大内存分区和常量的存储位置#
四大内存分区:栈、堆、静态存储区(全局变量 + 静态变量 + 常量)和代码区。
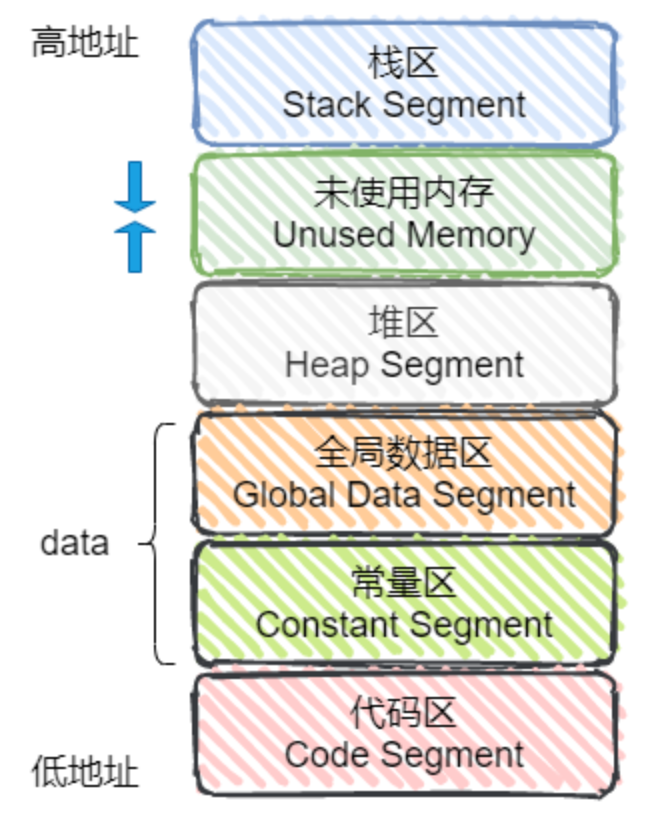
1️⃣ 栈区#
由系统进行内存的管理。主要存放函数的参数以及局部变量。在函数完成执行,系统自动释放栈区内存,不需要用户管理,整个程序的栈区大小可以在编译器中由用户自行设定,VS 中默认的栈区大小为 1M,可以通过 VS 手动更改栈的大小。64 bits 的 Linux 默认栈大小为 10MB,可通过 ulimit -s 临时修改,可通过 ulimit -a 查看。
2️⃣ 堆区#
由程序员手动申请,手动释放,若不手动释放,程序结束后由系统回收,生命周期是整个程序运行期间。使用 malloc 或者 new 进行堆的申请,堆的总大小为机器的虚拟内存的大小。
说明:new 操作符本质上是使用了 malloc 进行内存的申请,new 和 malloc 的区别如下:
malloc是 C 语言中的函数,而new是 C++ 中的操作符。malloc申请之后返回的类型是void*,而new返回的指针带有类型。malloc只负责内存的分配而不会调用类的构造函数,而new不仅会分配内存,而且会自动调用类的构造函数。
堆和栈的区别#
申请方式不同:
- 栈是系统自动分配
- 堆是自己申请和释放的
申请大小限制不同:
- 栈空间默认 10 MB;栈顶和栈底是之前预设好的,栈是向栈底扩展,大小固定,可以通过
ulimit -a查看,由ulimit -s修改 - 堆区一般是 1G~4G;堆向高地址扩展,是不连续的内存区域,大小可以灵活调整
申请效率不同:
- 栈由系统分配,速度快,不会有碎片
- 堆由程序员分配,速度慢,且会有碎片
栈快还是堆快?#
毫无疑问是栈快一点。
因为操作系统会在底层对栈提供支持,会分配专门的寄存器存放栈的地址,栈的入栈出栈操作也十分简单,并且有专门的指令执行,所以栈的效率比较高也比较快。
而堆的操作是由 C/C++ 函数库提供的,在分配堆内存的时候需要一定的算法寻找合适大小的内存。并且获取堆的内容需要两次访问,第一次访问指针,第二次根据指针保存的地址访问内存,因此堆比较慢。
3️⃣ 静态存储区#
静态存储区 = 全局数据区 + 常量区
全局数据区:全局变量 + 静态变量,该区域会被自动初始化
常量区:存放常量,不允许修改
静态存储区内的变量在程序编译阶段已经分配好内存空间并初始化。这块内存在程序的整个运行期间都存在,它主要存放 static 静态变量、全局变量和 const 常量。
区分:
static修饰「局部变量」在静态存储区中;const修饰「局部变量」则是在栈区中。
注意:
- 这里不区分初始化和未初始化的数据区,是因为静态存储区内的变量若不显示初始化,则编译器会自动以默认的方式进行初始化,即静态存储区内不存在未初始化的变量。
- 静态存储区内的常量分为常变量和字符串常量,一经初始化,不可修改。静态存储内的常变量是全局变量,与局部常变量不同,区别在于局部常变量存放于栈,实际可间接通过指针或者引用进行修改,而全局常变量存放于静态常量区则不可以间接修改。
- 字符串常量存储在静态存储区的常量区,字符串常量的名称即为它本身,属于常变量。
- 数据区的具体划分,有利于我们对于变量类型的理解。不同类型的变量存放的区域不同。后面将以实例代码说明这四种数据区中具体对应的变量。
4️⃣ 代码区#
存放程序体的二进制代码,比如我们写的函数都是在代码区。
int a = 0;//静态全局变量区
char *p1; //编译器默认初始化为NULL
void main()
{
int b; //栈
char s[] = "abc";//栈
char *p2 = "123456";//123456在字符串常量区,p2在栈上
static int c =0; //c在静态变量区,0为文字常量,在代码区
const int d=0; //栈
static const int d;//静态常量区
p1 = (char *)malloc(10);//分配得来得10字节在堆区。
strcpy(p1, "123456"); //123456放在字符串常量区,编译器可能会将它与p2所指向的"123456"优化成一个地方
}7a. C++ 中 class 的大小由哪些因素决定?#
在 C++ 中,类的大小由多个因素决定,主要包括:
- 普通成员变量:类中定义的非静态成员变量会直接影响类的大小。每个成员变量都会占用相应的内存空间。
- 虚函数:如果类包含虚函数,编译器会为该类添加一个虚函数表(vtable),并在每个对象中添加一个指向该表的指针(vptr),这会增加每个对象的大小。
- 继承:类的继承关系也会影响其大小。
- 单一继承:派生类会继承基类的成员变量和成员函数,但不会直接增加对象的大小。
- 多重继承:派生类继承多个基类时,可能会导致对象中包含多个基类的子对象,从而增加对象的大小。
- 虚拟继承:为了解决菱形继承问题,编译器可能会在派生类中引入虚拟基类指针,增加对象的大小。
- 内存对齐:编译器通常会对类的成员变量进行内存对齐,以提高访问效率。这可能导致类的实际大小大于成员变量总和。
- 分配内存的顺序是按照声明的顺序。
- 每个变量相对于起始位置的偏移量必须是该变量类型大小的整数倍,不是整数倍空出内存,直到偏移量是整数倍为止。
- 最后整个结构体的大小必须是里面变量类型最大值的整数倍。
⚠️ 需要注意的是,类的构造函数、析构函数、静态成员变量、静态成员函数和普通成员函数不会直接影响类的大小。
- 构造函数和析构函数:
- 构造函数和析构函数是特殊的成员函数,用于对象的初始化和销毁。
- 它们的存在不会增加类的实例大小,因为它们在对象创建和销毁时被调用,但并不占用对象的内存空间。
- 静态成员变量:
- 静态成员变量属于类本身,而不是类的实例。
- 它们在类的所有实例之间共享,只有一份存储空间(静态存储区)。
- 静态成员函数:
- 静态成员函数也属于类本身,而不是类的实例。
- 它们在类的所有实例之间共享,只有一份存储空间。
- 普通成员函数:
- 普通成员函数是类的成员,但普通成员函数的代码通常存储在程序的代码段中,而不是对象的内存中。
- 因此,普通成员函数不会影响类的实例大小。
7b. [7a 类似问题] C++ 的对象存储空间是怎么安排的?#
C++ 中对象的存储取决于:
- 对象的类型(普通对象、继承对象、虚函数表等)
- 存储方式(栈、堆、静态存储区)
- 对齐方式
具体来说:
1️⃣ 普通对象
(1)非静态成员变量
- 普通对象的非静态成员变量按照 声明顺序 在内存中存储。
- 编译器会根据 CPU 架构和优化需求进行 内存对齐(alignment),可能会插入填充字节(padding)。
- 类的大小通常是 最大成员类型的对齐倍数。
示例:
#include <iostream>
struct A {
char c; // 1 字节
int i; // 4 字节
};
int main() {
std::cout << sizeof(A) << std::endl; // 输出可能是 8(对齐)
return 0;
}内存布局(假设 4 字节对齐):
| c (1B) | padding (3B) | i (4B) |(2)静态成员变量:不属于对象本身,放在静态存储区,在程序启动时分配。
2️⃣ 继承
(1)非虚继承:没有 virtual
派生类对象包括基类的成员变量,存储顺序是:
- 基类子成员
- 派生类新增成员
- 对齐填充
struct Base {
int a;
};
struct Derived : public Base {
char b;
};
int main() {
std::cout << sizeof(Derived) << std::endl; // 可能是 8(对齐)
}
内存分布:| Base::a (4B) | Derived::b (1B) | padding (3B) |(2)虚继承:基类含有 virtual 方法
- **虚基类 ↗**存储方式不同,编译器会创建虚基类指针
vptr以及虚基类表vtable来管理它 - 可能会多一个指向虚基类表的指针,因此对象的大小会变大
struct Base {
int a;
virtual void func() {} // 引入虚表
};
struct Derived : public Base {
char b;
};
int main() {
std::cout << sizeof(Derived) << std::endl; // 可能是 16(虚表指针 + 对齐)
}
// 假设指针 8 字节
| vptr (8B) | Base::a (4B) | padding (3B) | Derived::b (1B) |3️⃣ 多重继承
- 非虚多重继承:派生类按继承顺序依次存储多个基类的成员变量。
- 虚多重继承:对象中会存储多个虚表指针,可能引入 虚基类偏移表。
struct A {
int a;
};
struct B {
double b;
};
struct C : public A, public B {
char c;
};
int main() {
std::cout << sizeof(C) << std::endl; // 可能是 24(对齐 + 多继承)
}
| A::a (4B) | padding (4B) | B::b (8B) | C::c (1B) | padding (7B) |4️⃣ 对象存储方式
- 栈上对象:普通局部对象,生命周期受到作用域控制
- 堆上对象:使用
new关键词分配的对象存储在堆区,需要手动delete - 静态存储区:
static变量存储在静态存储区
5️⃣ 虚函数和 vtable 虚表
- 如果类中有 虚函数,编译器会为该类生成 虚表(vtable),并在对象中存储 虚指针(vptr),指向该虚表。
- 虚表存储在静态区,而 vptr 存储在对象头部(通常是对象的第一个成员)。
- vptr 使得多态调用能够动态绑定。
⚠️ 虚指针存储在对象头部;虚表存储在静态存储区。
8. new/delete 和 malloc/free 有什么区别和联系?#
更多内容(讲得很好):C++ 种内存管理之 new/delete ↗
联系:都可以用来在堆上分配和回收空间,new/delete 是操作符,malloc/free 是库函数。
执行 new 实际上执行两个过程:
- 调用
malloc分配未初始化的内存空间 - 使用对象的构造函数对空间进行初始化,并返回空间的首地址
执行 delete 实际上也有两个过程:
- 使用析构函数对对象进行析构
- 调用
free释放指针所指向空间的内存
二者区别:new 得到的是经过初始化的空间,而 malloc 得到的是未初始化的空间,所以 new 是 new 一个类型,而 malloc 则是 malloc 一个字节长度的空间。delete 和 free 同理,delete 不仅释放空间还析构对象,delete 一个类型,free 一个字节长度的空间。
对象的自动删除#
通过之前的分析我们知道,new关键字创建对象并非一步完成,而是通过先分配未初始化内存和调用构造函数初始化两步实现的。那么在这个过程中如果是第一步出错,那么内存分配失败不会调用构造函数,这是没有问题的。但是如果第一步已经完成在堆中已经成功分配了内存之后,在第二步调用构造函数时异常导致创建对象失败(抛出 std::bad_alloc),那么就应该将第一步中申请的内存释放。C++中规定,如果一个对象无法完全构造,那么这个对象就是一个无效对象,也不会调用析构函数。因此为了保证对象的完整性,当通过 new 分配的堆内存对象在构造函数执行过程中出现异常时,就会停止构造函数的执行并且自动调用对应的 delete 运算符来对已经分配好的对内存执行销毁处理,即对象的自动删除技术。
🔥 为什么有了 malloc/free 还需要 new/delete#
因为对于非内部数据类型而言,光用 malloc/free 无法满足动态对象的要求。对象在创建的同时需要自动执行构造函数,对象在消亡以前要自动执行析构函数。由于 malloc/free 是库函数而不是操作符,不在编译器控制权限之内,不能够把执行的构造函数和析构函数的任务强加于 malloc/free,所以在 C++ 中需要一个能完成动态内存分配和初始化工作的运算符 new,以及一个能完成清理和释放内存工作的运算符 delete。而且在对非基本数据类型的对象使用的时候,对象创建的时候还需要执行构造函数,销毁的时候要执行析构函数。而 malloc/free 是库函数,是已经编译的代码,所以不能把构造函数和析构函数的功能强加给 malloc/free,所以 new/delete 是必不可少的。
既然 new/delete 的功能完全覆盖了 malloc/free,为什么 C++ 不把 malloc/free 淘汰出局呢?这是因为 C++ 程序经常要调用 C 函数,而 C 程序只能用 malloc/free 管理动态内存。
🔥 malloc 与 free 的实现原理(brk()、mmap())#
1、在标准 C 库中,提供了 malloc/free 函数分配释放内存,这两个函数底层是由 brk、mmap、munmap 这些系统调用实现的;
brk是将「堆顶」指针向高地址移动,获得新的内存空间;mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
2、malloc 分配阈值
- malloc 小于 128k 的内存,使用
brk分配内存,将「堆顶」指针往高地址推; - malloc 大于 128k 的内存,使用
mmap分配内存,在堆和栈之间找一块空闲内存分配;
brk 分配的内存需要等到高地址内存释放以后才能释放,而 mmap 分配的内存可以单独释放。当最高地址空间的空闲内存超过 128K(可由 M_TRIM_THRESHOLD 选项调节)时,执行内存紧缩操作(trim)。在上一个步骤 free 的时候,发现最高地址空闲内存超过 128K,于是内存紧缩。
3、空闲地址链表:malloc 是从堆里面申请内存,也就是说函数返回的指针是指向堆里面的一块内存。操作系统中有一个记录空闲内存地址的链表。当操作系统收到程序的申请时,就会遍历该链表,然后就寻找第一个空间大于所申请空间的堆结点,然后就将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
🔥 被 free 回收的内存是立即返回给操作系统吗?#
更详细的内容:
不一定。被 free 的内存不一定会立刻返回给操作系统,具体行为取决于操作系统的内存管理机制以及 C 语言运行时库(如 glibc)的实现方式。
对于 「malloc 申请的内存,free 释放内存会归还给操作系统吗?」这个问题,我们可以做个总结:
- malloc 通过
brk()方式申请的内存,free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用; - malloc 通过
mmap()方式申请的内存,free 释放内存的时候,会把内存归还给操作系统,内存得到真正的释放。
什么场景下 malloc() 会通过 brk() 分配内存?又是什么场景下通过 mmap() 分配内存?
malloc() 源码里默认定义了一个阈值:
- 如果用户分配的内存小于 128 KB,则通过 brk() 申请内存;
- 如果用户分配的内存大于 128 KB,则通过 mmap() 申请内存;
注意,不同的 glibc 版本定义的阈值也是不同的。
1. 内存释放流程#
当你在 C/C++ 中使用 free(ptr) 释放一块内存时:
- 内存被标记为“空闲”,表示这块内存可以被后续的
malloc或calloc重用。 - 但它通常不会立即归还给操作系统,而是由内存分配器(如 glibc 的
ptmalloc)保留在用户进程中,用于后续分配。
2. 什么时候会真正返回给操作系统?#
- 如果释放的是堆顶的内存块(即堆的末端),且满足一定条件,glibc 可能会调用
brk或mmap对应的释放机制(如munmap)来将这部分内存返回给操作系统。 - 使用
mmap分配的大块内存(通常大于一定阈值,比如 128KB),在被free时通常会直接使用munmap归还给操作系统。
3. glibc 的行为(以 Linux 为例)#
glibc 的 malloc 有一套复杂的内存池机制,常见策略:
- 小块内存来自内部的 arena,
free后不会归还操作系统,而是缓存起来以便重用。 - 大块内存通过
mmap分配,free后可能会立即调用munmap释放给系统。
4. 查看内存是否释放#
可以使用工具如:
top或htop查看内存使用趋势valgrind检查内存泄漏pmap查看进程的内存映射情况mallinfo()(旧)或malloc_info()(新)来观察 glibc 的内存使用状况
🔥 malloc、realloc、calloc 的区别?#
1️⃣ malloc 函数
void* malloc(unsigned int num_size);
int *p = malloc(20*sizeof(int)); // 申请 20 个 int 类型的空间;2️⃣ calloc 函数:省去了人为空间计算;malloc 申请的空间的值是随机初始化的,calloc 申请的空间的值是初始化为 0 的;
void* calloc(size_t n,size_t size);
int *p = calloc(20, sizeof(int));3️⃣ realloc 函数:给动态分配的空间分配额外的空间,用于扩充容量。
void realloc(void *p, size_t new_size);9. 异常/错误处理有几种方法,为什么有些场合要禁用?#
C++ 提供了多种错误处理机制,主要包括:
- 返回码:函数通过返回值指示成功或失败,调用者需要检查返回值以确定操作结果。
- 错误码:使用全局或静态变量存储错误码,调用者需要在每个步骤后检查错误码。
- 异常处理:使用
try、catch和throw关键字捕获和处理异常,提供结构化的错误处理方式。
在某些场合,可能需要禁用异常处理,原因包括:
- 性能要求高的场合:异常处理可能引入性能开销,影响程序的执行效率。
- 嵌入式系统:资源有限,可能不支持异常处理。
- 编译器不支持:某些编译器可能不支持异常处理。
禁用异常处理可以通过编译器选项实现,例如在 Sun Studio 中使用 -features=no%except 来禁用异常处理。
10. C 相关的问题,什么是野指针,有哪些野指针?#
野指针是指向「未初始化」或「已释放内存」的指针,使用野指针会导致未定义行为,常见野指针:
- 未初始化的指针:指针声明后未被初始化,默认值不确定,可能指向任意内存地址
- 悬垂指针:指向已释放内存的指针,释放内存后未将指针置为 NULL,导致指针仍指向已回收的内存地址
- 空指针:指针被初始化为 NULL,但在后续使用前未被赋予有效地址,导致解引用时发生错误
为避免野指针,应该在声明指针时进行初始化,并在释放内存后将指针置为 NULL。
在更多结构化的解决方案中,一种流行的避免悬垂指针的技术是使用智能指针,一个智能指针通常使用引用技术来收回对象。还有些技术包括 tombstones 方法和 locks-and-keys 方法。另一个方法是使用 Boehm 垃圾收集器,一种保守的垃圾收集器,取代 C 和 C++ 中的标准内存分配函数。此法通过禁止内存释放函数来完全消除悬垂指针引发的错误,通过收集垃圾来回收对象。
11. 你平常怎么调试代码,你能想到多少方法?#
调试代码是开发过程中非常重要的一部分,尤其是当出现问题时。调试的方式有很多种,下面是我能想到的常见调试方法:
使用调试器 (Debugger)#
调试器是一种强大的工具,可以让你在程序运行时暂停执行,检查变量的值、调用堆栈等信息,逐行执行代码来找出错误。常见的调试器包括:
- GDB (GNU Debugger):适用于 C/C++ 等语言,通过命令行进行调试。
- Visual Studio Debugger:适用于 Windows 上的 C++ 和 .NET 程序。
- LLDB:用于 macOS 或 Linux 的调试器。
- Xcode Debugger:适用于 macOS 和 iOS 应用的调试器。
使用调试器,你可以:
- 设置断点:暂停程序执行,以检查变量状态和函数调用。
- 逐步执行代码:逐行执行,查看每一行代码的效果。
- 检查栈信息和变量的值:实时查看变量的值、函数调用栈、内存内容等。
例如,使用 GDB 调试 C++ 代码时,可以使用以下命令:
gdb ./your_program启动调试器。break main在main()函数处设置断点。run启动程序执行。step或next逐步执行代码。
插入日志输出 (Logging)#
在代码中添加日志输出是调试程序的常见方法。你可以在代码中插入 printf、std::cout 或日志库(如 log4cpp, spdlog, glog 等)来输出变量值、函数执行状态和程序流程。
常见做法包括:
- 输出函数进入与退出的日志。
- 打印变量值、数据结构的内容。
- 打印程序的状态和执行的分支。
例如:
std::cout << "Value of x: " << x << std::endl;优点:
- 非常直接和简单。
- 可以在生产环境中使用(例如在开发版和发布版中配置不同的日志级别)。
缺点:
- 可能会遗漏某些地方,导致调试信息不够全面。
- 需要在最终代码中删除或关闭冗余的日志输出。
单元测试 (Unit Testing)#
单元测试是一种自动化的方式,可以帮助你验证代码的正确性。使用框架如 Google Test(C++)、JUnit(Java)、pytest(Python)等,可以编写测试用例,自动运行测试,并在代码发生变化时及时捕捉错误。
单元测试的优点:
- 确保代码的每个模块都按预期工作。
- 能够提前发现潜在问题,特别是在修改代码时。
缺点:
- 测试用例需要编写和维护,可能需要额外的时间。
- 需要有较好的测试覆盖率,才能检测到更多的错误。
静态分析工具 (Static Analysis)#
静态分析工具可以在代码运行之前,扫描代码并检查潜在的错误、内存泄漏、资源管理问题等。例如:
- Clang Static Analyzer
- CppCheck
- SonarQube
- Coverity
静态分析工具能够检测到:
- 未初始化的变量。
- 内存泄漏。
- 潜在的并发问题。
- 错误的代码模式等。
代码审查 (Code Review)#
代码审查是与团队成员或同事一起查看和讨论代码的过程。其他开发者可以帮助你发现代码中的潜在问题或逻辑错误。
代码审查的优点:
- 多人的视角能够发现更多问题。
- 通过讨论,能够提升代码质量和团队合作。
集成测试 (Integration Testing)#
集成测试是测试多个组件(或模块)一起工作时的行为。在多个模块组合工作时,问题可能不是单独模块内部,而是它们之间的交互。集成测试帮助你检查模块之间的接口和数据流。
集成测试通常用来发现:
- 模块之间的兼容性问题。
- 数据格式错误。
- 不正确的模块交互等。
内存泄漏检测工具#
如果你的程序存在内存泄漏问题,可以使用专门的工具来检测内存的分配和释放:
- 🔥 Valgrind:广泛用于检测内存泄漏、内存错误等问题,适用于 C/C++ 程序。
- AddressSanitizer:现代编译器(如 Clang、GCC)提供的工具,可以检测内存相关的错误,包括越界访问、内存泄漏等。
这些工具帮助你找出内存泄漏和错误的内存访问问题,并给出详细的报告。
运行时分析工具#
运行时分析工具通过收集程序运行时的信息来进行调试和优化。例如:
- gprof:用于性能分析,查看程序中哪些函数占用了最多的时间。
- perf:Linux 下的性能分析工具,帮助查看程序在系统层面的性能瓶颈。
- VisualVM:Java 应用程序的性能分析工具,能够分析内存、CPU 和线程使用情况。
条件断点和日志断点#
在调试过程中,有时你希望仅在满足特定条件时暂停程序。这时可以使用条件断点或日志断点:
- 条件断点:只有当某个条件成立时,调试器才会停止程序执行。
- 日志断点:调试器在不停止程序执行的情况下,记录断点信息。
回滚与分支 (Git Bisect)#
如果你无法确定错误是在哪次提交中引入的,使用 Git 提供的 git bisect 命令来回滚到历史提交并逐步测试,可以帮助定位问题的来源。
通过二分查找算法,git bisect 可以帮助你快速定位到错误引入的那一行代码。
故障注入 (Fault Injection)#
故障注入是故意在程序中引入故障,以测试程序在面对错误时的反应。例如,可以通过随机生成异常、模拟网络延迟或中断等方式,检查系统的健壮性和错误处理能力。
动态分析与跟踪 (Dynamic Analysis)#
使用跟踪工具(如 strace, ltrace, dtrace 等)来实时观察程序执行过程中的系统调用和函数调用。这种方式帮助你了解程序在运行时的行为,找出性能瓶颈或其他问题。
12. 什么是 C++ 多态?#
C++ 多态即使用基类指针或引用来调用子类的重写方法,从而使得同一接口表现不同的行为。
多态优势:
- 代码复用:通过基类指针或引用,可以操作不同类型的派生类对象,实现代码复用
- 扩展性:新增派生类时,不需要修改依赖于基类的代码,只需要确保新类正确重写了虚函数
- 解耦:多态允许程序更加模块化,降低类之间的耦合度
🔥 面试一定要回答「静态多态」+「动态多态」
多态一般就是指继承 + 虚函数实现的多态,对于重载来说,实际原理是编译器为函数生成符号表时的不同规则,重载只是一种语言特性,与多态无关,与面向对象无关,所以如果非要说重载算是多态的一种,那 C++ 中多态可以分为「静态多态」和「动态多态」两种:
- 静态多态:在编译时期就决定了调用哪个函数,根据参数列表来决定,主要通过函数重载和模板实现
- 动态多态:通过子类重写父类的虚函数来实现,是运行期间决定调用的函数
动态多态的实现与虚函数表(V-Table),虚函数指针(V-Ptr)相关:
- 虚函数表(V-Table):C++ 运行时使用虚函数表来实现多态,每个包含虚函数的类都有一个虚函数表,表中存储了指向类中所有虚函数的指针。
- 虚函数指针(V-Ptr):对象中包含一个指向该类虚函数表的指针。
扩展:子类是否要重写父类的虚函数?子类继承父类时,父类的纯虚函数必须重写,否则子类也是一个虚类不可实例化。定义纯虚函数是为了实现一个接口,起到一个规范的作用,规范继承这个类的程序员必须实现这个函数。
13. 什么是虚函数与虚函数指针,C++ 虚函数的实现原理?#
首先说一下 C++ 中多态的表象:在基类的函数前加上 virtual 关键字,在派生类中重写该函数,运行时将会根据对象的实际类型来调用相应的函数:
- 如果对象类型是派生类,就调用派生类的函数
- 如果是基类,就调用基类的函数
虚函数 vtable 与虚函数指针 vptr#
实际上,当一个类中包含虚函数 virtual 时,编译器就会为该类生成一个虚函数表 vtable,保存该类中虚函数的地址。同样,派生类继承基类,派生类中自然一定有虚函数,所以编译器也会为派生类生成自己的虚函数表 vtable。当我们定义一个派生类对象时,编译器检测到该类型有虚函数,就会为这个派生类对象生成一个虚函数指针 vptr,指向该类型的虚函数表 vtable,虚函数指针 vptr 的初始化是在构造函数中完成的。后续如果有一个基类类型的指针指向派生类,那么当调用虚函数时,就会根据所指真正对象的虚函数表指针 vptr 去寻找虚函数的地址,也就可以调用派生类的虚函数表中虚函数以此实现多态。
补充:如果基类中没有定义成 virtual(只有继承),那么在这种情况调用的则是 Base 中的 func()。因为如果基类和派生类中都没有虚函数 virtual 的定义,那么编译器就会认为不用留给动态多态的机会,就事先进行函数地址的绑定(早绑定 —— 静态绑定),具体过程:
- 定义了派生类对象,首先构造基类的空间,然后构造派生类的自身内容,形成一个派生类对象
- 进行类型转换时,直接截取基类的部分内存,编译器认为类型就是基类,那么函数符号表(不同于虚函数表)绑定的函数地址也就是基类中的函数地址,执行的就是基类函数
// 🌟只有 virtual 存在,编译器才会认为存在「多态」
class Base {
public:
// virtual 不存在则只调用 ~Base()
virtual ~Base() { // 虚析构函数
// 释放 Base 的资源
cout << "释放 Base 的资源" << endl;
}
// virtual 不存在则只调用 Base func()
virtual void func() {
cout << "Base_func()" << endl;
}
};
class Derived : public Base {
public:
// override 可加可不加,有助于编译器检查
~Derived() override {
// 释放 Derived 的资源
cout << "释放 Derived 的资源" << endl;
}
// override 可加可不加,有助于编译器检查
void func() override {
cout << "Derived_func()" << endl;
}
};
int main() {
Base* ptr = new Derived;
ptr->func();
delete ptr; // 调用时,先执行 Derived::~Derived(),再执行 Base::~Base()
return 0;
}Derived_func()
释放 Derived 的资源
释放 Base 的资源C++ 虚函数的内存分布 & 实现原理#
以上简要介绍了「虚函数」相关内容(简要介绍了原理),接下来详细阐述实现原理
更多信息:C++ 虚函数的实现基本原理 ↗
class A {
public:
virtual void v_a(){}
virtual ~A(){}
int64_t _m_a;
};
int main(){
A* a = new A();
return 0;
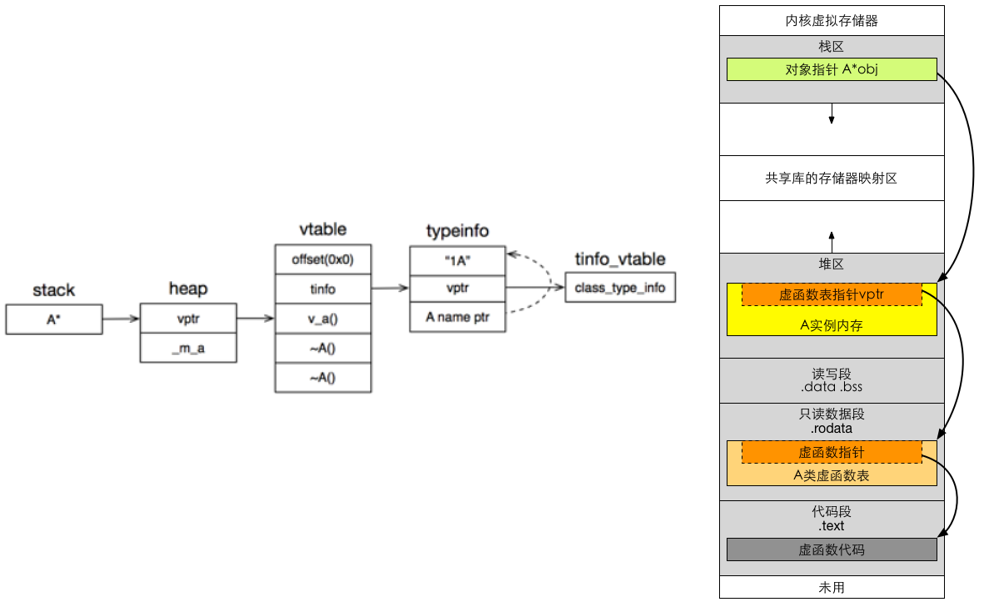
}如以上代码所示,在 C++ 中定义一个对象 A,那么在内存中的分布大概是如下图这个样子。
- 首先在主函数的栈帧上有一个 A 类型的指针指向堆里面分配好的对象 A 实例。
- 对象 A 实例的头部是一个
vtable指针,紧接着是 A 对象按照声明顺序排列的成员变量(当我们创建一个对象时,便可以通过实例对象的地址,得到该实例的虚函数表,从而获取其函数指针) vptr指针指向的是代码段中的 A 类型的虚函数表中的第一个虚函数起始地址。- 虚函数表
vtable的结构其实是有一个头部的,叫做vtable_prefix,紧接着是按照声明顺序排列的虚函数。 - 注意到这里有两个虚析构函数,因为对象有两种构造方式,栈构造和堆构造,所以对应的,对象会有两种析构方式,其中堆上对象的析构和栈上对象的析构不同之处在于,栈内存的析构不需要执行
delete函数,会自动被回收。 typeinfo存储着 A 的类基础信息,包括父类与类名称,C++关键字typeid返回的就是这个对象。typeinfo也是一个类,对于没有父类的 A 来说,当前 tinfo 是class_type_info类型的,从虚函数指针指向的 vtable 起始位置可以看出。
1️⃣ Example-1|如果是多继承情况下,编译器如下处理虚函数表|虚函数的实现原理
- 拷贝基类的虚函数表,多继承则拷贝每个虚函数基类的虚函数表
- 多继承会存在一个基类虚函数表和派生类自身虚函数表合并共用,该基类称为派生类的主基类
- 派生类重写基类虚函数,则替换重写后的虚函数地址
- 如果有自身虚函数,则追加自身虚函数到自身的虚函数表
其中 D 对象
vptr1指向的虚函数表合并了「某个基类虚函数表」和「派生类自身虚函数表」,vptr2则指向另一个基类的虚函数表
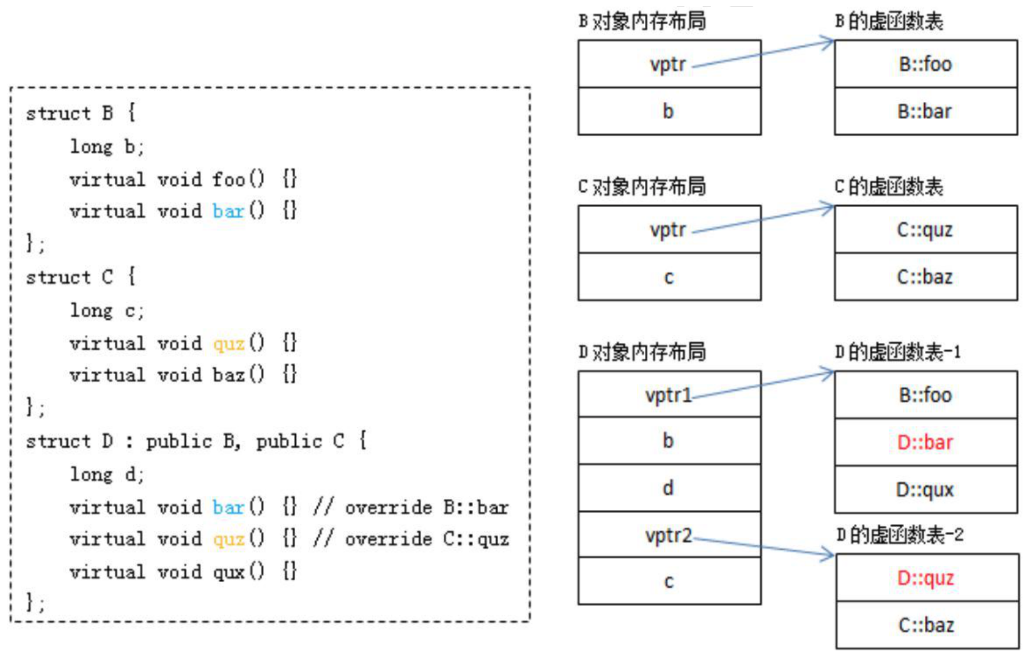
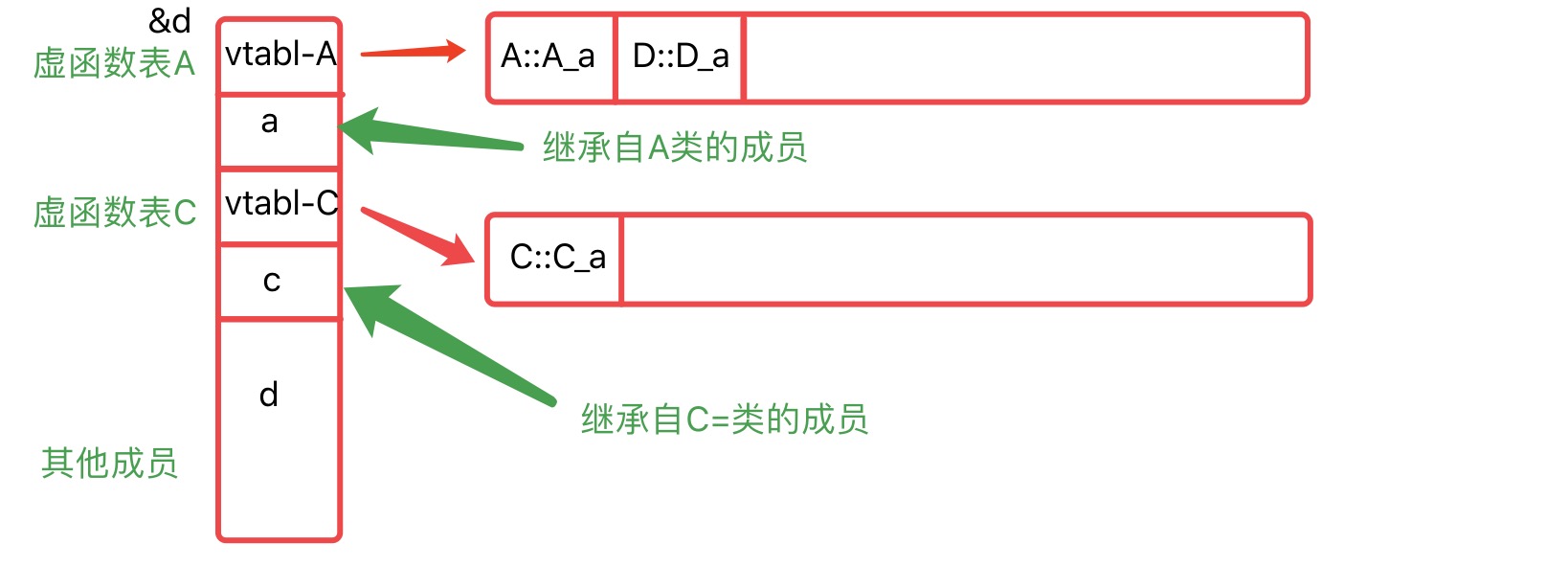
2️⃣ Example-2
class A{
private:
uint64_t a;
public:
virtual void A_a(){std::cout << __func__;}
};
class C{
private:
uint64_t c;
public:
virtual void C_a(){std::cout << __func__;}
};
class D : public A,public C{
private:
uint64_t d;
public:
virtual void D_a(){std::cout << __func__;}
};class D 的虚函数表
14. 析构函数可以是虚函数吗?什么情况下析构函数必须是虚函数?#
🪞镜像问题:
- 为什么需要虚析构?虚析构实现原理?
- 析构函数一般写成虚函数的原因?
析构函数可以是虚函数。将析构函数声明为 virtual 虚函数,确保在删除基类指针指向的派生类对象时,能够正确调用派生类的析构函数,避免内存泄漏。
举例来说,一个基类的指针指向一个派生类的对象,在使用完毕准备销毁时,如果基类的析构函数没有定义成 virtual 虚函数,那么编译器根据指针类型就会认为当前对象类型是基类,仅调用基类的析构函数(该对象的析构函数的函数地址早就被绑定为基类的析构函数——静态绑定 / 早绑定),派生类的自身内容将无法被析构,造成内存泄漏。如果基类的析构函数定义为虚函数,那么编译器就可以根据实际对象,执行派生类的析构函数,再执行基类的析构函数,成功释放内存。
注释助于理解
// 🌟只有 virtual 存在,编译器才会认为存在「多态」
class Base {
public:
// virtual 不存在则只调用 ~Base()
virtual ~Base() { // 虚析构函数
// 释放 Base 的资源
cout << "释放 Base 的资源" << endl;
}
// virtual 不存在则只调用 Base func()
virtual void func() {
cout << "Base_func()" << endl;
}
};
class Derived : public Base {
public:
~Derived() {
// 释放 Derived 的资源
cout << "释放 Derived 的资源" << endl;
}
void func() {
cout << "Derived_func()" << endl;
}
};
int main() {
Base* ptr = new Derived;
ptr->func();
delete ptr; // 调用时,先执行 Derived::~Derived(),再执行 Base::~Base()
return 0;
}Derived_func() // func() 没定义 virtual 则输出 Base_func()
释放 Derived 的资源 // ~Base() 没定义 virtual 则不输出
释放 Base 的资源⚠️ C++ 默认的析构函数不是虚函数,是因为虚函数需要额外的虚函数表和虚表指针,占用额外的内存。
当类被设计为「基类」,并且可能被继承时,析构函数应当声明为虚函数。如果类不会被继承,则析构函数可以不声明为虚函数。然而,为了代码的健壮性和可维护性,通常建议将基类的析构函数声明为虚函数,即使该类当前不会被继承。
15. 构造函数为什么一般不定义为虚函数#
1️⃣ 虚函数调用只需要知道“部分信息”,即只需要知道函数接口,而不需要知道对象的具体类型。但是创建对象时,是需要知道对象的完整信息,特别是需要知道创建对象的确切类型,因此构造函数不应该被定义为虚函数。
2️⃣ 从编译器实现虚函数进行多态的方式来看,虚函数调用时通过实例化之后对象的虚函数表指针 vptr 来找到虚函数地址进行调用的,如果说构造函数是虚的,那么虚函数表指针则不存在(因为虚函数指针 vptr 的初始化是在构造函数中完成的),无法找到对应的虚函数表 vtable 来调用虚函数,那么这个调用实际上也是违反了先实例化后调用的准则。
16. 构造函数的执行顺序?析构函数的执行顺序?#
1️⃣ 构造函数顺序#
- 基类构造函数:如果有多个基类,则构造函数调用顺序是某类在「类派生列表」中出现的顺序,而不是它们在成员初始化表中的顺序
- 成员类对象构造函数:如果有多个成员类对象,则构造函数的调用顺序是对象在类中被声明的顺序,而不是它们出现在成员初始化表中的顺序
- 派生类构造函数
类派生列表
class 派生类名:类派生列表 {
成员列表
}
class Derived : public Base1, public Base2 {
成员列表
}2️⃣ 析构函数顺序#
- 调用派生类的析构函数
- 调用成员类对象的析构函数
- 调用基类的析构函数
17. 静态绑定和动态绑定#
我们首先要知道静态类型和动态类型:
- 静态类型:在程序中被声明时所采用的类型,在编译期间确定
- 动态类型:目前所指对象的实际类型,在运行期间确定
关于静态绑定和动态绑定:
- 静态绑定,又称早绑定,绑定的是静态类型,所对应的函数或属性依赖于对象的静态类型,发生在编译期间。
- 动态绑定,又称晚绑定,绑定的是动态类型,所对应的函数或属性依赖于动态类型,发生在运行期间。
比如说,virtual 函数是动态绑定的,非虚函数是静态绑定的,缺省参数值也是静态绑定的。
⚠️ 注意,我们不应该重新定义继承而来的缺省参数,因为即使我们重定义了,也不会起到效果。因为一个基类的指针指向一个派生类对象,在派生类的对象中针对虚函数的参数缺省值进行了重定义, 但是缺省参数值是静态绑定的,静态绑定绑定的是静态类型相关的内容。
18. 纯虚函数#
纯虚函数是在基类中「声明但不实现」的虚函数,其声明方式是在函数声明的结尾处添加 = 0,类中如果至少包含一个纯虚函数,则该类称为抽象类,抽象类是不能实例化对象的。
纯虚函数的主要作用是定义接口规范,强制要求派生类必须实现这些函数,从而实现借口的统一和标准化。派生类中必须实现继承于基类的纯虚函数,否则含有纯虚函数的类又会是抽象类,无法实例化。
class Shape {
public:
virtual void draw() = 0; // 纯虚函数
};
class Circle : public Shape {
public:
// 必须实现,否则该派生类为抽象类,不能实例化
void draw() override {
cout << "Drawing a circle" << endl;
}
};
int main() {
Shape* shape = new Circle();
shape->draw(); // 输出:Drawing a circle
delete shape;
return 0;
}19. 深拷贝和浅拷贝的区别(举例说明深拷贝的安全性)#
1️⃣ 浅拷贝:
- 当出现类的等号
=赋值时,会调用拷贝构造函数,在未显式定义拷贝构造函数的情况下,系统会调用默认的拷贝函数 —— 即浅拷贝,它能够完成成员的复制,当数据成员中没有指针时,浅拷贝是可行的; - 但当数据成员中有指针时,如果采用简单的浅拷贝,则两个类中的两个指针指向同一个地址,当对象快要结束时,会调用两次析构函数,从而导致野指针的问题。
class ShallowCopy {
private:
int* data;
public:
ShallowCopy(int d) : data(new int(d)) {}
// 而且在对象结束时,会调用两次析构函数,从而导致野指针问题
~ShallowCopy() { delete data; }
void setData(int d) { *data = d; }
int getData() const { return *data; }
// 默认拷贝构造函数(浅拷贝)
ShallowCopy(const ShallowCopy& source) : data(source.data) {}
};
int main() {
ShallowCopy obj1(10);
ShallowCopy obj2 = obj1; // 使用默认拷贝构造函数
cout << "obj1 data: " << obj1.getData() << endl;
cout << "obj2 data: " << obj2.getData() << endl;
obj1.setData(20); // 修改 obj1 的数据
cout << "After modifying obj1" << endl;
cout << "obj1 data: " << obj1.getData() << endl;
cout << "obj2 data: " << obj2.getData() << endl; // obj2 数据也被修改了
return 0;
}2️⃣ 深拷贝:在数据成员含有指针时,必须采用深拷贝(自定义拷贝构造函数),在拷贝构造函数中创建一个全新对象,与原对象完全独立。深拷⻉与浅拷⻉之间的区别就在于,深拷⻉会在堆内存中另外申请空间来存储数据,从而解决来野指针的问题。简而言之,当数据成员中有指针时,必需要用深拷⻉更加安全。
class DeepCopy {
private:
int *data;
public:
DeepCopy(int d) : data(new int(d)) {}
~DeepCopy() { delete data; }
void setData(int d) { *data = d; }
int getData() const { return *data; }
// 自定义拷贝构造函数(深拷贝)
DeepCopy(const DeepCopy &source) : data(new int(*source.data)) {}
};
int main() {
DeepCopy obj1(10);
DeepCopy obj2 = obj1; // 使用自定义拷贝构造函数
cout << "obj1 data: " << obj1.getData() << endl;
cout << "obj2 data: " << obj2.getData() << endl;
obj1.setData(20); // 修改 obj1 的数据
cout << "After modifying obj1" << endl;
cout << "obj1 data: " << obj1.getData() << endl;
cout << "obj2 data: " << obj2.getData() << endl; // obj2 数据没有变化
return 0;
}20. 说一下你理解的 C++ 四种智能指针|shared_ptr 的简易实现#
更多信息:C++ 智能指针 ↗、知乎 C++ 智能指针 ↗
看这两篇,取取交集
在使用 C++ 开发过程中,最容易也是最麻烦的问题便是内存泄漏。相较于 Java、Python 或者 Go 语言都拥有垃圾回收机制,在对象没有引用时就会被系统自动回收而且基本上没有指针的概念,但是 C++ 则要求程序员自己管理内存,这一方面让程序员有更大的自由度但是也会很大影响程序员的开发效率。因此 C++11 标准中新推出了 shared_ptr、unique_ptr 和 weak_ptr 三个智能指针来帮助管理内存。
智能指针就是一个类,当超出了类的作用域时,类会自动调用析构函数,析构函数会自动释放资源,所以智能指针的作用原理就是在函数结束时自动释放内存空间,不需要手动释放。
T* get();
T& operator*();
T* operator->();
T& operator=(const T& val);
T* release();
void reset (T* ptr = nullptr);常用接口:
T是模板参数,即传入的类型get()用来获取auto_ptr封装在内部的指针,也就是获取原生指针operator*()重载*,operator->()重载->,operator=()重载=release()将auto_ptr封装在内部的指针置为nullptr,但不会破坏指针所指向的内容,函数返回的是内部指针置空之前的值reset()直接释放封装的内部指针所指向的内存,如果指定了ptr的值,则将内部指针初始化为该值
接下来说说哪四种智能指针:
auto_ptr为 C++98 的方案,C++11 已抛弃- C++11 引入
std::shared_ptrstd::weak_ptrstd::unique_ptr
0️⃣ auto_ptr#
C++98 方案,C++11 已抛弃
auto_ptr<std::string> p1(new string("string"));
auto_ptr<std::string> p2;
p2 = p1; // auto_ptr 不会报错p2 剥夺了 p1 的所有权,但是当程序运行时访问 p1 将会报错,所以 auto_ptr 缺点就是存在潜在的内存崩溃问题。
1️⃣ shared_ptr 共享式智能指针#
彻底理解:
shared_ptr是有两层析构:
- shared_ptr 本身析构会使得指向的共享对象的引用数 -1,当共享对象引用数为 0 时,则调用共享对象本身的析构函数
- 这样就可以理解循环引用了:共享对象引用还是 1,未调用共享对象本身的析构函数,其中成员 shared_ptr 的析构函数也不会被调用
shared_ptr 能够自动记录共享对象的引用次数,并且在引用计数降至零时自动删除对象,从而防止内存泄漏。每个 shared_ptr 的拷贝都指向相同的内存,在最后一个 shared_ptr 析构的时候其指向的内存资源才会被释放。
shared_ptr 初始化方式:
- 构造函数
std::make_shared()辅助函数reset()
std::shared_ptr<int> p(new int(1));
std::shared_ptr<int> p2 = p;
std::shared_ptr<A> ap = std::make_shared<A>();
std::shared_ptr<int> ptr;
ptr.reset(new int(1));不能将一个原始指针直接赋值给一个智能指针,如:std::shared_ptr<int> p = new int(1)。
对于一个未初始化的智能指针,可以通过调用 reset 方法初始化,当智能指针中有值的时候,调用 reset 方法会使引用计数减 1。当需要获取原指针的时候可以通过 get 方法返回原始指针:
std::shared_ptr<int> p(new int(1));
int *ptr = p.get();智能指针初始化时也可以指定删除器,当其引用计数为 0 时将自动调用删除器来释放对象,删除器可以是一个函数对象。如当使用 shared_ptr 管理动态数组时,需要指定删除器,因为 shared_ptr 默认删除器不支持数组对象:
// lambda 表达式作为删除器
std::shared_ptr<int> p(new int[10], [](int *p) { delete []p; })关于 shared_ptr 的注意事项:
- 不要用一个裸指针初始化多个
shared_ptr,会出现 double_free 导致程序崩溃 - 通过
shared_from_this()返回 this 指针,不要把 this 指针作为shared_ptr返回出来,因为this指针本质就是裸指针,通过 this 返回可能会导致重复析构,不能把 this 指针交给智能指针管理。
class A {
shared_ptr<A> GetSelf() {
return shared_from_this();
// return shared_ptr<A>(this); 错误,会导致 double free
}
};- 尽量使用
std::make_shared<T>(),少用new - 不要
deleteget()返回的裸指针 - 不是
new出来的空间要自定义删除器 - 要避免循环引用,循环引用导致内存永远不会被释放,造成内存泄漏
class A;
class B;
class A {
public:
std::shared_ptr<B> b;
};
class B {
public:
std::shared_ptr<A> a;
};
int main() {
std::shared_ptr<A> ap = std::make_shared<A>();
std::shared_ptr<B> bp = std::make_shared<B>();
ap->b = bp;
bp->a = ap;
// 此时,a 和 b 相互持有对方的 shared_ptr,形成循环引用
// 程序结束时,a 和 b 的引用计数都不会降为零,导致内存泄漏
return 0;
}🌟 解释说明循环引用:
- 首先循环引用导致 shared_ptr 指向的共享对象 A 和 B 的引用计数都是 2;
- 在离开作用域后,根据栈后进先出的特点,首先
shared_ptr<B> bp析构时只减少 B 的引用次数为 1(这里是对象 shared_ptr 析构而非对象 B 析构),由于此时对象 B 的引用次数仍为 1(减为 0 的 B 才会被释放),所以不会调用(对象 B)内部智能指针a的析构函数来减少引用,所以也就无法减少 A 的引用次数了。 - 接着
ap析构时减少 A 的引用次数为 1,此时 A 的引用仍为 1 不会被析构,所以无法析构其成员对象b; - 最终导致指针永远不会析构,产生了内存泄漏(解决方案就是使用
weak_ptr)
2️⃣ weak_ptr 弱引用智能指针#
weak_ptr 是一种不控制对象生命周期的智能指针,它指向一个 shared_ptr 管理的对象,它不管理 shared_ptr 内部指针,进行该对象的内存管理的是那个强引用的 shared_ptr。
weak_ptr 只是提供了对管理对象的一个访问手段。weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作,纯粹是作为一个旁观者监视 shared_ptr 中管理的资源是否存在,它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造,它的构造和析构不会引起引用记数的增加或减少。
weak_ptr 是用来解决 shared_ptr 相互引用时的死锁问题,如果说两个 shared_ptr 相互引用,那么这两个指针的引用计数永远不可能下降为 0,也就是资源永远不会释放。它是对对象的一种弱引用,不会增加对象的引用计数,和 shared_ptr 之间可以相互转化:
- shared_ptr 可以直接赋值给它
- 它也可以通过调用 lock 函数来获得 shared_ptr
循环引用是当两个智能指针都是 shared_ptr 类型的时候,析构时两个资源引用计数会减 1,但是两者引用计数还是为 1,导致跳出函数时资源没有被释放(析构函数没有被调用),解决办法就是把其中一个改为 weak_ptr 就可以。
总之 weak_ptr 可以用来返回 this 指针和解决循环引用问题。
- 作用 1:返回 this 指针,上面介绍的
shared_from_this()其实就是通过weak_ptr返回的 this 指针
Q:
shared_from_this()是如何实现的?A:使用
shared_from_this()的类需要继承enable_shared_from_this类,enable_shared_from_this类中持有一个类型为weak_ptr的成员_M_weak_this,调用shared_from_this()就是将内部持有的weak_ptr转成了shared_ptr。
class enable_shared_from_this
{
shared_ptr<const _Tp> shared_from_this() const
{
return shared_ptr<const _Tp>(this->_M_weak_this);
}
mutable weak_ptr<_Tp> _M_weak_this;
};- 作用 2:解决循环引用问题
class A {
std::shared_ptr<B> bptr;
~A() {
cout << "A delete" << endl;
}
void Print() {
cout << "A" << endl;
}
};
class B {
std::weak_ptr<A> aptr; // 这里改成 weak_ptr
// B 对象销毁时才调用(即引用计数为 0 时)
~B() {
cout << "B delete" << endl;
}
void PrintA() {
if (!aptr.expired()) { // 监视 shared_ptr 的生命周期
auto ptr = aptr.lock();
ptr->Print();
}
}
};
int main() {
auto aaptr = std::make_shared<A>();
auto bbptr = std::make_shared<B>();
aaptr->bptr = bbptr;
bbptr->aptr = aaptr;
bbptr->PrintA();
return 0;
}
// 输出:
// A
// A delete
// B delete🔥 代码解释:尽管局部变量的析构顺序是按照后进先出的原则,但关键在于“对象的销毁时机”是由引用计数决定的,而不是直接由局部变量析构的顺序决定的:
- 局部变量析构顺序:在 main 函数中,aaptr 先创建、bbptr 后创建,因此在退出作用域时,bbptr 会先析构,随后 aaptr 析构。
- 引用计数的影响
- 创建时,aaptr 持有 A 对象,bbptr 持有 B 对象。
- A 对象内部的成员变量 bptr 又持有 B 对象的 shared_ptr,因此 B 对象的引用计数为 2。
- B 对象内部的 weak_ptr 不会影响 A 对象的引用计数。
- 析构过程
- 当 bbptr 析构时,仅仅减少了 B 对象的引用计数,从 2 变为 1,但 B 对象并没有被销毁,因为
aaptr->bptr仍然持有它。 - 随后 aaptr 析构,导致 A 对象的引用计数从 1 变为 0,从而触发 A 的析构函数,输出 “A delete”。
- 在 A 的析构过程中,其成员变量 bptr 被析构,从而使 B 对象的引用计数从 1 减为 0。此时,B 对象的析构函数被调用,输出 “B delete”。
- 当 bbptr 析构时,仅仅减少了 B 对象的引用计数,从 2 变为 1,但 B 对象并没有被销毁,因为
3️⃣ unique_ptr 独占式智能指针(替换 auto_ptr)#
unique_ptr 是一个独占型的智能指针,它不允许其他的智能指针共享其内部的指针:
- 不允许通过赋值将一个
unique_ptr拷贝/赋值给另外一个unique_ptr - 但是允许通过函数返回给其他的
unique_ptr或者通过std::move来转移到其他的unique_ptr,这样的话它本身就不再拥有原指针的所有权了
与 shared_ptr 相比,unique_ptr 除了独占性的特点外,还能够指向一个数组:std::unique_ptr<int []> p(new int[10]);。
shared_ptr 与 unique_ptr 的使用需要根据场景决定,如果希望只有一个智能指针管理资源或者管理数组就使用 unique_ptr,如果希望使用多个智能指针管理同一个资源就使用 shared_ptr。
🔥 实现简易的 shared_ptr#
#include <memory>
template<typename T>
class smartPtr {
private:
T *_ptr;
size_t* _count;
public:
smartPtr(T *ptr = nullptr):_ptr(ptr) {
if (_ptr) {
_count = new size_t(1);
} else {
_count = new size_t(0);
}
}
smartPtr(const smartPtr &ptr) {
if (this != &ptr) {
this->_ptr = ptr._ptr;
this->_count = ptr._count;
++(*this->_count) ;
}
}
smartPtr& operator=(const smartPtr &ptr) {
if (this->_ptr == ptr._ptr)
return *this;
if (this->_ptr) {
--(*this->_count);
if (this->_count == 0) {
delete this->_ptr;
delete this->_count;
}
}
this->_ptr = ptr._ptr;
this->_count = ptr._count;
++(*this->_count);
return *this;
}
~smartPtr() {
--(*this->_count);
if (0 == *this->_count) {
delete this->_ptr;
delete this->_count;
}
}
size_t use_count() {
return *this->_count;
}
T& operator*() {
assert(this->_ptr == nullptr);
return *(this->_ptr);
}
T* operator->() {
assert(this->_ptr == nullptr);
return this->_ptr;
}
};21. shared_ptr 的实现,shared_ptr 一定不会导致内存泄漏吗?#
std::shared_ptr 的实现基于引用计数,每个 shared_ptr 实例持有一个指向控制块的指针,控制块中包含引用计数和所管理对象的指针。 当 shared_ptr 的引用计数降为零时,控制块会删除所管理的对象。 然而,shared_ptr 并非在所有情况下都能防止内存泄漏。 当存在循环引用时,shared_ptr 的引用计数永远不会降为零,导致内存无法被释放,从而引发内存泄漏。
#include <memory>
class A;
class B;
class A {
public:
std::shared_ptr<B> b;
};
class B {
public:
std::shared_ptr<A> a;
};
int main() {
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
a->b = b;
b->a = a;
// 此时,a 和 b 相互持有对方的 shared_ptr,形成循环引用
// 程序结束时,a 和 b 的引用计数都不会降为零,导致内存泄漏
return 0;
}为了解决循环引用问题,可以使用 std::weak_ptr,它是一种不增加引用计数的智能指针。 std::weak_ptr 用于打破循环引用,避免内存泄漏。
#include <memory>
class A;
class B;
class A {
public:
std::weak_ptr<B> b; // 使用 weak_ptr 打破循环引用
};
class B {
public:
std::shared_ptr<A> a;
};
int main() {
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
a->b = b;
b->a = a;
// 此时,a 和 b 之间的循环引用被 weak_ptr 打破
// 程序结束时,a 和 b 的引用计数会降为零,内存会被正确释放
return 0;
}或者如果在类之间的引用是单向的(即不会形成循环引用),可以考虑使用 std::unique_ptr。std::unique_ptr 不会引起引用计数问题,因为它是独占的,每个对象只有一个拥有者。
#include <memory>
class A;
class B;
class A {
public:
std::unique_ptr<B> b; // 改为 unique_ptr
};
class B {
public:
std::shared_ptr<A> a;
};
int main() {
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
a->b = std::move(b); // 转移所有权
// 使用 unique_ptr 的情况下,没有循环引用问题
return 0;
}22. STL 中 vector、list、map 的底层原理实现和适用场景?#
关于 STL 库中所有的结构的底层实现原理:https://zhuanlan.zhihu.com/p/542115773 ↗
顺带了解了 set、map、unordered_map、unordered_set 之间区别:
set、map:底层使用红黑树实现,有序,插入、查找、删除的时间复杂度为
- 优点:有序性,内部实现红黑树使得很多操作都在 时间复杂度下完成
- 缺点:空间占用率高,需要额外保存父节点、孩子节点和红/黑性质
unordered_set、unordered_map:底层使用哈希表实现,无序,查找的时间复杂度为
- 优点:因为内部实现了哈希表,因此其查找速度非常的快
- 缺点:哈希表的建立比较费时
1️⃣ vector 动态数组
vector底层是动态数组,元素连续存储在堆上- 自动扩容机制:
- vector 采用几何增长策略(通常是 2 倍扩容)
- 当
size() == capacity()时,会申请更大的内存空间,然后拷贝旧数据到新空间 - 由于 realloc 可能导致数据搬移,
push_back()的均摊时间复杂度为 ,但最坏情况 (扩容时)
- ❓所以有可能 vector 的插入操作可能导致迭代器失效:因为 vector 动态增加大小时,并不是在原空间后增加新空间,而是以原大小两倍在开辟另外一片较大空间,然后将内容拷贝过来,并释放原有空间,所以迭代器失效。
适用场景:
✅ 高效的随机访问(O(1))。
✅ 批量尾部插入/删除(push_back())。
❌ 不适合频繁插入/删除中间元素(O(n))。
❌ 扩容会导致数据搬移(不适合超大数据集)。
2️⃣ list 双向链表
list底层是双向链表,每个节点存储数据和两个指针- 插入和删除操作非常高效,不影响其他元素
- 不支持随机访问,必须顺序遍历才能找到某个元素
- 不会发生扩容问题,适合频繁插入/删除的场景
适用场景:
✅ 高效插入/删除(O(1),特别是中间位置)。
✅ 不关心随机访问,仅需遍历。
❌ 不适合频繁随机访问(O(n))。
❌ 额外的指针开销(内存占用比 vector 高)。
3️⃣ map 红黑树
map底层实现是红黑树(Red-Black Tree),一种自平衡二叉搜索树- key 是有序的
- 插入、删除、查找 ,因为树的高度是
- 迭代遍历按照 key 顺序进行
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
插入 insert() | 需要维护红黑树平衡 | |
删除 erase() | 删除节点后可能需要旋转 | |
查找 find() | 通过 BST 进行搜索 |
适用场景:
✅ 需要有序存储的数据结构(默认按照 key 递增)。
✅ 需要高效查找、插入、删除(O(log n))。
❌ 不适合频繁变更 key(因为 key 作为 BST 节点的一部分)。
❌ 遍历效率比 unordered_map 低(有序存储开销大)。
23. 菱形继承会出现二义性问题,C++ 中如何解决这个问题?#
❓镜像问题:一个派生类继承两个父类,这两个父类同时有一个共同基类,如果你去调用两个父类的基类对象函数,会有问题吗?怎么解决?
注:在 Java 中,由于 Java 不支持多重继承,所以菱形继承问题也不存在。 Java 使用接口来替代多重继承,接口只定义了一些抽象的方法,而没有具体的实现。
这是 C++ 多重继承造成的菱形继承问题,如果一个派生类继承了两个拥有相同基类的父类,那么基类的成员会被继承两次,这会导致 “二义性问题” 和 “冗余存储”。
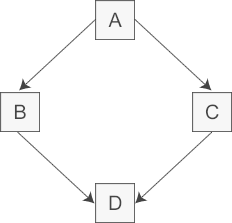
❌ 编译错误!
#include <iostream>
class Base {
public:
void show() { std::cout << "Base::show()" << std::endl; }
};
class Parent1 : public Base {}; // 继承自 Base
class Parent2 : public Base {}; // 继承自 Base
// 多重继承
class Derived : public Parent1, public Parent2 {};
int main() {
Derived d;
d.show(); // ⚠️ 编译错误:二义性
return 0;
}1️⃣ 解决方案一:使用作用域解析符
缺点:Derived 仍然包含 两个 Base 实例,数据冗余,而且每次调用 show() 需要手动指定作用域,不优雅。
int main() {
Derived d;
d.Parent1::show(); // 访问 Parent1 继承的 Base
d.Parent2::show(); // 访问 Parent2 继承的 Base
return 0;
}2️⃣ 使用虚继承|最佳方案 ✅
虚继承是为了让某个类做出声明,承诺愿意共享它的基类,这个被共享的基类就是虚基类
多继承除了造成命名冲突,还有数据冗余等问题,为了解决这些问题,C++ 引进了「虚继承」
这样能够保证 Derived 只含有一个唯一的 Base 实例。
#include <iostream>
class Base {
public:
void show() { std::cout << "Base::show()" << std::endl; }
};
// 让 Parent1 和 Parent2 进行虚继承
class Parent1 : virtual public Base {};
class Parent2 : virtual public Base {};
// 继承 Parent1 和 Parent2
class Derived : public Parent1, public Parent2 {};
int main() {
Derived d;
d.show(); // ✅ 现在可以直接调用,不会有二义性
return 0;
}不使用 virtual 时
Derived会有两个Base对象,导致二义性问题。- 内存浪费(两个
Base子对象的冗余)。
使用 virtual 继承
Parent1和Parent2不会各自包含Base的副本,而是共享同一个Base实例。Derived只会有一个Base实例,所以调用show()时不会有二义性。
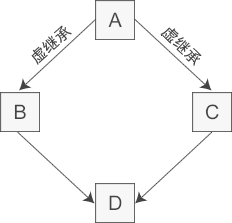
🔥虚继承是为了让某个类做出声明,承诺愿意共享它的基类,这个被共享的基类就是虚基类!
使用虚继承解决菱形继承中的命名冲突问题
🔥 虚继承在 C++ 标准库中的实际应用
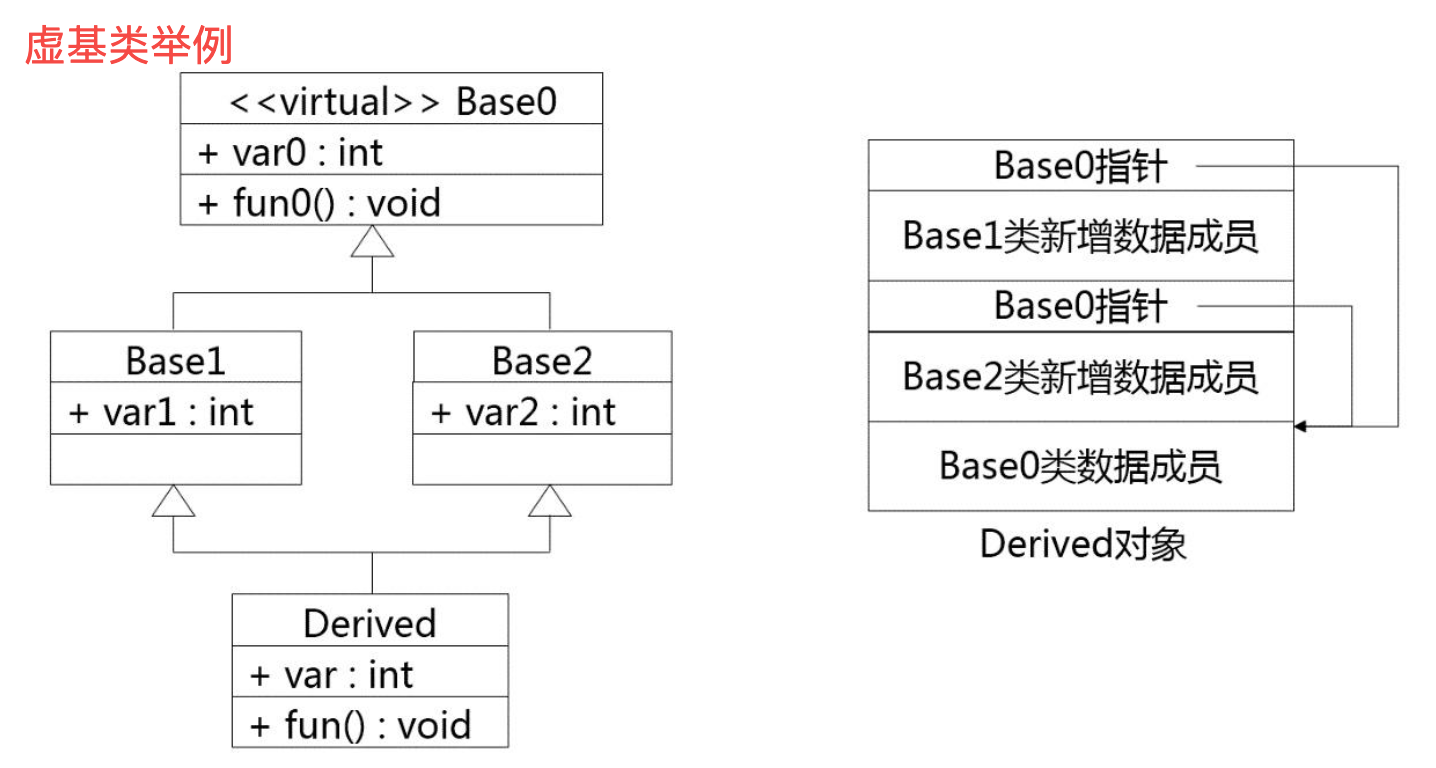
再看个虚继承的例子,彻底明白虚继承:
#include <iostream>
using namespace std;
class Base0 {
public:
int var0;
void fun0() { cout << "Member of Base0" << endl; }
};
class Base1 : virtual public Base0 {
public:
int var1;
};
class Base2 : virtual public Base0 {
public:
int var2;
};
class Derived : public Base1, public Base2 {
//定义派生类Derived
public:
int var;
void fun() {
cout << "Member of Derived" << endl;
}
};
int main() {
Derived d;
d.var0 = 2; //直接访问虚基类的数据成员
d.fun0(); //直接访问虚基类的函数成员
return 0;
}⁉️将 Base0 类作为它的直接派生类 Base1 和 Base2 的虚基类,即 Base1 虚继承 Base0,Base2 虚继承 Base0。之后 Derived 再继承 Base1 和 Base2,在 Derived 对象里面就不会存在 Base0 类的双份的成员。
Derived 对象包含着从 Base1 继承的成员和从 Base2 继承的成员,但是从 Base1 继承的 Base0 成员实际上这个地方放了一个指针,这个指针指向真正的 Base0 成员,Base2 的也是。所以实质上从最远的基类继承过来的成员,在最远派生类中只有一份。
24. 动态编译 vs 静态编译,动态链接 vs 静态链接?#
在编译和链接过程中,我们可以分为以下几个阶段:
- 编译(Compilation):将源代码
.cpp转换为目标文件.o。 - 链接(Linking):将多个目标文件和库组合成一个可执行文件。
(1) 静态编译 vs 动态编译
- 静态编译(Static Compilation):所有代码都在 编译时 确定,并编译成完整的 可执行文件。
- 动态编译(Dynamic Compilation):代码可以在 运行时动态生成或加载,例如 JIT(Just-In-Time)编译。
(2) 静态链接 vs 动态链接
- 静态链接(Static Linking):
- 编译时 将所有 库的代码 直接复制到可执行文件中。
- 生成的可执行文件 较大,但不依赖外部动态库。
- 动态链接(Dynamic Linking):
- 运行时按需加载动态库(
.so/.dll)。 - 可执行文件 更小,可以更新动态库而无需重新编译整个程序。
- 运行时按需加载动态库(
25. 拷贝构造函数与 operator=() 的区别?#
在 C++ 中,拷贝构造函数 和 赋值运算符 (operator=) 主要区别在于 调用时机和行为。
(1) 拷贝构造函数
- 作用:用于创建新对象时,用已有对象进行初始化。
- 调用时机:
- 用已有对象初始化新对象
- 函数按值传递参数
- 函数返回对象(优化前的 NRVO)
示例:
class MyClass {
public:
int data;
MyClass(int d) : data(d) {}
// 拷贝构造函数
MyClass(const MyClass& other) {
data = other.data;
std::cout << "Copy Constructor\n";
}
};
int main() {
MyClass obj1(10);
MyClass obj2 = obj1; // 拷贝构造
}输出:
CopyEdit
Copy Constructor(2) 赋值运算符 operator=
- 作用:用于 已有对象之间赋值,即一个对象的内容 被另一个对象替换。
- 调用时机:
- 两个已存在对象进行赋值时
- 🔥
a = b;而不是MyClass a = b;
示例:
class MyClass {
public:
int data;
MyClass(int d) : data(d) {}
// 赋值运算符
MyClass& operator=(const MyClass& other) {
if (this == &other) return *this; // 防止自赋值
data = other.data;
std::cout << "Assignment Operator\n";
return *this;
}
};
int main() {
MyClass obj1(10);
MyClass obj2(20);
obj2 = obj1; // 赋值运算符调用
}输出:
Assignment Operator(3) 主要区别
| 对比项 | 拷贝构造函数 | 赋值运算符 (operator=) |
|---|---|---|
| 作用 | 初始化新对象 | 赋值给已有对象 |
| 调用时机 | MyClass a = b; | a = b; |
| 是否创建新对象 | ✅ 是 | ❌ 否 |
| 默认行为 | 成员逐一拷贝 | 成员逐一赋值 |
(4) 特殊情况
避免自赋值
if (this == &other) return *this;支持链式赋值
MyClass& operator=(const MyClass& other) {
this->data = other.data;
return *this;
}
obj1 = obj2 = obj3; // 链式赋值26. 右值引用的主要用途?#
等价于问题:什么情况下会用到右值引用。
右值引用是 C++11 引入的新特性,用于实现移动语义和完美转发:
1️⃣ 实现移动语义#
在传统 C++ 中,对象的赋值和传递通常涉及深拷贝,这会带来性能开销,通过右值引用,可以触发移动构造函数将资源所有权从一个对象转移到另一个对象(将资源从临时对象移动到新对象),无需深拷贝,避免了不必要的复制和销毁操作。
当一个临时对象或不再使用的资源,需要被高效地“移动”而不是拷贝时,就用到右值引用
std::vector<int> v1 = {1,2,3};
std::vector<int> v2 = std::move(v1); // 此时v1内容转移给v2,避免深拷贝2️⃣ 完美转发#
用于函数模板的完美转发,将参数以原始的形式传递给下一个函数,避免了不必要的复制和类型转换。
模板中利用万能引用(forwarding reference)配合
std::forward实现任意类型参数的原始性质传递
template<typename T>
void wrapper(T&& arg) {
func(std::forward<T>(arg)); // 原样传递arg(左值传左值,右值传右值)
}针对「完美转发」,请看如下例子#
假设我们有两个重载的函数 process,一个接收左值引用,另一个接收右值引用:
void process(int& i) {
std::cout << "左值引用处理: " << i << std::endl;
}
void process(int&& i) {
std::cout << "右值引用处理: " << i << std::endl;
}现在,我们希望编写一个模板函数 forwarding,它能够将传入的参数完美地转发给 process,即保持参数的左值或右值属性不变。
- 不使用完美转发的情况:如果我们直接在模板函数中调用
process(param),无论传入的是左值还是右值,param在函数内部都是一个左值,这会导致总是调用接收左值引用的process函数:
template <typename T>
// void forwarding(T param) 也是如此,即右值无法传递进去导致参数不匹配
void forwarding(T&& param) {
process(param); // param 被视为左值,即右值无法传递进去导致参数不匹配
}- 使用完美转发的情况:为了实现完美转发,我们需要:
- 使用万能引用:在模板参数中使用
T&&,使得函数能够同时接收左值和右值。 - 为了解决这个问题,引入了
std::forward, 将模板函数改成如下形式就可以了,forward被称为完美转发,根据参数的类型(左值或右值)进行条件转发,保持其原有的值类别。语义上:数据是左值就转发成左值,右值就转发成右值,哪怕在万能引用中也是如此。
- 使用万能引用:在模板参数中使用
实现如下:
#include <utility> // std::forward
template <typename T>
void forwarding(T&& param) {
process(std::forward<T>(param));
}测试代码:
int main() {
int a = 10;
forwarding(a); // 传入左值
forwarding(20); // 传入右值
forwarding(std::move(a)); // 将左值转换为右值
return 0;
}输出结果:
左值引用处理: 10
右值引用处理: 20
右值引用处理: 10补充:左值引用(&)与右值引用(&&)#
在 C++11 中提出了右值引用,作用是为了和左值引用区分开来,其作用是: 右值引用限制了其只能接收右值,可以利用这个特性从而提供重载,这是右值引用有且唯一的特性,限制了接收参数必为右值, 这点常用在 move construct 中,告诉别人这是一个即将消失的对象的引用,可以瓜分我的对象东西,除此之外,右值引用就没有别的特性了。
class Base{
public:
Base(const Base& b){...} //copy construct
Base(Base&& b){...} //move construct
};然后,一个右值引用变量在使用上就变成了左值,已经不再携带其是右引用这样的信息,只是一个左值,这就是引用在c++中特殊而且复杂的一点,引用在 c++ 中是一个特别的类型,因为它的值类型和变量类型不一样, 左值/右值引用变量的值类型都是左值, 而不是左值引用或者右值引用。
int val = 0;
int& val_left_ref = val;
int&& val_right_ref = 0;
// 引用必须在初始化时绑定到一个有效的对象,且绑定后无法更改
val_left_ref = 0; // val_left_ref 此时是 int,而不是 int&
val_right_ref = 0; // val_right_ref 此时是 int, 而不是 int&&🔥 补充:万能引用(T&&)#
模板中的 T&& 不同于普通的右值引用,而是万能引用,其既能接收左值又能接收右值。
template<typename T>
void emplace_back(T&& arg) {
}
Class Base {
};
int main() {
Base a;
emplace_back(a); // ok
emplace_back(Base()); // also ok
return 0;
}这种特性常用在容器元素的增加上,利用传参是左值还是右值进而在生成元素的时候调用 copy construct 还是 move construct,比如说 vector 的 emplace_back。
所以为什么需要
std::forwad?
模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力,但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值,我们希望能够在传递过程中保持它的左值或者右值的属性, 如果不使用 forward,直接按照下面的方式写就会导致问题。
template <typename T>
// void forwarding(T param) 也是如此,即右值无法传递进去导致参数不匹配
void forwarding(T&& param) {
process(param); // param 被视为左值,即右值无法传递进去导致参数不匹配
}所以为了解决这个问题引入了 std::forward,将模板函数改成如下形式,即可实现完美转发:
template <typename T>
void forwarding(T&& param) {
process(std::forward<T>(param));
}27. C++ 中有哪些锁?#
更多参考:如何避免死锁 ↗、介绍几种经典的锁 ↗
- 从种类上分:普通锁、读写锁、递归锁
- 从实现上分:互斥锁、自旋锁、信号量、条件变量
互斥锁(Mutex)#
🌟互斥锁是在抢锁失败的情况下主动放弃 CPU 进入睡眠状态直到锁的状态改变时再唤醒,而操作系统负责线程调度,为了实现锁的状态发生改变时唤醒阻塞的线程或者进程,需要把锁交给操作系统管理,所以互斥锁在加锁操作时涉及上下文的切换。互斥锁实际的效率还是可以让人接受的,加锁的时间大概 100ns 左右,而实际上互斥锁的一种可能的实现是先自旋一段时间,当自旋的时间超过阀值之后再将线程投入睡眠中,因此在并发运算中使用互斥锁(每次占用锁的时间很短)的效果可能不亚于使用自旋锁。
- 互斥锁(Mutex):用于保护共享资源,确保任一时刻只有一个线程访问资源。
- 信号量(Semaphore):一种特殊的计数器,可以同时允许多个线程访问有限的共享资源。
互斥锁相当于信号量初值为 1 的特殊情况;信号量允许多个线程并发访问资源(初值 > 1)。
std::mutex mtx;
void foo() {
std::lock_guard<std::mutex> lock(mtx);
// 临界区操作
}应用场景:
- 保护关键资源(如共享变量)
- 控制资源的访问量
条件锁/条件变量(Condition Variable)#
🌟互斥锁一个明显的缺点是他只有两种状态:锁定和非锁定。而条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,他常和互斥锁一起使用,以免出现竞态条件。当条件不满足时,线程往往解开相应的互斥锁并阻塞线程然后等待条件发生变化。一旦其他的某个线程改变了条件变量,他将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。总的来说互斥锁是线程间互斥的机制,条件变量则是同步机制。
条件变量用于线程间通信,当某个条件满足后再唤醒等待线程。
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cv;
bool ready = false;
void wait_thread() {
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, [](){ return ready; }); // 等待条件满足
// 执行后续任务
}
void signal_thread() {
{
std::lock_guard<std::mutex> lock(mtx);
ready = true; // 修改条件
}
cv.notify_one(); // 通知等待线程
}应用场景:
- 生产者-消费者模型
- 线程等待某条件满足才能执行
自旋锁(Spin Lock)#
🌟如果线程无法取得锁,线程不会立刻放弃 CPU 时间片,而是一直循环尝试获取锁,直到获取为止。如果别的线程长时期占有锁那么自旋就是在浪费 CPU 做无用功,但是自旋锁一般应用于加锁时间很短的场景,这个时候效率比较高。
线程在等待资源时不会挂起或睡眠,而是不断循环检测锁状态(忙等待)
#include <atomic>
class SpinLock {
std::atomic_flag lock_ = ATOMIC_FLAG_INIT;
public:
void lock() {
while (lock_.test_and_set(std::memory_order_acquire));
}
void unlock() {
lock_.clear(std::memory_order_release);
}
};应用场景:
- 临界区非常短小
- 多核 CPU、短暂等待资源的情况
读写锁(Read-Write Lock)#
允许多个线程同时进行读操作,但写操作必须独占访问。
特点:
- 读锁共享:多个读线程并发执行
- 写锁独占:写线程执行时不能有其他读、写线程存在
// C++17 的 shared_mutex
#include <shared_mutex>
std::shared_mutex rw_mutex;
int shared_data = 0;
void reader() {
std::shared_lock<std::shared_mutex> lock(rw_mutex);
// 读取shared_data
}
void writer() {
std::unique_lock<std::shared_mutex> lock(rw_mutex);
shared_data++; // 写操作
}应用场景:大量读、少量写的场景(如配置文件读取,缓存数据等)
递归锁(Recursive Mutex)#
同一线程可以多次获取同一个锁,但必须释放相同次数后才完全解锁。
特点:
- 避免了同一线程递归调用中因反复加锁而引起的死锁问题
- 相比普通锁,多了一些额外开销
#include <mutex>
std::recursive_mutex r_mutex;
void recursive_function(int n) {
std::lock_guard<std::recursive_mutex> lock(r_mutex);
if (n > 0) {
recursive_function(n - 1); // 递归调用
}
// 临界区操作
}应用场景:函数递归调用或函数间的相互调用都可能再次尝试获取同一锁
28. 如何用 C++ 实现一个读写锁#
#include <mutex>
#include <condition_variable>
class RWLock {
private:
std::mutex mtx_;
std::condition_variable cv_;
int readers_; // 正在读取的线程数量
int writers_waiting_; // 等待写入的线程数量
bool writing_; // 当前是否有写线程
public:
RWLock() : readers_(0), writers_waiting_(0), writing_(false) {}
// 读锁定
void lock_read() {
std::unique_lock<std::mutex> lock(mtx_);
// 当有写操作进行中或等待中的写操作时等待
cv_.wait(lock, [this]() {
return !writing_ && writers_waiting_ == 0;
});
++readers_;
}
// 读解锁
void unlock_read() {
std::unique_lock<std::mutex> lock(mtx_);
if (--readers_ == 0) {
cv_.notify_all();
}
}
// 写锁定
void lock_write() {
std::unique_lock<std::mutex> lock(mtx_);
++writers_waiting_;
cv_.wait(lock, [this]() { return !writing_ && readers_ == 0; });
--writers_waiting_;
writing_ = true;
}
// 写解锁
void unlock_write() {
std::unique_lock<std::mutex> lock(mtx_);
writing_ = false;
cv_.notify_all();
}
};使用实例:
#include <iostream>
#include <thread>
#include <vector>
#include <chrono>
RWLock rwlock;
int shared_data = 0;
void reader(int id) {
rwlock.lock_read();
std::cout << "Reader " << id << " reads value: " << shared_data << "\n";
std::this_thread::sleep_for(std::chrono::milliseconds(100));
rwlock.unlock_read();
}
void writer(int id) {
rwlock.lock_write();
++shared_data;
std::cout << "Writer " << id << " updated value to: " << shared_data << "\n";
std::this_thread::sleep_for(std::chrono::milliseconds(150));
rwlock.unlock_write();
}
int main() {
std::vector<std::thread> threads;
// 启动读线程
for (int i = 0; i < 5; ++i) {
threads.emplace_back(reader, i);
}
// 启动写线程
for (int i = 0; i < 3; ++i) {
threads.emplace_back(writer, i);
}
for (auto &t : threads) {
t.join();
}
return 0;
}-
以上实现倾向于写优先(有写操作等待时,不允许新的读操作)。
-
可以通过修改逻辑实现读优先或公平性策略,例如:
- 去除
writers_waiting_ == 0的约束实现读优先。 - 更复杂的公平策略则需要额外的数据结构管理等待顺序。
- 去除
-
实际应用中,推荐使用现有的成熟实现,例如:
- C++17 起的标准库提供的
std::shared_mutex(标准的读写锁实现):
- C++17 起的标准库提供的
#include <shared_mutex>
std::shared_mutex rw_mutex;
void reader() {
std::shared_lock lock(rw_mutex); // 读锁
// 读取数据
}
void writer() {
std::unique_lock lock(rw_mutex); // 写锁
// 修改数据
}29. 引用和指针的区别,是否能加 const,作用是什么?#
指针:存储变量的内存地址,可以为空(nullptr),需要通过解引用操作符*访问指针指向的值。指针可以在运行时重新指向不同的对象。指针可以有多级。
引用:是变量的别名,必须在初始化时绑定到一个有效的对象,且绑定后无法更改。引用不能为空,始终指向初始化时绑定的对象。引用只有一级。
const修饰:
- 指针:
const可以修饰指针本身或指针指向的对象。- 指向常量的指针:
const int* ptr/int const* ptr表示指针指向的值是常量,不能通过该指针修改值,但可以改变指针本身的指向。 - 常量指针:
int* const ptr表示指针本身是常量,不能改变指针的指向,但可以通过指针修改指向的值。 - 指向常量的常量指针:
const int* const ptr表示指针本身和指针指向的值都是常量,既不能修改指针的指向,也不能修改指向的值。
- 指向常量的指针:
- 引用:引用本身不能是常量,但可以引用一个常量对象。
- 指向常量的引用:
const int& ref表示引用绑定到一个常量值,不能通过该引用修改值。常量引用常用于函数参数,允许函数接受常量或非常量实参而不进行拷贝。
- 指向常量的引用:
30. 哈希桶满了怎么办?#
哈希表(如 unordered_map)在插入元素后,如果负载因子(load_factor,即元素个数/桶数量)超过阈值(通常是1.0左右),将触发扩容(rehash):
- 重新分配更多的 bucket(一般是原来容量的2倍或更多)。
- 重新计算元素位置(rehash),将原有元素重新插入新的 bucket 中。
- 扩容时性能开销较大 。
因此,为了减少扩容次数,可以提前使用 reserve 或 rehash 提高效率。
unordered_map<int, int> umap;
umap.reserve(1000); // 提前预留空间,避免频繁扩容31. AVL vs. 红黑树#
AVL 树(严格平衡二叉树):
- 左右子树高度差绝对不能超过1。
- 插入删除频繁时,旋转调整成本较高(严格的平衡限制)。
- 查询效率略优于红黑树(更平衡),但插入删除的开销稍高。
- 适用于对查询操作要求极高,但修改频率较低的场景。
红黑树(弱平衡二叉树):
- 平衡规则相对宽松,允许一定的高度差异。
- 插入删除操作旋转调整较少,综合效率更高。
- 广泛应用于 C++ 中的 STL
map、set等数据结构中。 - 更适用于插入删除较频繁的场景。
如果场景读多写少,要求非常严格的平衡,AVL 树适合。
如果场景写操作频繁,对读写整体性能要求更均衡,红黑树更合适。
32. move() 底层原理#
std::move() 的底层原理实际上非常简单,它本身并不真正执行移动,而是一个类型转换工具,用来将左值(lvalue)强制转换为右值引用(rvalue reference),从而允许移动语义发生。
一、源码分析(典型实现)#
在C++标准库中,std::move() 一般可实现为如下模板函数:
template <typename T>
constexpr std::remove_reference_t<T>&& move(T&& arg) noexcept {
return static_cast<std::remove_reference_t<T>&&>(arg);
}上述代码可以解析为:
T&& arg:这是一个万能引用(forwarding reference),能够绑定到左值或右值。remove_reference_t<T>:移除模板参数T可能带有的引用限定符,保证返回的确实是一个右值引用类型。static_cast<remove_reference_t<T>&&>:进行强制类型转换,将传入参数从左值转换为右值引用。
二、原理分析#
std::move() 本身没有发生移动动作,它只是一个类型转换工具:
- 转换前:变量(对象)本身是左值,只能调用拷贝构造函数或拷贝赋值。
- 转换后:变量变为右值引用,具备调用移动构造函数或移动赋值的资格。
本质是告诉编译器:“这里的对象我不再需要了,可以放心进行资源的移动操作。”
例如:
std::string str1 = "Hello";
std::string str2 = std::move(str1);
// str1 的内容被“窃取”,str2 可能直接接管内部缓冲区,而非复制三、实际的“移动”如何发生?#
实际的移动(资源转移)是通过被调用对象的移动构造函数或移动赋值运算符实现的,而不是通过std::move()实现:
例如,std::string 的移动构造函数的伪代码:
// 移动构造函数示意
string(string&& other) noexcept {
data_ = other.data_;
size_ = other.size_;
other.data_ = nullptr; // 原对象失去所有权
other.size_ = 0;
}std::move() 提供右值引用,而真正资源转移的逻辑,由类的移动构造或移动赋值完成。
四、注意事项#
std::move()不会清空对象:- 调用
std::move()后的对象处于有效但未指定状态(valid but unspecified state),通常对象变为空或默认状态。 - 你可以继续赋值或析构,但不应该继续访问对象原先的资源。
- 调用
- 移动语义要求类本身支持移动构造或移动赋值:
- 若类本身未定义移动构造或移动赋值,调用
std::move()仍然可能降级成拷贝。
- 若类本身未定义移动构造或移动赋值,调用
| 问题 | 结论 |
|---|---|
std::move()本质是什么? | 类型转换函数,从左值转为右值引用 |
| 真正的移动操作在哪里发生? | 类的移动构造函数或移动赋值运算符 |
| 调用后原对象的状态? | 有效但未指定 |
std::move() 本身几乎没有开销,它只是一个编译期的类型转换工具,真正的开销和行为由类型本身的移动构造和赋值函数决定。
33. 可执行文件加载到内存里,其内存布局是怎样的?#
当可执行文件(如Linux ELF格式)加载到内存中运行时,其典型内存布局为:
从低地址到高地址顺序:
| 内存段 | 功能说明 |
|---|---|
| 代码段(text segment) | 存放程序的机器指令(只读、可执行) |
| 数据段(data segment) | 已初始化的全局变量和静态变量 |
| BSS段(bss segment) | 未初始化或初值为零的全局变量和静态变量 |
| 堆(Heap) | 动态分配的内存(由低地址向高地址增长) |
| ↕️ | (动态增长空间) |
| 栈(Stack) | 函数调用栈帧(由高地址向低地址增长) |
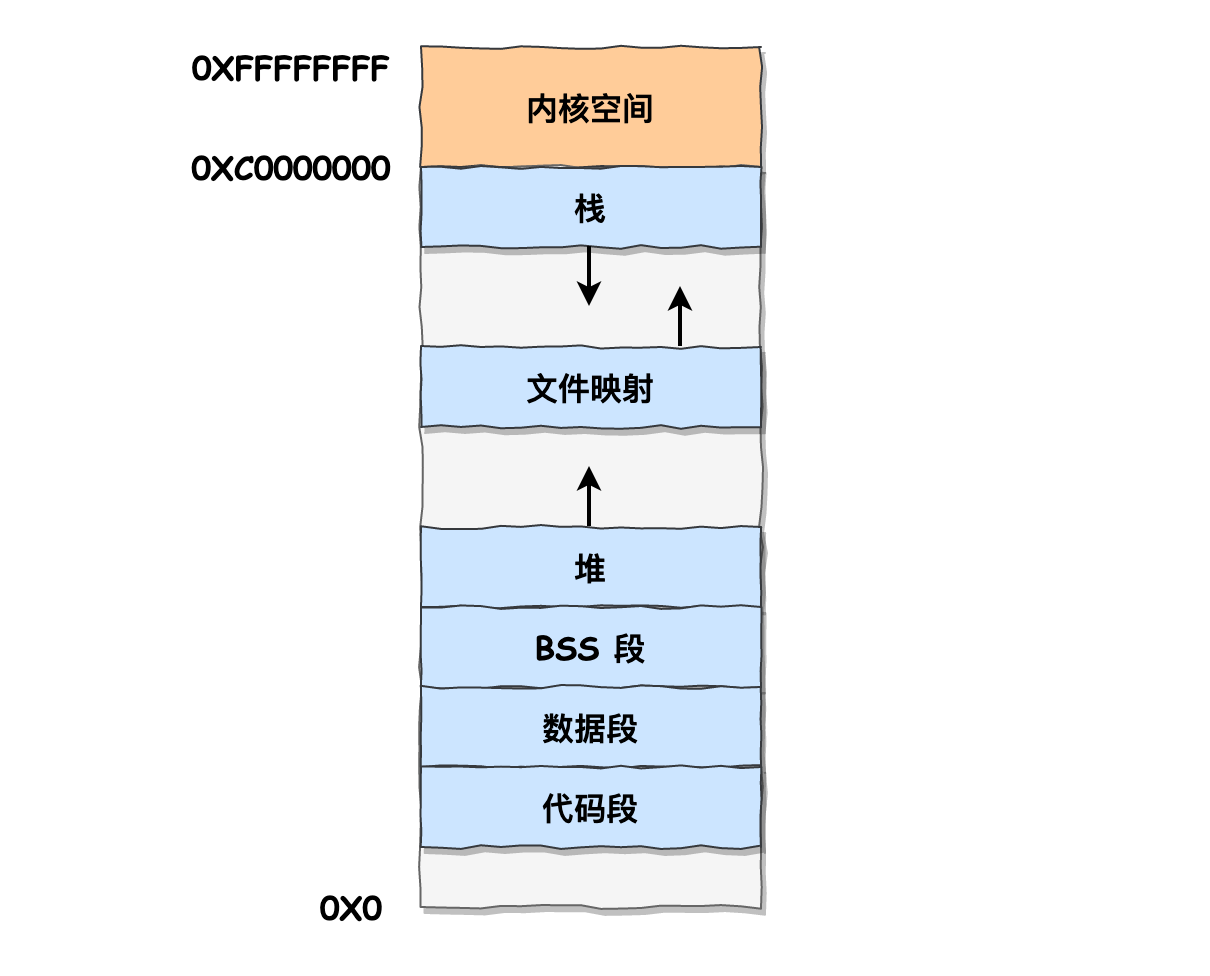
- 代码段:函数指令
- 数据段:全局或静态变量(初值不为0)
- BSS段:全局或静态变量(初值为0或未初始化)
- 堆段:动态内存(malloc/new)
- 栈段:函数调用的局部变量、调用返回地址、临时变量等
- 文件映射段:包括动态库、共享内存等,从低地址开始向上增长(跟硬件和内核版本有关)
34. 宏定义与函数的区别?#
- 宏在预处理阶段完成替换,之后被替换的文本参与编译,相当于直接插入了代码,运行时不存在函数调用,执行起来更快;函数调用在运行时需要跳转到具体调用函数。
- 宏定义属于在结构中插入代码,没有返回值;函数调用具有返回值。
- 宏定义参数没有类型,不进行类型检查;函数参数具有类型,需要检查类型。
35. 宏定义 define 与 typedef 的区别?#
- 宏主要用于定义常量及书写复杂的内容;typedef 主要用于定义类型别名。
- 宏替换发生在编译阶段之前(预处理阶段),属于文本插入替换;typedef 是编译的一部分。
- 宏不检查类型;typedef 会检查数据类型。
- 注意对指针的操作,
typedef char * p_char和#define p_char char *区别巨大。
36. 变量声明与定义的区别?#
- 声明仅仅是把变量的声明的位置及类型提供给编译器,并不分配内存空间
- 定义要在定义的地方为其分配存储空间
相同变量可以在多处声明(外部变量 extern),但只能在一处定义。
37. strlen 和 sizeof 的区别?#
- sizeof 参数可以是任何数据的类型或者数据(sizeof 参数不退化)
- strlen 参数只能是字符指针且结尾是’\0’的字符串
int main() {
const char* str = "Hello World";
cout << sizeof(str) << endl; // 指针字节:8
cout << strlen(str) << endl; // 字符串长度(不包含'\0'):11
return 0;
}38. final 和 override#
override:指定了子类的这个虚函数是重写的父类的,如果你名字不小心打错了的话,编译器是不会编译通过的final:当某个类不希望被继承,或者某个虚函数不希望被重写,那么可以在类名和虚函数后添加final关键字,添加 final 关键字后被继承或重写,编译器会报错
class Base {
virtual void foo();
};
class A : public Base {
void foo() final; // foo 被 override 并且是最后一个 override,在其子类中不可以重写
};
// 指明 B 是不可以被继承的
class B final : public A {
void foo() override; // Error: 在 A 中已经被 final 了
};
// Error: B is final
class C : public B {
};39. C 与 C++ 的类型安全#
类型安全很大程度上可以等价于内存安全,类型安全的代码不会试图访问自己没被授权的内存区域。“类型安全”常被用来形容编程语言,其根据在于该门编程语言是否提供保障类型安全的机制;有的时候也用“类型安全”形容某个程序,判别的标准在于该程序是否隐含类型错误。
类型安全的编程语言与类型安全的程序之间,没有必然联系。好的程序员可以使用类型不那么安全的语言写出类型相当安全的程序,相反的,差一点儿的程序员可能使用类型相当安全的语言写出类型不太安全的程序。绝对类型安全的编程语言暂时还没有。
C 的类型安全#
C 只在局部上下文中表现出类型安全,比如试图从一种结构体的指针转换成另一种结构体的指针时,编译器将会报告错误,除非使用显式类型转换。然而,C 中相当多的操作是不安全的。以下是两个十分常见的例子:
1️⃣ printf 格式输出:下述代码中,使用 %d 控制整型数字的输出,没有问题,但是改成 %f 时,明显输出错误,再改成 %s 时,运行直接报 segmentation fault 错误
#include <stdio.h>
int main() {
printf("%d\n", 10); // 10
printf("%f\n", 10); // 0.00
return 0;
}2️⃣ malloc 函数返回值:malloc 是 C 中进行内存分配的函数,它的返回类型是 void* 即空类型指针,常常有这样的用法 char* pStr = (char*)malloc(100 * sizeof(char)),这里明显做了显式的类型转换。类型匹配尚且没有问题,但是一旦出现 int* pInt = (int*)malloc(100 * sizeof(char)) 就很可能带来一些问题,而这样的转换 C 并不会提示错误。
C++ 类型安全#
如果 C++ 使用得当,它将远比 C 更有类型安全性。相比于 C 语言,C++ 提供了一些新的机制保障类型安全:
- 操作符 new 返回的指针类型严格与对象匹配,而不是
void* - C 中很多以
void*为参数的函数可以改写为 C++ 模板函数,而模板是支持类型检查的 - 引入
const关键字代替#define constants,它是有类型、有作用域的,而#define constants只是简单的文本替换 - 一些
#define宏可被改写为inline函数,结合函数的重载,可在类型安全的前提下支持多种类型,当然改写为模板也能保证类型安全 - C++ 提供了
dynamic_cast关键字,使得转换过程更加安全,因为dynamic_cast比static_cast涉及更多具体的类型检查
40. 内联函数 inline 和宏定义 define 的区别?#
- 在使用时,宏只做简单字符串替换(预处理,即编译前);而内联函数可以进行参数类型检查(编译时),且具有返回值
- 内联函数在编译时直接将函数代码嵌入到目标代码中,省去函数调用的开销来提高执行效率,并且进行参数类型检查,具有返回值,可以实现重载
- 宏定义时要注意书写(参数要括起来)否则容易出现歧义,内联函数不会产生歧义
- 内联函数有类型检测、语法判断等功能,而宏没有
内联函数适用场景:
- 使用宏定义的地方都可以使用 inline 函数
- 作为类成员接口函数来读写类的私有成员或者保护成员,会提高效率
41. 什么是大小端存储,以及如何用代码判断大小端?#
大端存储:字数据的高字节存储在低地址中
小端存储:字数据的低字节存储在低地址中
例如:32bit 的数字 0x12345678
所以在 Socket 编程中,往往需要将操作系统所用的小端存储的 IP 地址转换为大端存储,这样才能进行网络传输
小端模式中的存储方式为

大端模式中的存储方式为

了解了大小端存储的方式,如何在代码中进行判断呢?
#include <iostream>
using namespace std;
int main()
{
int a = 0x1234;
//由于 int 和 char 的长度不同,借助 int 型转换成 char 型,只会留下低地址的部分
char c = (char)(a);
if (c == 0x12)
cout << "big endian" << endl;
else if(c == 0x34)
cout << "little endian" << endl;
}42. C++ 中有几种类型的 new?#
(1) plain new#
言下之意就是普通的new,就是我们常用的new,在C++中定义如下:
void* operator new(std::size_t) throw(std::bad_alloc);
void operator delete(void *) throw();因此 plain new 在空间分配失败的情况下,抛出异常 std::bad_alloc 而不是返回 NULL,因此通过判断返回值是否为 NULL 是徒劳的。
(2) nothrow new#
nothrow new 在空间分配失败的情况下是不抛出异常,而是返回 NULL,定义如下:
void * operator new(std::size_t, const std::nothrow_t&) throw();
void operator delete(void*) throw();(3) placement new#
字节校招问题:placement new 是什么?
- 一般来说,使用 new 申请空间时,是从系统的“堆”中分配空间。申请所得的空间的位置是根据当时的内存的实际使用情况决定的。但是,在某些特殊情况下,可能需要在已分配的特定内存创建对象,这就是所谓的 “定位放置 new” (
placement new)操作。 定位放置 new 操作的语法形式不同于普通的 new 操作。例如,一般都用如下语句A* p = new A;申请空间,而 placement new 操作则使用如下语句A* p = new (ptr)A;申请空间,其中ptr就是程序员指定的内存首地址。- 用定位放置 new 操作,既可以在栈(stack)上生成对象,也可以在堆(heap)上生成对象,如本例就是在栈上生成一个对象。
- 优势:复用已有内存空间;
- 场景题:如果有这样一个场景,我们需要大量的申请一块类似的内存空间,然后又释放掉,比如在一个 Server 中对于客户端的请求,每个客户端的每一次上行数据我们都需要为此申请一块内存,当我们处理完请求给客户端下行回复时释放掉该内存,表面上看者符合 C++ 的内存管理要求,没有什么错误,但是仔细想想很不合理,为什么我们每个请求都要重新申请一块内存呢,要知道每一次内存的申请,系统都要在内存中找到一块合适大小的连续的内存空间,这个过程是很慢的(相对而言),极端情况下,如果当前系统中有大量的内存碎片,并且我们申请的空间很大,甚至有可能失败。为什么我们不能共用一块我们事先准备好的内存呢?可以的,我们可以使用
placement new来构造对象,那么就会在我们指定的内存空间中构造对象。
这种 new 允许在一块已经分配成功的内存上重新构造对象或对象数组。placement new 不用担心内存分配失败,因为它根本不分配内存,它做的唯一一件事情就是调用对象的构造函数。定义如下:
void* operator new(size_t, void*);
void operator delete(void*, void*);使用 placement new 需要注意两点:
- palcement new 的主要用途就是反复使用一块较大的动态分配的内存来构造不同类型的对象或者他们的数组
- placement new 构造起来的对象数组,要显式的调用他们的析构函数来销毁(析构函数并不释放对象的内存),千万不要使用
delete,这是因为 placement new 构造起来的对象或数组大小并不一定等于原来分配的内存大小,使用 delete 会造成内存泄漏或者之后释放内存时出现运行时错误
#include <iostream>
#include <string>
using namespace std;
class ADT {
int i;
int j;
public:
ADT() {
i = 10;
j = 100;
cout << "ADT construct i=" << i << " j="<<j <<endl;
}
~ADT() {
cout << "ADT destruct" << endl;
}
};
int main() {
char *p = new(nothrow) char[sizeof ADT + 1];
if (p == NULL) {
cout << "alloc failed" << endl;
}
ADT *q = new(p) ADT; //placement new:不必担心失败,只要p所指对象的的空间足够ADT创建即可
//delete q;//错误!不能在此处调用delete q;
q->ADT::~ADT();//显示调用析构函数
delete[] p;
return 0;
}
//ADT construct i=10 j=100
//ADT destruct43. C++ 11 新特性有哪些?#
- 自动类型推导(
auto关键字):编译器可根据变量初始化表达式自动推导其类型,简化代码编写。 decltype关键字:用于获取表达式的类型,常与auto结合使用,以推导复杂类型。- 右值引用和移动语义、
move函数:通过右值引用(&&)支持移动构造和移动赋值,提高资源管理和程序性能。 - 初始化列表:引入统一的列表初始化语法,允许使用花括号对变量进行初始化,增强初始化的灵活性和可读性。
nullptr关键字:引入新的空指针常量,替代原有的NULL,提高类型安全性。- 强类型枚举(
enum class):提供作用域限定的枚举类型,避免与其他标识符冲突,并增强类型安全性。 constexpr关键字:允许在编译期计算常量表达式,提高程序效率。- Lambda 表达式:支持匿名函数,方便定义内联的回调或操作,简化代码结构。
- 范围
for循环:引入基于范围的for循环,简化对容器或数组的遍历操作。 - 智能指针:新增
std::unique_ptr和改进的std::shared_ptr,提供安全的资源管理机制,减少内存泄漏风险。 - 线程支持库:标准库中加入多线程支持,包括线程管理、互斥量、条件变量等,方便进行并发编程。
std::tuple:提供固定大小的多元组,允许存储多个不同类型的值,增强数据结构的表达能力。- 正则表达式库:标准库新增正则表达式支持,方便进行字符串匹配和处理。
std::array:提供固定大小的数组封装,结合了数组的性能和容器的功能性。std::unordered_map和std::unordered_set:新增无序关联容器,基于哈希表实现,提供平均常数时间的查找和插入性能。std::chrono时间库:引入时间处理库,提供时钟、时间点、时间间隔等功能,方便进行时间相关的操作。static_assert:在编译期进行断言检查,确保代码满足特定条件,提高代码的可靠性。std::function和std::bind:提供通用的函数包装器和绑定器,支持函数对象、成员函数和自由函数的统一调用。- 用户定义字面量:允许为标准类型和自定义类型定义字面量后缀,增强代码的可读性和表达能力。
alignas和alignof关键字:提供对齐控制和查询功能,确保数据在内存中的对齐方式符合特定要求。explicit关键字:体现显示转换和隐式转换上的概念要求std::atomic<T>是 C++11 引入的原子类型,用于在多线程中安全地读写变量- 还有虚函数
override、容器非成员函数swap、新的bitset位运算…
44. C++ class 与 C struct 的区别?#
C 语言不支持继承和多态
1️⃣ 默认访问权限不同
- C
struct默认权限为 public - C++
class默认权限为 private - C++
struct默认权限 public
2️⃣ 成员函数
- C++ 中的
struct和class都可包含成员函数 - C 中的
struct只能包含数据,不能包含成员函数
C++ 的 class 与 struct 都支持模板、虚函数、多态、构造函数、析构函数、重载操作符等高级特性,这些都是 C 中 struct 不具备的功能。
以上谈论的是 C struct 和 C++ class 的区别,接下来聊一聊 C++ struct 和 C++ class 的区别。
在 C++ 中,class 和 struct 的功能几乎是等价的(除了默认访问权限不同),继承时:
- struct 的继承默认是 public 继承
- class 的继承默认是 private 继承
通常情况下,如果类主要用于表示数据结构,不需要封装和访问控制,且所有成员均为 public,则常用 struct;如果强调封装、访问控制,需要私有或受保护成员时,则倾向于用 class。
45. 怎么优化系统性能#
- 合理使用缓存机制,如内存缓存、Redis 等
- 利用多线程或多进程技术,让更多的处理器核心参与计算,提升吞吐量
- 选择高效的算法和数据结构可以显著提升系统性能
- 编写高质量的代码,避免冗余计算,减少函数调用和内存分配,合理使用同步和异步操作
- 采用集群等高可用架构,避免单点故障,确保系统在高负载下仍能稳定运行
- 负载均衡,通过将请求分配到多台服务器上,避免单一服务器的性能瓶颈
- 使用消息队列实现高并发下的异步处理,削峰填谷,缓解系统压力
perf工具查看系统性能瓶颈- 开启编译优化
-O2、-O3
以下展开介绍几个主要的优化点。
内存管理优化#
减少内存分配与释放次数: 频繁的堆内存分配和释放会严重拖慢程序,甚至导致内存碎片。应尽量重用对象、使用内存池等技术来降低分配开销。例如,在 C++ 中可以实现对象池,预先分配一定数量的对象,在需要时复用它们而不是每次 new 和 delete。对于生命周期较短且数量巨大的对象,尽可能分配在栈上而非堆上,因为栈上的分配/回收开销远小于堆(注意栈有大小限制,过大的对象还是要放在堆上)。在 Java/Python 等有垃圾回收的语言中,无法手动管理内存,但可以通过减少不必要的临时对象创建来减轻 GC 压力。
避免不必要的数据拷贝:数据拷贝不仅耗费 CPU 时间,还增加内存占用。在C/C++中,尽量通过指针、引用传递大对象,或使用移动语义(std::move)来避免昂贵的深拷贝。例如,将函数参数改为 const std::vector<T>& 引用而不是传值,可以省去一遍拷贝的成本。
提高内存访问局部性: 尽量使用连续内存的数据结构,有利于 CPU 缓存命中率。例如,相比链表,数组或动态数组(如 std::vector)在遍历时连续访问内存,对缓存更友好。访问内存时,如果数据分散,CPU缓存无法有效预取,性能会下降。因此,应尽量使常用的数据在内存中连续存放。对于需要处理大批量数据的场景,可以考虑将“数组的结构”转变为“结构的数组”以提高向量化和缓存性能。这种优化在需要对大量对象的某个字段进行批量操作时特别有效,因为连续的内存布局可以充分利用 SIMD 指令和缓存行。
控制内存使用与回收: 注意避免内存泄漏和不必要的内存占用。未释放的内存不仅浪费资源,还可能导致系统频繁进行垃圾回收或交换,从而严重影响性能。应使用恰当的数据结构来节省内存,例如在需要存储大量布尔值时使用位图/位集而不是布尔数组。
I/O 优化#
尽量减少 I/O 调用次数: 外部I/O(磁盘读写、网络通信)往往比内存操作慢几个数量级。优化I/O的一个基本原则是减少系统调用频次。例如,与其逐字节写入文件,不如积累一定数据后一次写入(批处理);读文件时尽量使用批量读取或流式读取来降低调用开销。将零散的小I/O操作合并为较少的几次大操作,可以大幅降低每次调用的固定成本,提高总体吞吐量。
使用缓冲和缓存:
- 缓冲是在内存中暂存数据,凑够一定量再进行 I/O
- 缓存则是将经常访问的数据暂存内存,以避免重复从慢速存储获取
异步和并行 I/O: 传统同步I/O会阻塞执行线程,等待操作完成。通过异步 I/O,程序可以在等待I/O的同时去处理其他任务,从而提高整体效率和响应性。另外,对于磁盘 I/O 密集型任务,合理利用操作系统的内存映射文件(mmap)也能提升效率,因为操作系统会自动预读和缓存文件内容,且内存映射减少了用户态/内核态的数据拷贝。
性能分析与瓶颈定位#
在展开具体优化工作之前,识别性能瓶颈是关键的一步。盲目优化往往事倍功半,甚至优化了非瓶颈部分而徒增代码复杂度。因此建议利用各种分析工具(Profiler)来定位程序中的“热区”和问题点。
- CPU Profiling:常用 GNU gprof 工具对应用程序进行采样分析,生成函数级别的耗时报告。在Linux上可以使用
perf工具对程序采集更底层的性能数据(如CPU周期、缓存未命中等)。跨平台的工具如 Intel VTune, AMD uProf 提供更高级的性能分析(包括线程并发、微架构瓶颈)。另外,Valgrind 的 Callgrind 模块也能分析代码热点和调用关系,并可借助KCachegrind等可视化工具查看分析结果。 - 内存和资源分析:使用 Valgrind 的 Memcheck 工具可以检测内存泄漏和非法内存访问,这有助于消除由于内存问题导致的异常行为和性能下降。Massif 是 Valgrind 的堆分析器,可以跟踪程序堆内存使用随时间的变化,找出高峰时占用大的代码路径。对于更复杂的内存分析,可以借助 Google Perf Tools(gperftools)中的 heap profiler 或 Dr. Memory 等工具。在需要分析缓存行为时,Valgrind 的 Cachegrind 模块可以模拟CPU缓存,报告缓存命中率,帮助调整数据结构以提高缓存友好度。
46. 说说移动构造函数与拷贝构造函数#
- 我们用对象 a 初始化对象 b,之后对象 a 我们就不再使用了,但是对象 a 的空间还在(在析构之前),既然拷贝构造函数实际上就是把 a 对象的内容复制一份到 b 中,那么为什么我们不能直接使用 a 的空间呢?这样就避免了新的空间的分配,大大降低了构造的成本。这就是移动构造函数设计的初衷。
- ‼️拷贝构造函数中,对于指针,我们一定要采用深拷贝;而移动构造函数中,对于指针,我们采用浅拷贝。
- 移动构造函数的参数
&&和拷贝构造函数&不同:拷贝构造函数的参数是一个左值引用,但是移动构造函数的初值是一个右值引用。意味着,移动构造函数的参数是一个右值或者将亡值的引用。也就是说,只用一个右值或者将亡值初始化另一个对象的时候,才会调用移动构造函数。而那个move()语句,就是将一个左值变成一个将亡值。
#include <iostream>
#include <string>
class MyString {
public:
// 构造函数
MyString() : str(nullptr), len(0) {}
// 构造函数
MyString(const char* s) : str(nullptr), len(0) {
if (s != nullptr) {
len = strlen(s);
str = new char[len + 1];
strcpy(str, s);
}
}
// 拷贝构造函数: 有指针则采用深拷贝
MyString(const MyString& other) : str(nullptr), len(0) {
if (other.str != nullptr) {
len = other.len;
str = new char[len + 1];
strcpy(str, other.str);
}
}
// 移动构造函数: 采用浅拷贝
MyString(MyString&& other) noexcept {
str = other.str;
len = other.len;
other.str = nullptr;
other.len = 0;
}
// 析构函数
~MyString() {
if (str != nullptr) {
delete[] str;
str = nullptr;
len = 0;
}
}
private:
char* str;
size_t len;
};
int main() {
MyString s1("Hello"); // 调用构造函数
MyString s2(s1); // 调用拷贝构造函数
MyString s3(std::move(s1)); // 调用移动构造函数
return 0;
}47. C++ 中指针参数传递和引用参数传递有什么区别?底层原理是什么?#
恍然大悟
(1) 指针参数传递本质上是值传递,它所传递的是一个地址值#
值传递过程中,被调函数的形式参数作为被调函数的局部变量处理,会在栈中开辟内存空间以存放由主调函数传递进来的实参值,从而形成了实参的一个副本(替身)。
值传递的特点是,被调函数对形式参数的任何操作都是作为局部变量进行的,不会影响主调函数的实参变量的值(即使是形参指针地址变了,实参指针地址都不会变)。
#include <iostream>
using namespace std;
void changePointer(int* ptr) {
int b = 20;
ptr = &b; // 仅改变了形参指针的指向,实参指针不变
}
int main() {
int a = 10;
int* p = &a;
cout << "Before function call: " << *p << endl; // 输出 10
changePointer(p);
cout << "After function call: " << *p << endl; // 仍然输出 10,不是 20
return 0;
}(2) 引用参数传递过程中,被调函数的形式参数也作为局部变量在栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址#
被调函数对形参(本体)的任何操作都被处理成间接寻址,即通过栈中存放的地址访问主调函数中的实参变量(根据别名找到主调函数中的本体)。
因此,被调函数对形参的任何操作都会影响主调函数中的实参变量。
二者区别#
1) 引用传递和指针传递是不同的,虽然他们都是在被调函数栈空间上的一个局部变量:
- 但是任何对于引用参数的处理都会通过一个间接寻址的方式操作到主调函数中的相关变量。
- 而对于指针传递的参数,如果改变被调函数中的指针地址,它将应用不到主调函数的相关变量。🔥 如果想通过指针参数传递来改变主调函数中的相关变量(地址),那就得使用指向指针的指针或者指针引用。
2) 从编译的角度来讲,程序在编译时分别将指针和引用添加到符号表上,符号表中记录的是变量名及变量所对应地址。
- 指针变量在符号表上对应的地址值为指针变量的地址值,而引用在符号表上对应的地址值为引用对象的地址值(与实参名字不同,地址相同)。
- 符号表生成之后就不会再改,因此指针可以改变其指向的对象(指针变量中的值可以改),而引用对象则不能修改。
48. C++ 中类成员的访问权限和继承权限问题#
访问权限#
① public: 用该关键字修饰的成员表示公有成员,该成员不仅可以在类内可以被访问,在类外也是可以被访问的,是类对外提供的可访问接口;
② private: 用该关键字修饰的成员表示私有成员,该成员仅在类内可以被访问,在类体外是隐藏状态;
③ protected: 用该关键字修饰的成员表示保护成员,保护成员在类体外同样是隐藏状态,但是对于该类的派生类来说,相当于公有成员,在派生类中可以被访问。
继承方式#
① 若继承方式是 public,基类成员在派生类中的访问权限保持不变,也就是说,基类中的成员访问权限,在派生类中仍然保持原来的访问权限;
② 若继承方式是 private,基类所有成员在派生类中的访问权限都会变为私有 (private) 权限;
③ 若继承方式是 protected,基类的共有成员 public 和保护成员 protected 在派生类中的访问权限都会变为保护 (protected) 权限,私有成员在派生类中的访问权限仍然是私有 (private) 权限。
49. 定义与声明的区别#
如果是指「变量」的声明和定义:
- 从编译原理上来说,声明是仅仅告诉编译器,有个某类型的变量会被使用,但是编译器并不会为它分配任何内存。
- 而定义就是分配了内存。
如果是指「函数」的声明和定义:
- 声明:一般在头文件里,对编译器说我有一个函数叫
function()让编译器知道这个函数的存在。 - 定义:一般在源文件里,具体就是函数的实现过程写明函数体。
50. 你知道 strcpy 与 memcpy 的区别吗#
1、复制的内容不同:
strcpy只能复制字符串- 而
memcpy可以复制任意内容,例如字符数组、整型、结构体、类等
2、复制的方法不同:
strcpy不需要指定长度,它遇到被复制字符的串结束符"\0"才结束,所以容易溢出memcpy则是根据其第 3 个参数决定复制的长度。
3、用途不同:
- 通常在复制字符串时用
strcpy - 而需要复制其他类型数据时则一般用
memcpy
51. volatile 关键字的作用#
面试回答#
volatile 的意思是“脆弱的”,表明它修饰的变量的值十分容易被改变,所以编译器就不会对这个变量进行优化(CPU 的优化是让该变量存放到 CPU 寄存器而不是内存),进而提供稳定的访问。每次读取 volatile 的变量时,系统总是会从内存中读取这个变量,并且将它的值立刻保存。
解释#
C/C++ 中的 volatile 关键字和 const 对应,用来修饰变量,通常用于建立语言级别的 memory barrier。
volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如:操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。声明时语法:int volatile vInt; 当要求使用 volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存。
#include <stdio.h>
void main()
{
volatile int i = 10;
int a = i;
printf("i = %d", a);
__asm {
mov dword ptr [ebp-4], 20h
}
int b = i;
printf("i = %d", b);
}i = 10
i = 32 // 如果没有 volatile 关键字修饰则该值为 10✅ volatile 用在如下的几个地方:
- 中断服务程序中修改的供其它程序检测的变量需要加 volatile。
- 多任务环境下各任务间共享的标志应该加 volatile:当两个线程都要用到某一个变量且该变量的值会被改变时,应该用 volatile 声明,该关键字的作用是防止优化编译器把变量从内存装入 CPU 寄存器中。如果变量被装入寄存器,那么两个线程有可能一个使用内存中的变量,一个使用寄存器中的变量,这会造成程序的错误执行。volatile 的意思是让编译器每次操作该变量时一定要从内存中真正取出,而不是使用已经存在寄存器中的值。
- 存储器映射的硬件寄存器通常也要加 volatile 说明,因为每次对它的读写都可能有不同意义。
52. 如果有一个空类,它会默认存在哪些函数?#
Empty(); // 缺省构造函数 //
Empty( const Empty& ); // 拷贝构造函数 //
~Empty(); // 析构函数 //
Empty& operator=( const Empty& ); // 赋值运算符 //53. const char* 与 string 之间的区别#
string 是 C++ 标准库里面其中一个,封装了对字符串的操作,实际操作过程我们可以用 const char* 给 string 类初始化。
三者之间的转化关系如下:
// 1. string 转 const char*
string s = “abc”;
const char* c_s = s.c_str();
// 2. const char* 转 string, 直接赋值即可
const char* c_s = “abc”;
string s(c_s);
// 3. string 转 char*
string s = “abc”;
const int len = s.length();
char* c;
c = new char[len + 1];
strcpy(c, s.c_str());
// 4. char* 转 string, 直接赋值即可
char* c = “abc”;
string s(c);
// 5. const char* 转 char*
const char* cpc = “abc”;
char* pc = new char[strlen(cpc) + 1];
strcpy(pc, cpc);
// 6. char* 转 const char*, 直接赋值即可
char* pc = “abc”;
const char* cpc = pc;54. static_cast 比 C 语言中的转换好在哪里?#
- 更加安全;
- 更直接明显,能够一眼看出是什么类型转换为什么类型,容易找出程序中的错误;可清楚地辨别代码中每个显式的强制转;可读性更好,能体现程序员的意图。
55. delete 和 delete[] 区别?#
delete只会调用一次析构函数。delete[]会调用数组中每个元素的析构函数。
56. 为什么不把所有函数写成内联函数?#
内联函数以代码复杂为代价,它以省去函数调用的开销来提高执行效率。所以一方面如果内联函数体内代码执行时间相比函数调用开销较大,则没有太大的意义;另一方面每一处内联函数的调用都要复制代码,消耗更多的内存空间,因此以下情况不宜使用内联函数:
- 函数体内的代码比较长,将导致内存消耗代价
- 函数体内有循环,函数执行时间要比函数调用开销大
57. 哪些函数不能是虚函数?#
- 构造函数:构造函数初始化对象,派生类必须知道基类函数干了什么,才能进行构造;当有虚函数时,每一个类有一个虚表,每一个对象有一个虚表指针,虚表指针在构造函数中初始化。
- 内联函数:内联函数表示在编译阶段进行函数体的替换操作,而虚函数意味着在运行期间进行类型确定,所以内联函数不能是虚函数。
- 静态函数:静态函数不属于对象属于类,静态成员函数没有 this 指针,因此静态函数设置为虚函数没有任何意义。
- 友元函数:友元函数不属于类的成员函数,不能被继承。对于没有继承特性的函数没有虚函数的说法。
- 普通函数:普通函数不属于类的成员函数,不具有继承特性,因此普通函数没有虚函数。
58. 什么原因造成内存泄露,你怎么避免/解决内存泄露?#
1️⃣ 什么是内存泄露?#
在程序运行过程中不再使用的对象没有被正确释放,从而导致程序使用的内存不断增加,最终导致程序异常退出或内存分配失败。
2️⃣ 什么原因造成内存泄露?#
- 忘记释放内存:分配了内存但没有释放
- 异常 / 逻辑处理不当:写了内存释放代码,但最后未执行到
- 循环引用:使用智能指针 shared_ptr 造成内存泄露
3️⃣ 如何避免/解决内存泄露 ‼️#
内存泄露一般是因为分配了内存但没有释放,要解决这个问题,我通常从以下几个层面入手:
- 我会用 RAII 机制管理资源(构造时分配,析构时释放)
- 能用智能指针(
unique_ptr,shared_ptr)的地方绝不手动new/delete,同时要注意避免循环引用(使用弱引用) - 对于资源管理比较复杂的类,我会写好析构函数,并考虑拷贝/移动语义,防止资源重复释放或泄露
- 正确捕获处理异常 / 回滚式编程:编写异常安全的代码非常困难
解决内存泄露本质上就是:该释放的要释放,生命周期清楚,用好工具,写好代码。我平时更倾向于用智能指针来管理资源,基本上能从根上避免大部分内存泄露问题。
4️⃣ 如何定位内存泄露#
🔗参考链接:
- 静态检测工具:检查代码中是否出现内存泄露,
- cppcheck
- clang-tidy
valgrind- 需要调试信息
-g valgrind --leak-check=full可执行程序- 可视 valgrind 为虚拟机,将可执行程序当作文件来处理,读取二进制文件的内容,进行指令解析并执行
- 需要调试信息
hook+backtrace:侵入式(可能会引起程序异常)- hook 住内存分配和释放接口
- 每次申请内存都记录一下,每次释放时也记录一下,然后再把这两种记录进行一个对比,把相同的去掉,剩下就是
eBPF+uprobes:非侵入式(内核中进行统计,不会影响程序)- 不需要调试信息
- 原理与上一种相同,但是不是侵入式,运行在内核
59. C++ 写了析构函数,系统会帮我们生成默认移动构造函数这些吗(介绍 C++ 六个特殊成员函数)#
写了析构函数,系统可能不再自动生成“移动构造”和“移动赋值”函数了,但拷贝构造和拷贝赋值通常还是会生成的。
在 C++ 里,有六个所谓的“特殊成员函数”:
- 默认构造函数
MyClass() - 析构函数
~MyClass() - 拷贝构造函数
MyClass(const MyClass& other) - 拷贝赋值函数
MyClass& operator=(const MyClass& other) - 移动构造函数(C++11 起)
MyClass(MyClass&& other) noexcept - 移动赋值函数(C++11 起)
MyClass& operator=(MyClass&& other) noexcept
如果你自己写了一个析构函数,那编译器就认为你要自己管理资源了。所以出于安全考虑,它不会再自动生成移动构造函数和移动赋值函数了,你得自己写,或者用 = default 显式声明。
MyClass(MyClass&&) = default;
MyClass& operator=(MyClass&&) = default;60. C++ 右值引用和移动拷贝(赋值)函数的作用#
右值引用和移动语义是在 C++11 之后引入的,目的是优化性能,避免不必要的资源拷贝。
以前在 C++98 里,如果你把一个对象传给另一个对象,哪怕那个对象马上就要销毁了,编译器也只能做拷贝,哪怕里面的数据非常大,比如堆上几百 MB 的数组,也得老老实实拷贝一份,非常浪费性能。
而右值引用的出现,让编译器能识别出“这是一个临时对象”,你可以放心地把它的资源“抢过来”用,而不是复制一份。
移动构造函数 MyClass(MyClass&& a) noexcept 和移动赋值操作符 MyClass& operator=(MyClass&& a) noexcept 的作用就是:
- 移动构造:当一个临时对象要变成另一个对象时,直接“接管”它的内部资源,比如把指针地址拿过来,然后把原对象的指针清空,这样就不需要重新分配和复制内存。
- 移动赋值:和移动构造类似,不过是用于对象已经存在的情况下,把另一个临时对象的资源拿过来,原来的资源先释放,然后再接管。
61. C++ 线程 thread_local 的作用是什么?#
它是线程单独拥有的资源,没办法作为共享资源
thread_local 是 C++11 引入的存储类型说明符,用于为每个线程创建独立的变量副本。
使用场景:
- 每个线程都需要使用一个自己的变量(如缓存、计数器等),避免同步。
- 类似于线程的“全局变量”,但互不干扰。
示例:
thread_local int counter = 0;✅ 示例场景:日志系统中用 thread_local 缓存上下文
在多线程程序中,很多系统会给每个线程维护一份独立的日志信息,比如线程 ID、调用栈、临时日志缓存等。如果所有线程都用一个共享变量,会导致锁竞争、效率低下。
这时候就可以用 thread_local 给每个线程一份独立副本!
#include <iostream>
#include <thread>
#include <string>
class Logger {
public:
static void log(const std::string& message) {
log_context += message + "\n";
}
static void flush() {
std::cout << "[Thread " << std::this_thread::get_id() << "]\n";
std::cout << log_context << std::endl;
log_context.clear();
}
private:
static thread_local std::string log_context; // 每个线程一份
};
thread_local std::string Logger::log_context;
void thread_task(int id) {
Logger::log("Start work in thread " + std::to_string(id));
Logger::log("Doing some work...");
Logger::log("Finish work in thread " + std::to_string(id));
Logger::flush();
}
int main() {
std::thread t1(thread_task, 1);
std::thread t2(thread_task, 2);
t1.join();
t2.join();
return 0;
}62. 如何定义一个只能在堆上(栈上)生成对象的类?#
只能在堆上#
方法:将析构函数设置为私有
原因:C++ 是静态绑定语言,编译器管理栈上对象的生命周期,编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性。若析构函数不可访问,则不能在栈上创建对象。
只能在栈上#
方法:将 new 和 delete 重载为私有
原因:在堆上生成对象,使用 new 关键词操作,其过程分为两阶段:第一阶段,使用 new 在堆上寻找可用内存,分配给对象;第二阶段,调用构造函数生成对象。将 new 操作设置为私有,那么第一阶段就无法完成,就不能够在堆上生成对象。
63. 递归过深会造成什么问题,OOM 吗?#
递归过深确实可能引发一些严重问题,但不一定是 OOM(Out of Memory)。更常见的问题是栈溢出(Stack Overflow)。
✅ 栈溢出(Stack Overflow)
- 每次函数调用都会在调用栈上分配一块内存来保存函数的执行上下文(如局部变量、返回地址等)。
- 如果递归层级太深,调用栈不断增长,最终会超过系统分配给程序的栈空间上限(跟默认「线程栈」大小相关)。
- 此时程序会抛出 StackOverflowError(Java) 或 Segmentation Fault(C/C++),或者 RecursionError(Python)。
❌ 而不是 OOM(Out of Memory)
- OOM 通常是指 堆内存 耗尽,例如大量创建对象、数组或内存泄漏。
- 除非每层递归都分配了大量堆内存(比如在每层递归里 new 很大的对象),否则递归本身并不会直接造成 OOM。
递归过深导致的栈溢出,和线程的栈大小直接相关:每个线程在启动时,操作系统会为它分配一块固定大小的栈内存(线程栈),专门用于保存函数调用帧,如果递归太深,每层调用都占用一点栈空间,栈就会被用完,最终导致栈溢出。线程栈大小是有限的,不同语言/平台有不同的默认值如下:
- Java 一般是 1MB(可通过
-Xss参数设置) - Linux 上的原生线程(如
pthread)默认栈大小通常是 8MB - Python 受限于解释器的默认递归深度(
sys.getrecursionlimit())
64. 如何获取前 K 个最大元素?#
这个问题是数据结构与算法中的经典题目之一,常用于考察排序、堆、优先队列的应用。以下是几种常见的解法及其时间复杂度分析:
解法一:排序法(适合数据量不大)#
思路:
- 直接对数组进行排序
- 取前 K 个元素
#include <vector>
#include <algorithm>
std::vector<int> topKSort(std::vector<int>& nums, int k) {
std::sort(nums.begin(), nums.end(), std::greater<int>());
return std::vector<int>(nums.begin(), nums.begin() + k);
}时间复杂度:
- 排序时间复杂度:
O(n log n) - 空间复杂度:
O(1)
解法二:最小堆(推荐,适合大数据)#
思路:
- 使用大小为 K 的最小堆来保存当前最大的 K 个元素
- 遍历整个数组,若当前元素比堆顶大,则替换堆顶
#include <vector>
#include <queue>
std::vector<int> topKHeap(const std::vector<int>& nums, int k) {
if (k == 0)
return {};
std::priority_queue<int, std::vector<int>, std::greater<int>> minHeap;
for (int num : nums) {
if (minHeap.size() < k) {
minHeap.push(num);
} else if (num > minHeap.top()) {
minHeap.pop();
minHeap.push(num);
}
}
std::vector<int> result;
while (!minHeap.empty()) {
result.push_back(minHeap.top());
minHeap.pop();
}
std::sort(result.rbegin(), result.rend()); // 可选:从大到小排序
return result;
}时间复杂度:
- 时间复杂度:
O(n log k)- 构建堆:
O(k) - 遍历其余 个元素,每次
O(log k):总共O((n-k) log k)
- 构建堆:
- 空间复杂度:
O(k)
🔥 解法三:快排的思想(Top-K 问题,适合不要求完整排序)#
思路:
- 类似快速排序中的分区(partition),选定一个“枢轴”,将大于 pivot 的放左边,小于的放右边
- 不断递归,直到找到第 K 个最大的数为止
#include <vector>
#include <cstdlib> // for rand()
int partition(std::vector<int>& nums, int left, int right) {
int pivot = nums[right], i = left;
for (int j = left; j < right; ++j) {
if (nums[j] >= pivot) {
std::swap(nums[i], nums[j]);
++i;
}
}
std::swap(nums[i], nums[right]);
return i;
}
void quickSelect(std::vector<int>& nums, int left, int right, int k) {
if (left >= right)
return;
int pivotIndex = partition(nums, left, right);
if (pivotIndex == k)
return;
else if (pivotIndex < k)
quickSelect(nums, pivotIndex + 1, right, k);
else
quickSelect(nums, left, pivotIndex - 1, k);
}
std::vector<int> topKQuickSelect(std::vector<int>& nums, int k) {
quickSelect(nums, 0, nums.size() - 1, k);
return std::vector<int>(nums.begin(), nums.begin() + k);
}时间复杂度:
- 平均:
O(n)- 最坏(退化成链表):
O(n^2)
- 最坏(退化成链表):
- 空间复杂度:
O(1)(递归栈不计)
✅ 总结对比#
| 方法 | 时间复杂度 | 空间复杂度 | 适用场景 |
|---|---|---|---|
| 排序法 | O(n log n) | O(1) | 数据量小,代码简单 |
| 最小堆 | O(n log k) | O(k) | 数据量大,k 远小于 n |
| 快速选择 | 平均 O(n) | O(1) | 不关心顺序,只要前 K 大 |
65. 堆和栈在操作系统底层的实现?#
堆与栈、进程虚拟内存空间分布#
【速度、安全】栈是用于管理函数调用、局部变量等的高效内存区域,由操作系统自动管理
【动态、灵活】堆是用于动态分配的内存区域,由程序员手动管理(或者通过垃圾回收机制管理 — java)
⚙️ 在 32 位机器上,进程虚拟内存空间分布如下:
栈为什么适合函数调用:严格的顺序性,嵌套调用不会乱。
递归调用过深,栈会发生什么:栈溢出、触发 SIGSEGV 信号,程序崩溃。
🔥 栈在操作系统底层的实现#
- 线程创建时,操作系统为其创建栈空间(默认 8 MB)—— 分成进程栈与线程栈
- 进程栈(主线程栈)在进程启动时创建
- 线程栈通过
pthread_create、clone系统调用创建
- 栈的使用:只需要移动栈指针
- 硬件支持:寄存器 x86 下
- 栈顶指针 rsp
- 栈底指针 rbp
- 操作系统管理:
- 函数调用时,先将参数压栈
- 执行 call 指令,将返回地址(返回上一级函数的下一条指令)压栈
- 创建栈帧,保存旧的 rbp,设置新的 rbp
- 可能为局部变量分配空间(清理局部变量等的栈空间)
- 恢复之前的 rbp 和 rsp,ret 指令弹出返回地址

🔥 堆在操作系统底层的实现#
本质为 malloc 机制:
- 当分配内存的大小 时,先从内存池获取,否则通过
brk系统调用从堆区分配内存,回收时则回收到内存池 - 当分配内存的大小 时,通过
mmap系统调用从文件映射区分配内存,回收时通过munmap释放内存
为什么栈的分配速度比堆快?#
栈只需要移动指针,堆需要查找空闲块、处理碎片和系统调用
多线程程序中,堆和栈如何隔离?#
栈是线程私有的,无需隔离;
堆是进程共享的,需同步机制如锁🔒
66. C++ mutable 关键字#
腾讯 wxg 一面
1️⃣ C++ mutable 用于修饰非静态成员函数,使得该成员变量可以在 const 成员函数中允许被修改
2️⃣ 同时也可以用于修饰 lambda 表达式,可以去掉函数调用操作符后 const 关键字,从而可以在 lambda 函数体内可以修改按值捕获的外部变量。
67. 详解内存对齐(如何 padding)及其原因#
腾讯 csig 一面
求 sizeof(S) 的大小并解析,以及为什么进行内存对齐。
struct B {
int b;
char c;
};
typedef struct {
int a;
char b;
short c;
char d;
B e;
} S;在 C/C++ 中,结构体的大小与成员排列不仅取决于每个成员的大小,还受到**内存对齐(Alignment)**的影响,具体规则如下:
- 每个成员变量的地址必须是其类型对齐大小(对齐边界)的整数倍。
- 结构体本身的总大小必须是其最大对齐单位的整数倍。
- 编译器会在必要的位置插入 **padding(填充字节)**来满足上述要求,以提高内存访问效率。
对结构体 S 的内存布局分析
- 结构体 B 的分析:
struct B {
int b; // 4 bytes, offset 0
char c; // 1 byte, offset 4
// padding 3 bytes to align struct B size to 8
};- 成员
int b对齐为 4 字节,偏移量为 0。 - 成员
char c占 1 字节,偏移量为 4。 - 为满足结构体
B总大小为最大对齐成员(4 字节)的倍数,需要在末尾添加 3 字节填充。
所以 sizeof(B) == 8
- 结构体 S 的分析:
typedef struct {
int a; // 4 bytes, offset 0
char b; // 1 byte, offset 4
// padding 1 byte, to align next 'short' to 2 bytes
short c; // 2 bytes, offset 6
char d; // 1 byte, offset 8
// padding 3 bytes, to align next 'B' to 4 bytes
B e; // 8 bytes, offset 12
} S;int a: 占 4 字节,从 offset 0 开始。char b: 占 1 字节,offset = 4。- padding 1 字节,使得
short c对齐到 2 的倍数(offset = 6)。
- padding 1 字节,使得
short c: 占 2 字节,offset = 6。char d: 占 1 字节,offset = 8。- padding 3 字节,使得结构体
B e对齐到 4 字节边界(offset = 12)。
- padding 3 字节,使得结构体
B e: 占 8 字节(因为sizeof(B) == 8),offset = 12。- 最后 offset = 12 + 8 = 20
因此: sizeof(S) == 20(假设最后总大小为 21 字节,需要 padding 到 24 字节)
68. *(int *)0 = 0 的含义?#
*(int *)0 = 0; 这行代码的意思是:将整数值 0 写入内存地址 0 所指向的地方,也就是将值 0 存储到内存的 地址 0。
(int *) 0:把整数 0 强转为int*类型的指针*(int *) 0:对地址0进行解引用,访问该地址存储的内容*(int *) 0 = 0:对地址0存储的内容赋值为0,试图写入值0到地址0
在几乎所有现代操作系统中,地址 0 是无效的地址,属于操作系统保留的内存区域。
尝试访问(特别是写入)地址 0 会导致段错误(Segmentation Fault),程序异常终止。
在某些低层次编程或嵌入式开发中,地址 0 可能用于特殊用途,但在普通用户态程序中,这样写没有任何合法理由,通常是:
- 故意制造崩溃(例如测试信号处理)。
- 调试用,或者模拟空指针解引用的错误。
- 考察面试者对指针、内存访问的理解(比如本题)。
69. 宏定义展开#
#define SQR(x) (x * x)
int main()
{
int a, b = 3;
a = SQR(b + 2);
printf("a = %d\n", a);
return 0;
}输出为 a = 11 而非 a = 25,宏展开后为 a = (b + 2 * b + 2),所以结果为 a = 11
70. 假设有一个位图数据结构定义为 uint32_t bitmap[BSIZE];,请写出用于判断位图中第 bit 位是否为 1 的如下宏的实现#
#define is_bit_set(bit) ((bitmap[(bit)/32] & (1U << ((bit)%32))) != 0)
解释:一个 uint32_t 只能表示 32 位,题目 bitmap 用的是 uint32_t 数组,所以采用 /32 找到在第几个 uint32_t 中,%32 找到在第几位。
71. 读写锁与读优先/写优先#
读写锁和传统互斥锁的区别在于,能支持多个读线程并发执行
在多线程编程中,读锁和写锁通常是配合**读写锁(读写互斥锁)**使用的,目的是在多个线程并发访问共享资源时提供更高的效率。简单来说,**读锁(共享锁)允许多个线程同时读取资源,但不允许写操作;而写锁(独占锁)**则是排他的,同一时间只能有一个线程持有写锁,且写锁期间不允许任何其他线程读或写这个资源。
这个机制的好处在于:在读多写少的场景下,我们不必像传统互斥锁那样每次都加排它锁,而是可以让多个读线程并发执行,提升性能。
具体的使用场景比如:
- 读锁适合的场景:多个线程同时查询一个共享缓存、配置文件、数据库快照等,数据是只读的,不会被修改。
- 写锁适合的场景:当某个线程需要更新缓存、修改配置或写入日志文件等操作时,为了避免其他线程读到不一致的数据,就需要加写锁。
在 C++ 中,像 std::shared_mutex 就是一个典型的读写锁实现,可以配合 std::shared_lock 和 std::unique_lock 分别实现读锁和写锁。
读/写优先是基于读写锁中的策略选择而已,不要搞混了
在使用读写锁时,读优先和写优先指的是当读线程和写线程同时竞争锁资源时,系统会优先允许哪一类线程先获取锁。
读优先的策略意味着:如果当前有读线程在读,或者有新的读线程请求读锁,就会优先满足它们,哪怕有写线程已经在等待。这种策略的好处是读性能非常高,适合“读远远多于写”的场景。但问题是如果读操作持续不断,写线程可能会长时间得不到执行,造成“写饥饿”。
写优先则反过来:一旦有写线程在等待,新的读线程就要等写线程先执行完。这种方式能保证写操作不会被饿死,但也意味着读线程可能会频繁被阻塞,尤其在写比较多时,整体并发度会下降。
还有一种是公平策略,就是无论读还是写,谁先请求谁先执行。这种方式平衡了读写,防止任何一方饿死,但也可能带来一点性能损耗。
实际使用中,选择哪种策略要看业务特点:
- 如果系统是典型的读多写少,比如缓存、配置系统,用读优先可以提升整体吞吐;
- 如果写操作比较关键,比如数据库更新或者日志记录,写优先更合适;
- 如果两者都重要,或者对延迟比较敏感,可以用公平策略。
C++ 标准库里的 std::shared_mutex 是不保证写优先的,如果确实要实现写优先或者公平策略,可能需要第三方库(比如 Boost)或者平台相关的原语。
72. 多线程之间是如何通信的?线程之间怎么交互的?#
<mutex>和<condition_variable>
答案就是条件变量
多线程之间的通信和交互主要是通过共享内存来实现的,也就是说多个线程可以访问同一个进程的内存空间,从而读写同一份数据。但因为线程可能同时访问同一块数据,会产生竞态条件,所以通常需要同步机制来保证数据的一致性和正确性。
常用的同步方式包括互斥锁(mutex)、读写锁(rwlock)、信号量(semaphore)、条件变量(condition variable)等,这些机制帮助线程协调访问顺序,防止数据冲突。
此外,线程间还可以通过消息队列、事件通知等方式传递信息,尤其在异步或生产者-消费者模式中常见。现代操作系统和语言运行时通常提供了丰富的线程同步和通信工具,确保线程间可以高效且安全地交互和协作。
73. 关于使用 == 比较 double 类型#
在 C++ 中处理double类型时,我们需要理解:
- 为什么不能直接用
==比较浮点数(浮点数为什么是近似存储的) - 如何正确比较浮点数
1. 为什么不能直接用 == 比较#
浮点数在计算机中的存储是近似值而非精确值,double 通常使用 64 位存储(1 符号位 + 11 指数位 + 52 尾数位),像 0.1 这样的十进制小数无法精确表示为二进制分数,存储时必须进行舍入(截断无限循环部分),导致微小误差。
#include <iostream>
#include <cmath>
#include <iomanip>
int main() {
double a = 0.1;
double b = 0.2;
double sum = a + b;
std::cout << std::setprecision(20);
std::cout << "0.1 in memory: " << a << std::endl;
std::cout << "0.2 in memory: " << b << std::endl;
std::cout << "0.1 + 0.2 = " << sum << std::endl;
std::cout << "0.3 in memory: " << 0.3 << std::endl;
return 0;
}输出可能类似于:
0.1 in memory: 0.10000000000000000555
0.2 in memory: 0.2000000000000000111
0.1 + 0.2 = 0.30000000000000004441
0.3 in memory: 0.2999999999999999889所以使用 == 比较是容易出错的。
#include <iostream>
int main() {
double x = 0.1 + 0.2;
double y = 0.3;
if (x == y) {
std::cout << "Exactly equal\n";
} else {
std::cout << "Not exactly equal\n"; // 通常会输出这个
}
return 0;
}2. 正确的浮点数比较方法#
绝对误差比较
#include <iostream>
#include <cmath>
#include <cfloat> // 对于 DBL_EPSILON
bool nearlyEqual(double a, double b, double absEpsilon = 1e-12) {
return std::fabs(a - b) <= absEpsilon;
}
int main() {
double x = 0.1 + 0.2;
double y = 0.3;
if (nearlyEqual(x, y)) {
std::cout << "Equal within tolerance\n"; // 会输出这个
} else {
std::cout << "Not equal\n";
}
return 0;
}3. 什么时候可以使用 == 直接比较#
在C++中,虽然大多数情况下不推荐直接用==比较浮点数,但在以下特定情况下可以安全使用(当你能 100% 确定数值来源和没有经过任何浮点运算时,才用==):
- 比较精确赋值的相同字面值
double a = 5.0;
double b = 5.0;
if (a == b) { /* 总是true */ }- 比较整数范围内的值
double x = 42.0; // 没有小数部分
double y = 42.0;
if (x == y) { /* 总是true */ }- 比较特殊浮点值
// 比较正负无穷大
double inf1 = std::numeric_limits<double>::infinity();
double inf2 = std::numeric_limits<double>::infinity();
if (inf1 == inf2) { /* 总是true */ }
// 比较零值
if (0.0 == -0.0) { /* 总是true,尽管符号不同 */ }- 比较编译期常量表达式:
constexpr double PI = 3.141592653589793;
constexpr double PI_2 = PI / 2;
if (PI_2 == 1.5707963267948966) { /* 编译期计算,总是true */ }- 比较未经过算术运算的相同变量:
double val = getValue(); // 假设返回固定值
if (val == val) { /* 检测NaN的惯用方法 */ }
// 如果val是NaN,这个条件会是false⚠️ 特别注意,以下情况绝不应该使用==:
// 经过算术运算的结果
if (0.1 + 0.2 == 0.3) { /* 可能false */ }
// 从不同计算路径得到的结果
double a = calculateA();
double b = calculateB();
if (a == b) { /* 危险 */ }
// 循环累积的结果
double sum = 0.0;
for (int i = 0; i < 10; ++i) {
sum += 0.1;
}
if (sum == 1.0) { /* 可能false */ }74. 堆与栈的优缺点比较#
栈 - Stack#
优点:
- 快速分配/释放:栈内存的分配和释放只是移动栈指针,速度快
- 自动管理:函数返回时自动释放,无需手动管理
- 缓存友好:栈数据通常位于缓存热点区域,访问速度快
- 不会产生碎片:严格的 LIFO 顺序避免了内存碎片问题
- 线程安全:每个线程有自己的栈,无需同步
缺点
- 大小有限:栈空间通常较小(几 MB),不适合大对象
- 生命周期固定:只能在函数调用期间存在,不能跨函数使用
- 灵活性差:无法动态调整大小,必须是编译时已知的大小
- 容易溢出:递归过深或大对象可能导致栈溢出(stack overflow)
堆 - Heap#
优点:
- 大容量:可用内存通常远大于栈空间
- 动态分配:可以在运行时决定分配大小和生命周期
- 全局可访问:分配的内存可以被程序任何部分访问
- 灵活性高:可以动态调整大小(如realloc)
- 适合大数据:能够处理大型数据结构
缺点:
- 分配速度慢:需要寻找合适的内存块,可能涉及系统调用
- 手动管理特性:堆内存需要显式分配 (
new/malloc) 和释放 (delete/free),存在内存泄漏风险 - 内存碎片:频繁分配释放可能导致碎片
- 同步开销:多线程环境下需要同步机制
- 缓存不友好:堆分配的数据可能分散在内存各处
使用建议#
- 优先使用栈:适合小型、短生命周期的数据
- 必要时用堆:大型数据或需要长生命周期时使用
75. 关于 shared_ptr 的注意事项(20. 智能指针)#
关于 shared_ptr 的注意事项:
-
不要用一个裸指针初始化多个
shared_ptr,会出现 double_free 导致程序崩溃 -
通过
shared_from_this()返回 this 指针,不要把 this 指针作为shared_ptr返回出来,因为this指针本质就是裸指针,通过 this 返回可能会导致重复析构,不能把 this 指针交给智能指针管理。 -
尽量使用
std::make_shared<T>(),少用new -
不要
deleteget()返回的裸指针 -
不是
new出来的空间要自定义删除器 -
要避免循环引用,循环引用导致内存永远不会被释放,造成内存泄漏(不在赘述)
1. 不要用一个裸指针初始化多个 shared_ptr(会导致 double free)#
问题场景:
int* raw_ptr = new int(42);
std::shared_ptr<int> sp1(raw_ptr);
std::shared_ptr<int> sp2(raw_ptr); // 危险!- 两个独立的
shared_ptr会各自维护一个引用计数控制块(相互独立) - 当
sp1和sp2销毁时都会尝试释放raw_ptr,导致 双重释放(double free) - 结果通常是程序崩溃或未定义行为
正确做法:
// 方法1:直接使用 make_shared
// make_shared 一次性分配内存,包含控制块(引用计数、弱引用计数等);对象存储空间(存储实际值 42)
auto sp1 = std::make_shared<int>(42);
auto sp2 = sp1; // 只是复制指针并增加引用计数,两个 shared_ptr 指向同一个控制块,共享所有权
// 方法2:如果必须从裸指针创建,确保只创建一次 shared_ptr
int* raw_ptr = new int(42);
std::shared_ptr<int> sp1(raw_ptr);
std::shared_ptr<int> sp2 = sp1; // 复制的是控制块指针,不是重新创建控制块,共享同一个控制块2. 正确使用 shared_from_this() 而不是直接返回 this 指针#
问题场景:
class BadExample {
public:
std::shared_ptr<BadExample> get_this() {
return std::shared_ptr<BadExample>(this); // 危险!
}
};
auto obj = std::make_shared<BadExample>();
auto another_ref = obj->get_this(); // 创建了独立的控制块- 这会创建两个独立的
shared_ptr控制块 - 当两个
shared_ptr销毁时都会尝试析构同一个对象
正确做法:
class GoodExample : public std::enable_shared_from_this<GoodExample> {
public:
std::shared_ptr<GoodExample> get_this() {
return shared_from_this(); // 安全
}
};
auto obj = std::make_shared<GoodExample>();
auto another_ref = obj->get_this(); // 共享同一个控制块3. 优先使用 std::make_shared<T>() 而不是 new#
问题场景:
// 不推荐
std::shared_ptr<MyClass> sp(new MyClass(arg1, arg2));
// 推荐
auto sp = std::make_shared<MyClass>(arg1, arg2);优势:
- 性能更好:单次内存分配(对象 + 控制块)
- 异常安全:不会在
new和shared_ptr构造之间发生泄漏 - 代码更简洁:不需要重复类型名称
- 缓存友好:对象和控制块内存相邻
例外情况:
- 需要自定义删除器时
- 需要指定特殊的内存分配方式时
4. 不要 delete get() 返回的裸指针#
问题场景:
auto sp = std::make_shared<int>(42);
int* raw_ptr = sp.get();
delete raw_ptr; // 灾难性错误!
// 当 sp 超出作用域时,会再次尝试删除已删除的内存shared_ptr仍然拥有内存所有权- 手动
delete会导致:- double free
- 控制块状态不一致
- 未定义行为(通常崩溃)
正确做法:
auto sp = std::make_shared<int>(42);
int* raw_ptr = sp.get();
// 仅使用 raw_ptr 进行读取/写入操作,绝不手动删除它5. 非 new 分配的内存需要自定义删除器#
问题场景:
// 从 malloc 分配的内存
void* mem = malloc(1024);
std::shared_ptr<void> sp(mem); // 错误!会用 delete 而不是 free
// 文件指针
FILE* fp = fopen("file.txt", "r");
std::shared_ptr<FILE> sp(fp); // 错误!会用 delete 而不是 fclose正确做法:
// 使用自定义删除器(lambda 表达式作为删除器)
void* mem = malloc(1024);
std::shared_ptr<void> sp(mem, free); // 使用 free 作为删除器
FILE* fp = fopen("file.txt", "r");
std::shared_ptr<FILE> sp(fp, [](FILE* f) { fclose(f); });
// 对于数组
int* arr = new int[10];
std::shared_ptr<int> sp(arr, [](int* p) { delete[] p; });常见删除器场景:
- C 风格内存分配(
malloc/calloc/realloc)→ 使用free - 文件操作(
fopen)→ 使用fclose - 系统资源(套接字、句柄等)→ 使用对应的释放函数
- 数组 → 使用
delete[]
6. 避免循环引用导致的内存泄露#
问题场景 1#
class A;
class B;
class A {
public:
std::shared_ptr<B> b;
};
class B {
public:
std::shared_ptr<A> a;
};
int main() {
std::shared_ptr<A> ap = std::make_shared<A>();
std::shared_ptr<B> bp = std::make_shared<B>();
ap->b = bp;
bp->a = ap;
// 此时,a 和 b 相互持有对方的 shared_ptr,形成循环引用
// 程序结束时,a 和 b 的引用计数都不会降为零,导致内存泄漏
return 0;
}问题场景 2#
class Node {
public:
std::shared_ptr<Node> next;
std::shared_ptr<Node> prev; // 双向链表导致循环引用
~Node() { std::cout << "Node destroyed\n"; }
};
auto node1 = std::make_shared<Node>();
auto node2 = std::make_shared<Node>();
node1->next = node2;
node2->prev = node1; // 循环引用形成!- 当
node1和node2离开作用域时:node1的引用计数从 1→0?不,因为node2->prev还持有引用(实际从 2→1)node2的引用计数同样从 2→1
- 结果:两者引用计数永远不为 0,内存永远不会释放
node1 [refcount=2] --> Node1对象
↑next ↓prev
Node2对象 <-- [refcount=2] node2解决方案:weak_ptr
class SafeNode {
public:
std::shared_ptr<SafeNode> next;
std::weak_ptr<SafeNode> prev; // 使用weak_ptr
~SafeNode() { std::cout << "SafeNode destroyed\n"; }
};
auto node1 = std::make_shared<SafeNode>();
auto node2 = std::make_shared<SafeNode>();
node1->next = node2;
node2->prev = node1; // weak_ptr不会增加引用计数何时会出现循环引用?#
- 双向链表、树结构等复杂数据结构
- 对象相互持有对方的
shared_ptr - 父子对象互相强引用
- 观察者模式中主体和观察者互相持有
76. std::shared_ptr 可以通过 std::make_shared 和直接使用 new 表达式构造,二者有什么区别?#
在 C++ 中,std::shared_ptr 可以通过 std::make_shared 和直接使用 new 表达式构造,但二者在内存管理、性能和异常安全性方面有显著区别:
// 推荐方式:高效且安全
auto sp1 = std::make_shared<int>(42);
// 不推荐:性能更低且可能泄漏
std::shared_ptr<int> sp2(new int(42));1. 内存分配方式#
-
make_shared:一次性分配内存,同时存储对象本身和控制块(引用计数等)。这是更高效的内存布局,减少了内存碎片和分配次数
cppauto sp = std::make_shared<Widget>(args...); // 单次分配 -
new+shared_ptr构造函数:需要两次内存分配,一次为对象(new),另一次为控制块(由shared_ptr构造函数触发)
cppstd::shared_ptr<Widget> sp(new Widget(args...)); // 两次分配
2. 性能差异#
make_shared更快:单次内存分配减少了开销,尤其当频繁创建/销毁shared_ptr时更明显。new额外开销:两次分配可能引入性能损耗(尤其是对小型对象)。
解释
每次 new/malloc 都是一次系统调用:操作系统需要查找合适的内存块、更新内存管理数据结构(如空闲链表),可能触发缺页中断或内核态切换,这些操作本身就有固定开销。两次分配就会有双倍开销。
从内存局部性角度来看:
make_shared的内存是连续的,对象和控制块在单块内存中紧密排列,缓存命中率更高。new的内存可能是分散的,对象和控制块位于不同内存区域,访问时可能触发多次缓存加载,同时产生更多内存碎片。
3. 异常安全性#
-
make_shared是异常安全的:若构造函数抛出异常,不会发生内存泄漏(因为内存已由智能指针系统托管)。
cppprocess(std::make_shared<Widget>(a, b), may_throw()); // 安全 -
new可能泄漏:如果new成功但shared_ptr构造前发生异常,对象不会被释放:
cppprocess(std::shared_ptr<Widget>(new Widget(a, b)), may_throw()); // 可能泄漏
4. 对象生命周期的影响#
make_shared的延迟释放:对象内存和控制块是连续的,即使引用计数归零,对象占用的内存可能直到控制块也被释放时才归还(例如弱引用weak_ptr仍存在时)。new的独立释放:对象内存和控制块分离,对象内存会在引用计数归零时立即释放,控制块则等待所有weak_ptr释放后才回收。
5. 使用场景限制#
- 必须用
new的情况:需要自定义删除器或需从已有裸指针构造时。
cppstd::shared_ptr<Widget> sp(new Widget, custom_deleter); - 优先用
make_shared:默认情况下推荐使用,除非有特殊需求。
总结#
| 特性 | make_shared | new + shared_ptr |
|---|---|---|
| 内存分配次数 | 1 次 | 2 次 |
| 异常安全 | 是 | 否(可能泄漏) |
| 内存释放时机 | 对象和控制块一起释放 | 对象先释放,控制块后释放 |
| 自定义删除器 | 不支持 | 支持 |
最佳实践:默认使用 make_shared,除非需要自定义删除器或特殊内存管理。
77. shared_ptr 的引用计数是在栈还是堆?#
在 std::shared_ptr 的实现中,引用计数(控制块)存储在堆上,为了共享这个这个 reference count 值。
shared_ptr和weak_ptr可能被拷贝、传递到不同的作用域(如函数调用、线程间共享)。如果引用计数在栈上,它会在栈帧销毁时被释放,导致其他指针无法正确跟踪计数。make_shared会将对象数据和引用计数分配在同一块堆内存中new+shared_ptr则是将对象数据和引用计数分配在两块独立的堆内存
- 虽然引用计数本身在堆上,但
shared_ptr的实例(即指针对象本身)可以存储在栈上
总结
| 存储位置 | 内容 | 原因 |
|---|---|---|
| 堆内存 | 引用计数(控制块)、对象数据 | 需要动态生命周期管理,支持多指针共享,跨作用域存活。 |
| 栈内存 | shared_ptr 实例本身 | 栈对象自动析构,通过析构函数减少堆上的引用计数,必要时释放对象内存。 |
78. 基类的虚函数可以声明为 private 吗#
基类的虚函数可以声明为 private,但这会影响其可访问性和多态行为的使用方式。
语法允许,但访问受限#
从语法层面,C++ 允许虚函数为 private,编译器不会报错。
派生类不能通过基类指针/引用直接访问 private 虚函数(违反访问控制规则)
多态行为仍然有效#
如果基类提供公有方法调用私有虚函数,派生类重写该私有虚函数后,多态仍能正常工作。
- 派生类重写
foo()时也必须为private(访问权限可以更宽松,但不能更严格)。
class Base {
public:
void callFoo() { foo(); } // 公有接口调用私有虚函数
private:
virtual void foo() { std::cout << "Base::foo"; }
};
class Derived : public Base {
private:
void foo() override { std::cout << "Derived::foo"; } // 重写私有虚函数
};
int main() {
Base* ptr = new Derived;
ptr->callFoo(); // 输出 "Derived::foo"(多态生效)
delete ptr;
}对比其他权限
| 虚函数权限 | 派生类能否直接调用 | 派生类能否重写 | 外部代码能否调用 |
|---|---|---|---|
public | ✅ | ✅ | ✅ |
protected | ✅ | ✅ | ❌ |
private | ❌ | ✅(需同权限或更宽松) | ❌ |
79. 如果有 100 个对象,vector、list、map 哪个占用内存高#
这个问题本质上考察 STL 容器的内存占用特性。假设我们存放 100 个对象(比如大小相同的自定义类对象),不同容器的内存开销差别主要来自于元素存储方式和额外的结构体开销。
1. vector#
- 存储方式:底层是 动态数组,所有元素连续存放。
- 额外开销:
- 仅仅是
vector自身维护的三个指针(begin/end/capacity_end),常见实现 24 字节左右。 - 可能有 容量冗余(capacity ≥ size),但不是很大。
- 仅仅是
- 内存占用:
- 接近 100 × sizeof(对象),几乎没有额外 per-element 的开销。
- 在三者中最节省内存。
2. list#
- 存储方式:双向链表,每个节点独立分配。
- 额外开销:
- 每个节点除了存放对象,还要存放两个指针(prev/next),常见实现 16 字节或更多。
- 由于频繁分配,可能带来额外的 堆分配和内存碎片开销。
- 内存占用:
- 大约 100 × (sizeof(对象) + 2 × sizeof(指针)),比
vector高不少。 - 在这三者里通常是最浪费内存的。
- 大约 100 × (sizeof(对象) + 2 × sizeof(指针)),比
3. map(通常是红黑树)#
- 存储方式:红黑树节点,每个节点存放
(key, value),还有指针和颜色信息。 - 额外开销:
- 一个节点要维护 父、左、右指针(3 个指针 = 24 字节)+ 颜色位(通常填充到 4 字节)。
- 还要存放键和值对象。
- 内存占用:
- 大约 100 × (sizeof(key) + sizeof(value) + 3 × sizeof(指针) + padding)。
- 如果 key/value 很小(比如 int/int),开销主要是结构体本身,比 list 更大。
结论(内存占用比较)#
在存放 100 个对象时,三者大致的内存占用从低到高为:vector < list < map
vector:最节省空间,几乎没有额外 per-element 开销。list:由于链表节点指针和堆分配,开销中等。map:红黑树节点开销更大(指针 + 平衡因子等),通常是最高的。
80. 虚函数表和虚函数指针存储在哪里?#
虚函数表(vtable)#
- 位置:
- 编译器生成的全局静态表,在程序的 只读数据区(.rodata) 或类似的静态存储区域。
- 每个包含虚函数的类(以及其派生类)通常对应一张或多张虚函数表。
- 表的内容是 函数指针数组,指向该类对应的虚函数实现。
- 特点:
- 程序运行时不会修改表的位置,只会改变对象中的指针指向哪一张表。
- 继承 + 覆盖虚函数时,子类的 vtable 会覆盖父类条目。
虚函数指针(vptr)#
- 位置:
- 在 对象实例的内存中,通常存放在对象的头部。
- 每个对象都有一个 vptr,指向对应类的 vtable。
- 如果类有多个虚继承/多继承,可能会有多个 vptr。
- 初始化:
- 编译器在构造函数中插入代码,把对象的 vptr 指向正确的 vtable。
- 析构时,也会相应调整 vptr 以保证多态析构正确。
举例与总结#
class Base {
public:
virtual void foo();
};
class Derived : public Base {
public:
void foo() override;
};- 程序里会生成两张 vtable:
Base的 vtable,里面有&Base::fooDerived的 vtable,里面有&Derived::foo
Base或Derived对象实例的内存中,都会有一个 vptr 指针,指向相应的 vtable。
总结
- 虚函数表(vtable):编译器生成的全局静态表,存放在只读数据段。
- 虚函数指针(vptr):存放在对象实例内存中(通常在开头),指向该对象对应的 vtable。
81. 多线程编程一般用哪些库函数?#
C 语言层面#
- POSIX Threads (pthread):
pthread_create、pthread_join、pthread_mutex_lock、pthread_cond_wait等,Linux/Unix 常用。 - C11 标准库:
thrd_create、mtx_lock(但在实际项目里用得少)。
C++ 层面#
- C++11 标准库:
std::thread(线程创建/管理)std::mutex、std::recursive_mutex、std::timed_mutex(互斥量)std::lock_guard、std::unique_lock(RAII 封装锁)std::condition_variable(条件变量)std::future/std::promise/std::async(任务并发模型)
82. 为什么需要锁?什么时候需要多线程?举个例子#
为什么需要锁
- 多线程共享内存 → 存在 竞态条件(race condition)。
- 如果两个线程同时读写同一变量,可能导致数据不一致。
- 锁(mutex) 的作用就是保证某段代码在同一时刻只有一个线程能进入,维持数据一致性。
什么时候需要多线程
- 计算密集型任务:利用多核 CPU,提高吞吐量(例如矩阵运算、图像处理)。
- I/O 密集型任务:一个线程阻塞 I/O 时,其他线程可以继续执行(例如服务器同时处理多个客户端请求)。
举例
写一个多线程日志系统:
- 多个工作线程处理业务逻辑,把日志消息写入一个共享队列。
- 一个单独线程从队列取日志写文件。
- 共享队列必须加锁,否则多线程写入会导致数据错乱。
83. 多线程场景下出现内存泄漏怎么调试解决?#
原因
- 某些线程申请的内存没有释放,线程退出后仍然占用。
- 使用 TLS(线程局部存储)或全局变量,线程结束时忘记清理。
- 线程之间交互复杂,某些分支忘记释放内存。
常见调试手段
- 工具:
valgrind --tool=memcheck(Linux)asan(AddressSanitizer)gdb
- 策略:
- 用 RAII(C++)避免手动
new/delete。 - 尽量使用智能指针(
std::unique_ptr、std::shared_ptr)。 - 保证线程退出时执行清理逻辑(析构函数/
pthread_cleanup_push)。
- 用 RAII(C++)避免手动
- 分而治之:把怀疑的线程单独跑,缩小问题范围。
下文详细介绍下「gdb 多线程调试」与「打日志 + 线上定位 + 复现副本」这两种方式。
当然能用 gdb 调多线程,而且线上定位常常要配合“打日志 + 复现副本”的办法一起用。下面给你一套“面试可讲、实际可用”的流程和要点。
(1) 用 gdb 调多线程的实用套路#
1) 基本操作(本地或 attach 线上进程)#
# 运行时调试
gdb ./your_program
(gdb) run ...
# 附加到线上/本地正在跑的进程
gdb -p <PID>
# 一次性抓所有线程的栈
(gdb) thread apply all bt
(gdb) thread apply all bt full # 带局部变量
(gdb) info threads # 线程列表
(gdb) thread <id> # 切换线程
(gdb) bt # 当前线程回溯2) 让单步/断点更可控(避免线程乱切)#
(gdb) set scheduler-locking on # 单步时不让其它线程抢占(on/step可选)
(gdb) set pagination off3) 条件断点 / 竞争点观察#
# 只在指定线程/条件触发
(gdb) break file.cpp:123 if pthread_self() == target_tid && counter < 0
# 监视内存写(找“谁改了这个变量/指针”)
(gdb) watch some_global_ptr
(gdb) rwatch x # 读监视
(gdb) awatch x # 读写监视4) 线程与锁问题的专招#
-
死锁/卡住:先
gdb -p PID,再thread apply all bt full看各线程卡在什么锁/条件变量处;很多时候能直接看出两个线程的互相等待链。 -
条件变量:在
pthread_cond_wait、pthread_mutex_lock处下断点或打条件断点,确认唤醒与加锁顺序。 -
跟踪线程创建:记录是谁创建了问题线程。
bash(gdb) break pthread_create (gdb) commands > bt > c > end
5) 核心转储(coredump)事后排查#
ulimit -c unlimited
# 触发崩溃后
gdb ./your_program core
(gdb) thread apply all bt full也可以线上“留存一份 core”,再在离线环境慢慢剖析。
6) 录制/重放#
- rr(Linux):
rr record ./prog,复现后用rr replay进 gdb,可时间回溯到变量被改写的一刻,定位数据竞争/时序问题非常好用。 - gdb 的
record full也能用,但rr更稳定。
(2) 打日志→线上定位→复现副本→看日志#
这是大厂很常见、也很靠谱的生产级排障方法:
- 打结构化日志(并带上标识)
- 必带:时间戳、线程ID、请求ID/traceID、关键状态(队列长度、锁等待时长、对象地址/指针等)。
- 在锁关键点打点:
lock acquire start/ok/timeout、cond wait/signal、enqueue/dequeue、state transition。 - 遇到潜在死锁,记录锁名/顺序和持有时长,方便识别锁顺序反转。
- 定位线上问题副本
- 用日志把异常请求/异常时间窗圈出来(比如特定用户、某个 shard、某台机器)。
- 从线上环境抽一个最小有问题的副本(相同配置/数据切片/版本/流量)到灰度或隔离环境。
- 这样能在不影响大盘的情况下复现,同时你可以随意加日志、开更高日志级别、甚至 attach gdb。
- 看日志 + 还原时序
- 通过 traceID 串起多个线程/模块的跨调用链,按照时间戳排序,重放“谁先拿了哪个锁、谁等在 cond 上”,从而定位竞态/死锁/饥饿。
- 日志中记录的内存地址/对象ID可以让你把若干条看似无关的日志对应到同一对象实例。
- 必要时动用在线栈
- 现场卡死时,用
gdb -p PID或运维脚本(比如发送信号触发backtrace()dump 全线程栈)把全线程栈打印出来,和日志时间窗对比,锁点一目了然。
- 现场卡死时,用
- 修复后再灰度验证
- 在副本/灰度环境验证“日志告警消失、锁等待时长下降、吞吐恢复”,再全量。
这套方法的核心是:用日志重建并发时序,用副本规避线上风险,用 gdb/栈/录制补齐细节。
84. 程序的内存布局是怎样的?#
一个典型 C/C++ 程序在内存里的分布大致如下:
-
代码段:包括二进制可执行代码,通常只读,还可共享(多个进程运行同一程序时只存一份);
静态存储区:数据段 + BSS 段
-
数据段:包括已初始化的静态常量和全局变量;
-
BSS 段:包括未初始化的静态变量和全局变量;
-
堆(比如
malloc/new):包括动态分配的内存,从低地址开始向上增长,程序员负责管理,容易泄露; -
文件映射区(比如
mmap):包括共享库、文件映射、匿名映射、共享内存等; -
栈:包括局部变量和函数调用的上下文(参数、返回地址)等,函数调用或返回会自动分配与释放后。栈的大小是固定的,一般是 8 MB。当然系统也提供了参数,以便我们自定义大小;
-
内核空间(对用户程序不可见)
上图中的内存布局可以看到,代码段下面还有一段内存空间的(灰色部分),这一块区域是「保留区」,之所以要有保留区这是因为在大多数的系统里,我们认为比较小数值的地址不是一个合法地址,例如,我们通常在 C 的代码里会将无效的指针赋值为 NULL。因此,这里会出现一段不可访问的内存保留区,防止程序因为出现 bug,导致读或写了一些小内存地址的数据,而使得程序跑飞。
在这 7 个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap(),就可以分别在堆和文件映射段动态分配内存。
85. delete 释放内存的时候并不知道内存大小,如何释放?#
涉及
new和delete源码及流程链接:pdd 二面 ↗
delete 运算符在释放内存时确实不需要显式指定大小,因为它依赖底层的内存管理器来跟踪分配块的信息。当使用 new 分配内存时,内存管理器(如 glibc 的分配器)会在返回给用户的内存块前端或尾部存储额外的元数据(如分配大小、cookie 等),这些信息对用户透明。调用 delete 时,运算符会根据传入的指针向前偏移一定位置来读取这些元数据,从而确定需要释放的内存块实际大小和边界,确保正确释放。因此,用户无需手动传递大小,所有细节由内存管理器和编译器生成的代码处理。
86. 一个空类大小是多少?如果有构造函数和析构函数呢?如果有虚函数?#
腾讯 TEG 一面
Q1:一个空类大小是多少?
在 C++ 中,一个空类(没有任何非静态成员变量和虚函数)的大小通常为 1 字节。这是因为编译器需要为每个对象分配一个唯一的地址标识,以确保不同对象在内存中拥有 distinct 的地址。如果大小为 0,可能导致多个对象地址相同,违反语言标准。需要注意的是,如果空类作为基类被继承,可能会发生空基类优化(EBO),此时基子对象不占用额外空间,从而节省内存。
Q2:如果空类只有构造函数和析构函数,该类大小是多少?
大小仍然是 1 个字节。 构造函数和析构函数是普通的成员函数,它们的代码并不存储在每一个对象实例中。这些函数在编译后位于代码段,所有该类的对象共享同一份函数代码。调用它们时,编译器会隐式地传入一个指向当前对象的 this 指针。因此,添加普通的成员函数(包括构造和析构)不会影响对象实例的大小。
Q3:如果空类只有虚函数,该类大小是多少?
在 64 位系统上,大小通常是 8 字节(一个指针的大小);在 32 位系统上,通常是 4 字节。
一旦一个类拥有虚函数,它就会拥有一个虚函数表(vtable),并且编译器会自动为该类的每一个对象实例添加一个隐藏的成员变量 —— 虚表指针(vptr)。这个 vptr 指向类的 vtable,用于在运行时实现多态(动态绑定)。因此,对象的大小会增加一个指针的开销。
87. 指针的大小是多少?#
指针的大小不取决于它指向的数据类型,而完全取决于目标平台的寻址能力。
- 在 32 位平台上,指针的大小是 4 字节,因为它需要能表示 个不同的内存地址。
- 在 64 位平台上,指针的大小是 8 字节,用于表示 个地址空间。
无论是指向 int、char 还是一个拥有虚函数的复杂类对象,所有数据指针的大小都遵循这个规则(函数指针可能在某些平台上有所不同)。
88. 内存对齐了解过吗,我如果不想对齐,怎么办?#
腾讯 TEG 一面
内存对齐是编译器和硬件为了提升访问效率而实施的策略。
如果不想对齐,可以通过编译器指令强制取消填充(如 GCC/Clang 的 __attribute__((packed)) 或 MSVC 的 #pragma pack(1)),使结构体成员紧凑排列。但这样做有风险:未对齐访问在 x86 架构上会导致性能下降(多次内存访问),在其他架构(如 ARM)上可能直接触发硬件异常造成崩溃。除非有特殊需求(如协议解析或节省内存),否则不建议禁用对齐。
89. 讲讲 unordered_map 和 map 的底层实现和区别#
腾讯 TEG 一面
区别#
| 特性 | std::map | std::unordered_map |
|---|---|---|
| 底层数据结构 | 红黑树 (一种自平衡的二叉搜索树) | 哈希表 (数组 + 链表/红黑树) |
| 元素顺序 | 元素按 key 排序 (默认 std::less,即升序) | 元素无序 (顺序取决于哈希函数) |
| 搜索时间复杂度 | O(log n) | 平均 O(1),最坏情况 O(n) |
| 插入时间复杂度 | O(log n) | 平均 O(1),最坏情况 O(n) |
| 删除时间复杂度 | O(log n) | 平均 O(1),最坏情况 O(n) |
| 迭代器稳定性 | 稳定(除非删除元素,否则迭代器始终有效) | 插入/删除可能使所有迭代器失效 |
| 需要为 key 定义 | operator< 或 自定义比较器 | std::hash 哈希函数 和 operator== 相等比较 |
| 内存占用 | 通常较低(树节点开销) | 通常较高(需要维护数组桶和链表) |
| 常用场景 | 需要元素有序、顺序遍历、或要求最坏情况性能稳定 | 需要快速查找、插入、删除,且不关心顺序 |
底层实现详解#
map - 基于红黑树 (Red-Black Tree)#
-
数据结构:
- 本质上是一颗二叉搜索树 (BST),这意味着任何节点的左子树所有节点的 key 都小于该节点的 key,右子树所有节点的 key 都大于该节点的 key。这使得中序遍历树时,可以得到有序的 key 序列。
- 它更具体地是一颗红黑树。红黑树是一种自平衡的二叉搜索树。它通过为节点添加颜色属性(红或黑)和定义一系列旋转和重新着色的规则,来确保树始终保持大致平衡(没有一条路径会比其他路径长两倍以上)。
-
如何工作:
- 插入:首先像普通的 BST 一样找到插入位置。插入新节点后(初始为红色),可能会破坏红黑树的平衡性质(如出现两个连续的红色节点)。这时需要通过旋转(左旋、右旋)和重新着色来恢复平衡。
- 查找:从根节点开始,与当前节点的 key 比较。如果小于,进入左子树;如果大于,进入右子树;如果相等,则找到。由于树是平衡的,查找路径长度最多为树的高度 O(log n)。
- 删除:同样先找到节点,执行 BST 删除操作后,可能会破坏平衡,需要再次通过旋转和重新着色来调整。
-
优点:元素始终有序,支持范围查询(如
lower_bound()),提供了稳定的 O(log n) 操作时间。 -
缺点:平均速度比哈希表慢,因为常数因子较大(需要多次比较和可能的内存跳跃)。
unordered_map - 基于哈希表 (Hash Table)#
-
数据结构:
- 一个数组(通常称为“桶”bucket 数组),数组的每个元素是一个链表的头指针(或一棵小红黑树的根节点)。
- 在 C++11 中,标准要求使用“开链法”解决哈希冲突。在极端情况下(一个桶里元素太多),标准允许该桶用树 instead of 链表来实现,以避免最坏性能。
-
如何工作:
- 插入:
- 对 key 进行哈希函数计算,得到一个整型的哈希值。
- 用这个哈希值
% 桶的数量来确定元素应该放在哪个桶里(即数组的哪个索引)。 - 将键值对添加到这个桶对应的链表(或树)的末尾。
- 查找:
- 同样先计算 key 的哈希值,找到对应的桶。
- 然后遍历这个桶里的链表(或树),使用
operator==进行精确匹配。
- 重新哈希 (Rehashing):
- 当元素数量超过
负载因子(load factor) * 桶的数量时,容器会自动进行重新哈希。 - 这会创建一个新的、更大的桶数组,然后将所有现有元素重新计算哈希并插入到新的数组中。
- 这个过程会使所有迭代器失效!
- 当元素数量超过
- 插入:
-
优点:平均情况下的查找、插入、删除速度极快,接近常数时间 O(1)。
-
缺点:
- 元素无序。
- 最坏情况下的性能是 O(n)(例如所有 key 都哈希到同一个桶里)。
- 迭代器不稳定(重新哈希会导致失效)。
- 需要为 key 类型提供良好的哈希函数。
如何选择?#
-
使用
std::map当:- 你需要元素按 key 排序。
- 你需要按顺序遍历元素。
- 你无法定义一个好的哈希函数 for your key type。
- 你非常关心最坏情况的性能(保证 O(log n)),而不是平均情况。
-
使用
std::unordered_map当:- 查找速度是首要任务。
- 你不需要维护元素的任何顺序。
- 你愿意并且能够为你的 key 类型定义一个高效的哈希函数(例如,基本类型和
std::string已有内置哈希)。
90. 介绍一下B树/B+树/红黑树及其对应的应用场景有哪些#
B 树#
B 树是一种多路平衡搜索树,它的每个节点可以拥有多于两个的子节点,这使得它能够保持矮胖的树形结构。
B 树的设计核心是为了减少磁盘 I/O 次数,因为它一个节点的大小通常设置为一个磁盘页的大小,一次磁盘读取就能加载一个包含多个键的巨大节点,然后在内核中进行高效的二分查找。
所以它特别适合用于文件系统和数据库(如 MySQL 的 InnoDB 存储引擎)的索引,这些场景下数据量巨大无法全部装入内存,需要频繁与磁盘交换数据。
B+ 树#
B+树是 B 树的一种变体,也是目前数据库和文件系统索引的事实标准。
它与 B 树的主要区别在于:首先,它的所有数据记录都只存储在叶子节点上,内部节点只存放键作为导航用的索引;其次,叶子节点之间通过指针相连形成了一个有序链表。
这样的设计带来了几个巨大优势:一是内部节点能存放更多的键,使得树更矮,查询需要的磁盘 I/O 更少;二是范围查询性能极高,一旦找到范围的起点,只需顺着叶子节点的链表遍历即可,而不需要像 B 树那样回溯到上层节点。
所以 MySQL 的 InnoDB 引擎、MongoDB、以及几乎所有关系型数据库的索引都在用 B+树。
红黑树#
红黑树则是一种二叉平衡搜索树,它通过复杂的旋转和变色规则来维持大致的平衡,确保从根到任意叶子节点的最长路径不会超过最短路径的两倍,从而保证了最坏情况下搜索、插入、删除操作的时间复杂度都是 。
它的主要优势在于内存中操作的效率非常高,且维护平衡的代价相对于严格的 AVL 树更小(旋转次数更少)。
因此,它的应用场景主要集中在内存计算领域,比如 C++ STL 中的 map 和 set 就是用红黑树实现的,此外还有 Linux 系统的进程调度器 Completely Fair Scheduler (CFS) 也用红黑树来管理进程队列。
91. 智能指针申请的空间是在堆上还是在栈上?#
智能指针(unique_ptr、shared_ptr)本身是一个栈上的对象,但它所管理的内存是在堆上申请的。
92. 介绍下 vector 动态扩容机制#
std::vector 的动态扩容机制是其核心特性之一,旨在平衡内存使用与操作效率。
其本质在于管理三个核心属性:size(当前元素数量)、capacity(当前分配的内存可容纳的元素数量)和分配策略(通常按固定因子增长,如2倍或1.5倍)。
当执行 push_back 或 emplace_back 等插入操作时,若当前 size 已达到 capacity,则触发扩容流程:
- 计算新容量:根据预定义的增长因子(Growth Factor,通常为2)确定新的容量值(
new_capacity = old_capacity * growth_factor)。 - 分配新内存:在自由存储区(堆)上申请一块更大的、连续的内存空间,其大小足以容纳
new_capacity个元素。 - 迁移数据:将原有内存中的所有元素移动(若移动构造函数为
noexcept)或拷贝到新内存的起始位置。此步骤会调用各元素的构造函数,是扩容过程中开销最大的操作,时间复杂度为 O(N)。 - 释放旧内存:销毁原内存中的对象并释放原有内存块。
- 更新内部状态:将内部指针指向新内存块,并将
capacity更新为new_capacity,最后在尾部构造新插入的元素。
此机制确保了插入操作的摊还时间复杂度为 O(1)。尽管单次扩容成本较高,但由于容量呈指数级增长,扩容频率迅速下降,从而将总成本均摊到多次操作上。
需要注意的是,扩容会使所有指向原 vector 元素的迭代器、指针和引用失效,因为数据的存储地址已发生改变。因此,在已知元素数量的场景下,使用 reserve() 预先分配足够容量是避免多次冗余扩容、提升性能的最佳实践。
93. vector 的 push_back 和 emplace_back 的区别?#
push_back 和 emplace_back 的核心区别在于构造对象的时机和方式。
push_back接受一个已存在的对象,并将其拷贝(左值)或移动(右值)到容器末尾,这个过程中可能产生临时对象的开销。emplace_back则直接接受构造参数,通过完美转发在容器末尾的内存中原地构造对象,省去了创建临时对象的步骤,避免了不必要的拷贝或移动操作,因此性能更高。
在大多数情况下,尤其是插入临时对象或构造代价较高的对象时,应优先选用 emplace_back。
94. 关于 vector 迭代器失效#
当 vector 的底层存储发生改变,尤其是内存重新分配时,指向其元素的迭代器、指针和引用都会变得不可用。
以下是导致 vector 迭代器失效的几种主要情况:
1. 插入元素 (insert, emplace, push_back, emplace_back)#
插入操作是否导致迭代器失效,取决于是否触发了重新分配(Reallocation)。
- 导致重新分配:如果插入新元素后,
size()超过了capacity(),vector会申请一块新的更大的内存,并将所有现有元素移动或拷贝到新内存中,然后释放旧内存。- 后果:所有迭代器、指针、引用都会失效,包括
begin(),end()以及所有指向元素的迭代器。
- 后果:所有迭代器、指针、引用都会失效,包括
- 未导致重新分配:如果插入后
size() <= capacity(),则只需要将插入点之后的所有元素向后移动。- 后果:所有指向插入点之后元素的迭代器、指针、引用都会失效。插入点之前的迭代器仍然有效。
2. 删除元素 (erase, pop_back)#
删除元素会改变序列,为了保持内存连续,需要将被删除元素之后的所有元素向前移动。
- 后果:所有指向被删除元素及其之后元素的迭代器、指针、引用都会失效。被删除元素之前的迭代器仍然有效。
- 特别注意:
erase()函数会返回一个指向被删除元素之后第一个有效元素的新迭代器,你可以利用它来安全地继续遍历。
3. 改变容量 (reserve, resize, shrink_to_fit)#
任何可能改变 vector 容量(capacity)的操作都可能引起内存重新分配。
reserve(n):如果n > capacity(),则会申请新内存并进行数据迁移,导致全部失效。shrink_to_fit():请求减少容量以匹配大小,实现可能会进行重新分配,导致全部失效。resize(n):- 如果
n > capacity()(需要扩容),则全部失效。 - 如果只是增大
size()但未触发重分配,则end()迭代器会失效。 - 如果是减小
size(),则被“抹去”的那些元素的迭代器会失效。
- 如果
4. 交换 (swap)#
当两个 vector 进行交换时,它们的底层数据指针会互换。
迭代器、指针、引用不会失效,但它们会交换归属。原来指向容器 A 中元素的迭代器,在交换后指向的是容器 B 中的元素,反之亦然。
5. 清空 (clear)#
clear() 函数会移除所有元素,并将 size() 设为 0。它不保证会改变 capacity()。
所有指向被清除元素的迭代器、指针、引用都会失效。因为元素对象已经被销毁了。
95. C++ 不同权限继承分别会有怎样的表现?#
C++ 的继承有 public、protected、private 三种方式:
public继承:基类的public成员仍然是public,protected成员仍然是protected;protected继承:基类的public和protected成员都变成protected;private继承:基类的public和protected成员都变成private。
96. 单例模式的概念和实现?懒汉式/饿汉式?线程安全?#
概念
单例模式(Singleton)是一种创建型设计模式,保证一个类在系统中只有一个实例,并提供一个全局访问点。
- 典型实现方式是将构造函数设为
private,在类内维护一个静态指针或引用,并通过一个static方法获取实例。 - 这样可以确保外部无法随意构造对象,而只能通过该方法获得同一个实例。
懒汉式:在第一次调用 getInstance() 时才创建实例,节省内存,但需要考虑多线程时的同步问题。
饿汉式:在程序启动时就初始化实例,线程安全且实现简单,但可能造成资源浪费。通常通过加锁(如 mutex)或使用双重检查锁(DCLP)来保证多线程下实例只被创建一次,同时避免每次访问都加锁带来的性能损耗。
- 前者加锁在 C++11 后一般都是利用 函数内静态变量 的线程安全初始化,而非加锁
懒汉式(线程安全)#
特点:进程启动阶段就构造实例;首次使用时无需加锁;简单、安全(依赖静态对象初始化顺序规则)。
饿汉式之所以能保证线程安全,核心原因在于静态对象的初始化时机:
EagerSingleton::s_instance是一个 静态存储期对象(全局 / namespace 作用域静态变量,或类中的静态成员)。 C++ 标准规定:
- 静态存储期对象的构造在 main 函数执行之前 完成。
- 这个初始化过程是由运行时(Runtime)在单线程环境下完成的。换句话说,在进入
main()之前,s_instance就已经被安全地构造好了。因此,在程序运行的并发环境里,任何线程调用
EagerSingleton::instance()时,s_instance已经是构造完成的对象,不存在“多个线程同时构造”的竞争条件。
#include <iostream>
class EagerSingleton {
public:
static EagerSingleton& instance() {
return s_instance; // 已在程序启动时构造完成
}
void hello() const { std::cout << "Eager\n"; }
// 禁用拷贝/移动
EagerSingleton(const EagerSingleton&) = delete;
EagerSingleton& operator=(const EagerSingleton&) = delete;
EagerSingleton(EagerSingleton&&) = delete;
EagerSingleton& operator=(EagerSingleton&&) = delete;
private:
EagerSingleton() { /* 初始化资源 */ }
~EagerSingleton() = default;
static EagerSingleton s_instance; // 定义见 .cpp
};
// 若放在同一翻译单元(示例用),需提供定义:
EagerSingleton EagerSingleton::s_instance;
int main() {
EagerSingleton::instance().hello();
}要点:
s_instance是静态全局对象,程序启动期构造、退出时析构。- 如果跨多个翻译单元,建议把定义放进唯一的
.cpp中,避免 ODR 冲突。
饿汉式(线程安全)#
方式 A:Meyers Singleton(推荐)#
特点:利用 函数内静态变量 的线程安全初始化(C++11 起标准保证),写法最简洁。
#include <iostream>
class LazySingleton {
public:
static LazySingleton& instance() {
static LazySingleton inst; // 首次调用时构造,线程安全
return inst;
}
void hello() const { std::cout << "Lazy (Meyers)\n"; }
LazySingleton(const LazySingleton&) = delete;
LazySingleton& operator=(const LazySingleton&) = delete;
LazySingleton(LazySingleton&&) = delete;
LazySingleton& operator=(LazySingleton&&) = delete;
private:
LazySingleton() { /* 初始化资源 */ }
~LazySingleton() = default;
};
int main() {
LazySingleton::instance().hello();
}优点:简洁、可靠、由标准保证一次性初始化;缺点:析构顺序不受你精细控制(通常不是问题)。
方式 B:双重检查锁(DCLP)+ std::atomic(展示用)#
在需要手动控制生命周期(如显式 destroy())的场景可用;写法更复杂,需小心内存序语义。多数情况下 A 足够。
#include <atomic>
#include <mutex>
#include <iostream>
class LazySingletonDCLP {
public:
static LazySingletonDCLP* instance() {
LazySingletonDCLP* p = ptr.load(std::memory_order_acquire);
if (!p) {
std::lock_guard<std::mutex> lk(mtx);
p = ptr.load(std::memory_order_relaxed);
if (!p) {
p = new LazySingletonDCLP();
ptr.store(p, std::memory_order_release);
}
}
return p;
}
static void destroy() { // 若需要显式销毁(可选)
std::lock_guard<std::mutex> lk(mtx);
LazySingletonDCLP* p = ptr.load(std::memory_order_relaxed);
if (p) {
delete p;
ptr.store(nullptr, std::memory_order_release);
}
}
void hello() const { std::cout << "Lazy (DCLP)\n"; }
LazySingletonDCLP(const LazySingletonDCLP&) = delete;
LazySingletonDCLP& operator=(const LazySingletonDCLP&) = delete;
LazySingletonDCLP(LazySingletonDCLP&&) = delete;
LazySingletonDCLP& operator=(LazySingletonDCLP&&) = delete;
private:
LazySingletonDCLP() { /* 初始化资源 */ }
~LazySingletonDCLP() = default;
static std::atomic<LazySingletonDCLP*> ptr;
static std::mutex mtx;
};
std::atomic<LazySingletonDCLP*> LazySingletonDCLP::ptr{nullptr};
std::mutex LazySingletonDCLP::mtx;
int main() {
LazySingletonDCLP::instance()->hello();
LazySingletonDCLP::destroy();
}- 首选:懒汉式的 Meyers Singleton(方式 A)或饿汉式静态对象,代码最简、标准保证线程安全。
- 仅当需要手动销毁或自定义分配策略时,再考虑 DCLP/
std::call_once等更复杂写法。
97. 虚函数定义为析构函数能避免内存泄露的实现原理是什么?#
当基类指针指向派生类对象并通过 delete 释放时,如果基类的析构函数不是虚函数,那么只会调用基类析构函数,派生类部分无法正确析构,导致资源未释放从而造成内存泄露。而将析构函数声明为虚函数后,析构时会触发虚函数表的动态绑定,先调用派生类的析构函数,再调用基类析构函数,确保对象的所有资源被正确释放。
98. 为什么哈希表不适合做索引结构?#
阿里面试 · 数据库
参考链接:
这是一个非常核心的【数据库】问题。
哈希表虽然拥有 O(1) 的极致点查询性能,但它固有的特性使其在大多数情况下不适合作为数据库的主流索引结构。
数据库索引的核心需求不仅仅是“快”,更是灵活性和高效地支持多种查询模式。哈希表在这一点上存在致命缺陷。
以下是哈希表不适合做(主流的)数据库索引结构的几个关键原因:
(1) 无法支持范围查询 (Range Queries)#
这是哈希索引的最大死穴。
- 哈希表的工作方式:基于哈希函数将键映射到特定的存储位置。这个映射是分散的、无序的。
id=100和id=101的记录可能被哈希到完全不相干的两个桶(bucket)里。 - 数据库的常见需求:查询如
WHERE id > 100 AND id < 200、WHERE name LIKE 'A%'、ORDER BY date。这些查询需要数据是有序的。 - 哈希表的困境:为了完成一个范围查询,哈希表必须扫描表中的每一项,因为数据在存储上是没有顺序的。这相当于全表扫描(O(n)),完全丧失了索引的意义。而 B+树等有序索引可以高效地定位范围的起点,然后通过叶子节点的链表顺序遍历即可。
(2) 无法支持排序 (ORDER BY) 和前缀匹配 (LIKE ‘abc%’)#
- 排序:
ORDER BY子句需要数据有序。哈希表输出的数据是杂乱无章的,要排序就必须将所有结果集放入内存或进行磁盘排序,成本极高。 - 前缀匹配:
LIKE 'abc%'本质上也是一个范围查询(从’abc’到’abd’),同样需要索引是有序的。哈希函数会把'abc'和'abcd'哈希成完全不同的值,无法利用索引。
(3) 哈希冲突与性能退化#
- 冲突处理:再好的哈希函数也可能存在冲突(两个不同的键被映射到同一个位置)。需要额外的机制来处理(如链表法),这会在冲突发生时增加查询时间。
- 最坏情况:如果哈希函数设计不佳或数据有特定模式,大量键可能被哈希到少数几个桶中,导致某些链变得非常长。最坏情况下,查询性能会退化为 O(n),这与设计初衷背道而驰。
(4) 哈希函数的选择至关重要且困难#
- 选择一个能均匀分散数据的哈希函数非常关键,但这并非易事,需要根据具体的数据分布来决定。
- 一旦数据特征发生变化,原先合适的哈希函数可能不再高效,而更换哈希函数意味着要重建整个索引,成本巨大。
(5) 不支持部分索引(最左匹配原则)#
- 对于复合索引(如索引
(last_name, first_name)),B+树可以支持只查询last_name的查询(最左匹配)。 - 哈希索引必须使用所有键来计算哈希值。如果你只知道
last_name而不知道first_name,哈希函数将无法计算,索引也就完全失效。
(6) 内存使用效率#
- 为了避免频繁冲突,哈希表通常需要保持较大的空闲空间(较低的负载因子,如 70%),这会导致内存/磁盘空间的浪费。
- B+树的页面填充率通常可以很高(如 70%-100%),空间利用率更好。
99. B-Tree、B+ Tree、LSM-Tree#
详细探讨一下在数据库和存储系统中至关重要的三种数据结构:B 树、B+ 树和 LSM 树。
它们都是为了解决不同场景下,如何高效地管理和访问磁盘上的大量数据而设计的。
1. B 树#
B 树是一种自平衡的多路搜索树,它允许每个节点有多个子节点(超过两个)。它旨在最大限度地减少磁盘 I/O 操作,因为从磁盘读取一个节点(即一个页面或块)通常需要一次 I/O,而节点内键的比较则在内存中进行,速度很快。
核心特性与结构#
- 多路平衡:一个节点可以拥有多个子节点(通常是上百甚至上千个),这大大降低了树的高度。树的高度与磁盘 I/O 次数直接相关,矮胖的树比高瘦的二叉树性能好得多。
- 排序节点:每个节点中的键(Key)都是按顺序存储的。
- 节点容量:一个m 阶的 B 树(order-m)满足以下属性:
- 每个节点最多有 m 个子节点。
- 每个内部节点(非根非叶)至少有 ⌈m/2⌉ 个子节点。
- 根节点至少有两个子节点(除非它是叶子节点)。
- 所有叶子节点都位于同一层,显示出完美的平衡。
- 数据存储:在经典的 B 树定义中,所有节点(包括内部节点)都可以存储数据。
操作#
- 查询:从根节点开始,在节点内部进行二分查找,找到合适的区间,然后递归地进入对应的子节点,直到找到目标键或确认键不存在。
- 插入:
- 找到应插入的叶子节点。
- 如果该节点有空间,则直接插入并排序。
- 如果节点已满,则进行分裂(Split):将中间键提升到父节点,原节点分裂成两个。这个分裂过程可能会一直向上传播到根节点,导致树增高。
- 删除:稍微复杂一些,可能涉及从兄弟节点借键(借用)或者与兄弟节点合并,以保持树的平衡和节点的最小度数要求。
优点#
- 自动保持平衡,保证查询、插入、删除的时间复杂度为 O(log n)。
- 矮胖的结构减少了磁盘访问次数。
缺点(尤其是在数据库索引场景下)#
- 区间查询效率相对较低:由于数据可能分布在所有节点(包括内部节点),进行范围查询(如
SELECT * FROM table WHERE key BETWEEN 10 AND 100)时需要在树中进行多次中序遍历,效率不高。 - 节点结构相对浪费空间:每个节点既存储键,也可能存储数据,导致每个节点能存放的键数量相对减少,树的高度可能略高于 B+树。
2. B+树#
B+ 树是 B 树的一种变体,是现代关系型数据库(如 MySQL 的 InnoDB、PostgreSQL)索引的事实标准。它针对 B 树在数据库应用中的缺点进行了优化。
核心特性与结构(与 B 树的主要区别)#
- 数据只存储在叶子节点:内部节点只存储键(索引信息)和指向子节点的指针。这使得内部节点可以容纳更多的键,从而进一步降低树的高度。
- 叶子节点通过指针串联:所有叶子节点构成一个有序双向链表。这是实现高效区间查询的关键。
操作#
- 插入和删除过程与 B 树类似,也涉及分裂和合并,但规则稍有不同,因为要维护叶子节点的链表结构。
优点(相较于 B 树)#
- 更低的树高:内部节点不存储数据,可以容纳更多的键,因此在相同数据量下,B+树比 B 树更矮胖,I/O 次数更少。
- 更稳定的查询性能:任何查询都必须到达叶子节点,因此每次查找的路径长度都是相同的(O(log n))。
- 极高的区间查询效率:这是 B+树最大的优势。一旦在叶子节点上找到了范围的起始点,就可以通过叶子节点的链表指针顺序扫描,无需回溯到上层节点。
缺点#
- 由于数据只存在于叶子节点,每次查询都必须到达叶子节点,单点查询性能可能略逊于 B 树(如果数据在 B 树的内部节点就找到的话),但这种差异微乎其微。
3. LSM 树#
LSM 树的设计理念与 B+树完全不同。它牺牲了部分的读性能,来换取极高的写吞吐量。它广泛应用于写多读少的场景,如 Google Bigtable、HBase、Cassandra、LevelDB、RocksDB 等 NoSQL 数据库中。
设计哲学#
磁盘的顺序写入速度远快于随机写入。B+ 树需要原地更新数据,可能涉及随机写入(如分裂节点)。LSM 树则通过以下方式将随机写入转换为顺序写入:
- 先写入内存和日志。
- 在后台合并和排序。
核心结构与工作流程#
LSM 树通常由两个或多个主要组件构成:
-
MemTable:
- 一个常驻内存的数据结构(通常是跳表 SkipList 或平衡树)。
- 所有新的写入操作首先被写入 MemTable,同时也会被追加到一个预写日志(Write-Ahead Log, WAL) 中用于崩溃恢复。
- 读操作需要同时查询 MemTable 和后续的 SSTable,然后合并结果。
-
Immutable MemTable:
- 当 MemTable 的大小达到阈值时,它会变为只读状态(Immutable),并准备被刷写到磁盘。同时,一个新的 MemTable 会被创建来接收新的写入操作。
- 这个设计避免了读写锁冲突,保证了持续的写入性能。
-
SSTable (Sorted String Table):
- Immutable MemTable 被顺序、批量地写入磁盘,形成一个 SSTable 文件。
- SSTable 是不可变的(Immutable),其中的数据是按键排序的。
- 随着写入不断进行,磁盘上会积累多个 SSTable 文件。
-
Compaction(压缩合并):
- 这是 LSM 树的核心后台进程。它会将多个较小的、可能有键重叠的 SSTable 合并(Merge-Sort) 成一个更大的、新的 SSTable,并在这个过程中丢弃已删除或过时的数据。
- 这个过程保证了数据的有序性和减少了文件数量,从而优化读性能。
优点#
- 极高的写入吞吐量:写入几乎是纯顺序 I/O(写 WAL 和刷写 SSTable),速度极快,远超 B+树的随机写入。
- 良好的压缩效率:由于 SSTable 是不可变且有序的,可以采用高效的压缩算法,节省磁盘空间。
缺点#
- 读放大(Read Amplification):一次读操作可能需要检查 MemTable 和多个 SSTable 文件(使用布隆过滤器等优化技术来减少不必要的文件查找),延迟可能不如 B+树稳定且通常更高。
- 写放大(Write Amplification):Compaction 过程会反复重写数据,带来额外的磁盘写入。
- 空间放大(Space Amplification):在 Compaction 发生前,重复的数据(不同版本)或已删除的数据可能同时存在于多个 SSTable 中,暂时占用额外空间。
总结与对比#
| 特性 | B 树 | B+树 | LSM 树 |
|---|---|---|---|
| 设计理念 | 平衡的多路搜索树,节点存数据 | B 树的变体,数据只存于叶子,叶子有链表 | 日志结构,先内存后磁盘,顺序写入 |
| 最佳场景 | 通用(现在较少,多被 B+树替代) | 读多写少,频繁区间查询(OLTP,关系型数据库) | 写多读少,批量写入(时序数据,日志,NoSQL) |
| 写入性能 | 中等,可能涉及随机写入(节点分裂) | 中等,可能涉及随机写入(节点分裂) | 极高,基本是顺序写入 |
| 读取性能 | 良好(点查可能更快) | 优秀(点查和范围查都非常高效) | 相对较差,存在读放大,需要查询多个结构 |
| 空间开销 | 节点存储数据,树可能略高 | 内部节点只存键,更矮胖,但叶子链表有额外指针 | 写放大和空间放大(Compaction 前),但压缩率高 |
| 复杂度 | 中(分裂/合并) | 中(分裂/合并,维护链表) | 高(需管理 MemTable,SSTable,Compaction 策略) |
- 如果你的应用是传统的 OLTP 业务,有大量随机读和范围查询(如电商、ERP),B+ 树是首选。
- 如果你的应用是监控、日志采集、物联网传感器数据等海量写入的场景,对写入速度要求极高,并能接受稍慢的读速度,LSM 树是更优的选择。
100. placement new 的使用场景及其内存分配约束#
字节面试题、华为面试题
C++ 中 placement new 的使用场景和内存分配约束。这是一个高级但非常重要的特性,常用于需要精细控制内存管理的场景。
核心概念:将“内存分配”与“对象构造”分离#
通常,new 运算符做了两件事:
- 分配内存:在堆上分配足够大小的内存以容纳该类型的对象。
- 构造对象:在刚刚分配的内存上调用对象的构造函数。
delete 运算符则做了相反的两件事:
- 析构对象:调用对象的析构函数。
- 释放内存:释放对象所占用的内存。
placement new 允许你将这两个步骤分离开来。它只执行第二步(构造对象),而不分配任何内存。你负责提前提供一块内存,placement new 只是在这块你提供的内存上调用构造函数。
它的标准形式如下:
#include <new> // 必须包含的头文件
void* preallocatedMemory = ...; // 你事先获得的一块内存
MyClass* obj = new (preallocatedMemory) MyClass(constructorArgs);这里的 (preallocatedMemory) 就是“placement”参数。placement new 是 operator new 的一个重载版本。
主要使用场景#
placement new 的应用几乎总是围绕着性能、自定义内存管理或特殊需求。
1. 内存池和自定义内存分配器#
这是最常见和最重要的用途。
- 场景:在性能关键的系统中(如游戏引擎、高频交易),频繁地使用默认的
new和delete会导致堆碎片和分配开销(因为需要查找合适的内存块、维护堆数据结构等)。 - 做法:程序启动时,一次性分配一大块内存(“内存池”)。当需要创建对象时,从这块大内存中手动划分出一小块空闲内存,然后使用
placement new在这小块内存上构造对象。对象销毁时,手动调用析构函数,然后将内存标记为空闲并归还给内存池,而不是调用delete。 - 优点:
- 极快的分配/释放速度:只是移动指针或操作空闲链表。
- 避免内存碎片:所有对象都从连续的大块内存中分配。
- 更好的局部性:连续分配的对象在物理内存上也很可能连续,提高缓存命中率。
2. 在特定内存地址构造对象#
- 场景:需要与硬件或特定系统接口交互时。例如,在嵌入式系统中,你可能需要将一个对象直接构造在某个已知的硬件寄存器地址或共享内存段上。
- 做法:直接将硬件地址或共享内存地址作为
placement new的参数。
cppvolatile HardwareRegister* reg = new (0xFFFF0000) HardwareRegister;
3. 非标准内存布局(例如:数组的精确控制)#
- 场景:你想手动管理一个对象数组的生命周期,或者需要绕过
new[]和delete[]可能带来的额外开销(例如存储数组大小的开销)。 - 做法:先分配一个足够大的
char数组(sizeof(MyClass) * N),然后使用循环和placement new在正确的位置逐个构造对象。销毁时,必须手动逆序调用每个对象的析构函数,最后释放整个char数组。
#include <new>
class MyClass {...};
// 1. 分配原始内存(不构造对象)
void* memory = operator new[](sizeof(MyClass) * 10);
MyClass* objects = static_cast<MyClass*>(memory);
// 2. 使用 placement new 构造对象
for (std::size_t i = 0; i < 10; ++i) {
new (&objects[i]) MyClass(...); // 在指定地址构造
}
// 3. 手动调用析构函数
for (std::size_t i = 10; i > 0; ) {
--i;
objects[i].~MyClass(); // 显式析构
}
// 4. 释放原始内存
operator delete[](memory);4. 实现类似 std::vector 和 std::make_shared 的容器和智能指针#
标准库容器(如 std::vector)在底层使用 allocator 来分配原始内存,然后使用 placement new 在已分配的内存中构造元素。这使它们能够在重新分配时(reserve)将“分配新内存”和“移动/构造元素”分离开来。
类似地,std::make_shared 通常在一次分配中同时获得控制块(引用计数)和对象本身所需的内存,然后使用 placement new 在内存的正确偏移处构造对象。
内存分配约束与注意事项(极其重要)#
使用 placement new 意味着你接管了部分编译器的职责,因此必须严格遵守以下约束:
1. 内存必须提前分配且足够大#
你提供的指针 preallocatedMemory 必须指向一块已经分配好的内存,并且这块内存的大小至少为 sizeof(MyClass) 字节。如果内存不足,构造函数的行为是未定义的(通常是灾难性的崩溃或数据损坏)。
2. 内存对齐必须正确#
你提供的内存地址必须满足该类型 MyClass 的内存对齐要求。C++11 之后可以使用 alignof(MyClass) 来查询对齐要求,使用 alignas(MyClass) char buf[sizeof(MyClass)]; 来声明一个正确对齐的缓冲区。
错误示例:
char buffer[sizeof(MyClass)]; // 一个普通的char数组,可能只按1字节对齐
MyClass* obj = new (buffer) MyClass; // 如果MyClass要求4或8字节对齐,此行为未定义!正确做法:
// C++11 之前:使用编译器扩展或union技巧
// C++11 之后:
alignas(MyClass) std::byte buffer[sizeof(MyClass)]; // 正确对齐的缓冲区
MyClass* obj = new (buffer) MyClass; // 安全3. 必须手动调用析构函数#
由于 placement new 不分配内存,所以标准的 delete obj; 不能使用。delete 会尝试释放内存,但你提供的内存并不是由 new 分配的,释放它会导致未定义行为。
你必须显式地调用析构函数来销毁对象:
obj->~MyClass(); // 正确:只执行析构,不释放内存之后,你提供的原始内存如何处理(是复用、归还给内存池还是直接释放)取决于你最初是如何分配它的。
4. 生命周期管理的责任完全在程序员#
你需要确保:
- 对象在其生命周期内,其底层内存保持有效且未被覆盖。
- 不要对使用
placement new创建的对象调用delete。 - 在底层内存被释放或重用之前,必须调用析构函数。
总结#
| 特性 | 标准 new/delete | placement new |
|---|---|---|
| 内存来源 | 堆 | 由程序员预先提供 |
| 执行操作 | 分配内存 + 调用构造函数 | 仅调用构造函数 |
| 清理操作 | 调用析构函数 + 释放内存 | 必须手动调用析构函数 |
| 使用场景 | 通用 | 内存池、自定义分配器、特定地址构造、容器实现 |
| 风险 | 低 | 高(内存对齐、手动生命周期管理) |
总而言之,placement new 是一个强大的工具,它将对象的构造与内存分配解耦,为你提供了极致的内存控制能力。然而,这种能力也带来了巨大的责任,你必须严格遵守内存对齐和生命周期管理的规则,否则极易引发难以调试的未定义行为。在大多数日常应用开发中,你不需要直接使用它,但它却是许多高性能库和系统底层实现的基石。
101. 智能指针的应用场景和线程安全问题#
应用场景#
智能指针用于自动化资源(尤其是动态内存)的生命周期管理,防止内存泄漏。
std::unique_ptr(独占所有权):- 场景:适用于资源在任何时刻都只能被一个所有者拥有的情况。是资源管理的默认选择。
- 例子:作为类的成员变量、在函数内部管理动态分配的对象、作为工厂函数的返回值。它替代了需要手动
delete的原始指针。
std::shared_ptr(共享所有权):- 场景:适用于多个对象需要共享同一个资源,并且只有在最后一个所有者被销毁时资源才能被释放的情况。
- 例子:实现缓存机制(多个客户端可能共享同一个缓存对象)、在复杂的数据结构中(如图、节点之间可能共享所有权)、需要将指针存入多个容器中。
std::weak_ptr(弱引用):- 场景:与
std::shared_ptr搭配使用,解决shared_ptr的循环引用问题。它提供对共享资源的“非拥有”引用,不会增加引用计数。 - 例子:观察者模式(主题持有观察者的
weak_ptr,避免观察者无法析构)、缓存(持有缓存对象的weak_ptr,当主所有者释放对象后,缓存自动失效)、打破循环引用(如双链表节点中,父节点对子节点用shared_ptr,子节点对父节点用weak_ptr)。
- 场景:与
线程安全问题#
智能指针本身的引用计数操作是线程安全的,但其指向的对象的读写需要用户自己同步。
- 引用计数的线程安全:
std::shared_ptr的引用计数控制块(control block)是原子操作的。因此,在多线程中复制或析构shared_ptr本身是安全的,不会导致引用计数混乱。这是一个非常重要的保证。
- 指向数据的线程不安全:
- 多个线程同时读写同一个
shared_ptr实例(例如,对其赋值或重置)是不安全的,需要加锁。这涉及到指针本身(get()返回的值)的更改。 - 多个线程通过不同的
shared_ptr实例(它们指向同一个对象)去访问和修改其指向的对象是不安全的。这属于典型的数据竞争,也是必须使用互斥锁(如std::mutex)或其他同步机制来保护对对象本身的操作。
- 多个线程同时读写同一个
102. 介绍下布隆过滤器的工作原理和实现#
布隆过滤器(Bloom Filter)是一个高效的概率型数据结构,用于快速判断一个元素是否存在于一个超大规模集合中。其核心特点是极其节省空间,但代价是存在一定的误判率(False Positive)。
工作原理/工作流#
布隆过滤器的目标不是存储元素本身,而是用一个很小的位数组和一组哈希函数来表示一个集合,从而快速判断一个元素是否绝对不存在或可能存在于集合中。
1. 初始化
- 创建一个长度为
m的位数组,所有位初始化为 0。 - 选择
k个彼此独立的哈希函数(h1, h2, ..., hk),每个函数能将输入元素映射到位数组的某个位置(范围在[0, m-1])。
2. 添加元素:假设要添加元素 “X”。
- 将 “X” 分别输入
k个哈希函数,得到k个哈希值:h1(X), h2(X), ..., hk(X)。 - 将位数组中这
k个位置的值都设置为 1。
3. 查询元素:假设要查询元素 “Y” 是否存在。
- 将 “Y” 分别输入同样的
k个哈希函数,得到k个哈希值。 - 检查位数组中这
k个位置的值:- 如果这
k个位置中有任何一个为 0,那么元素 “Y” 肯定不存在(Definitely No)于集合中。 - 如果这
k个位置全部为 1,那么元素 “Y” 可能存在(Probably Yes)于集合中。
- 如果这
影响因子:m 与 k#
布隆过滤器的大小 m(即比特数组的长度)是一个关键的设计参数,它直接影响了过滤器两个最重要的性能指标:误判率和空间效率。这是一个典型的空间换精度的权衡。
1. 对误判率的影响#
m 越大,误判率越低。
- 原因: 更大的比特数组意味着更多的“坑位”,
k个哈希函数映射到的位置更分散,不容易发生冲突。 - 反面:
m越小,比特数组很快就会被填满(更多的位被置为1),导致“假阳性”的概率急剧上升。
2. 对空间效率的影响#
m 越大,空间开销越大。
3. 与哈希函数数量 k 的相互作用#
- 这是一个联动效应。最优的
k值取决于m和要插入的元素数量n。 - 公式: 最优的哈希函数数量 。
- 解释:
- 如果
m很大,但k很小(比如只有 1 个哈希函数),那么每个元素设置的位置很少,缺乏“冗余”,仍然容易发生冲突。 - 如果
m很小,但k很大,会导致一个元素设置太多的位,迅速将小的比特数组“填满”,使得几乎每次查询都会碰到所有位都是1的情况,误判率会接近 100%,过滤器也就失效了。
- 如果
- 所以不能孤立地谈
m的大小,必须结合计划存储的元素数量n和选择的哈希函数个数k来综合设计。
4. 对性能(查询/添加)的轻微影响#
- 影响很小,但存在。添加和查询操作都需要进行
k次哈希计算和内存访问。 m的大小本身不影响计算速度(k次哈希和k次内存访问是固定的)。- 但是,如果
m特别大,超出了 CPU 缓存的范围,可能会导致缓存缺失,使得每次内存访问的速度变慢。但在绝大多数应用中,这个影响微乎其微,性能瓶颈主要在哈希计算上。
那你如何决定布隆过滤器的大小?#
如果面试官追问:“那你如何决定布隆过滤器的大小?”
在实际工程中,我们通常遵循以下步骤:
- 确定容量
n:首先预估要存入过滤器的元素最大数量是多少。 - 设定目标误判率
p:根据业务场景,确定一个可接受的误判率上限(例如 1%, 0.1%)。 - 计算所需的比特数
m:使用公式 。这给出了在理论上达到目标误判率所需的最小的m。 - 计算最优哈希函数数
k:再根据公式 round 到最近的整数。 - 向上取整: 最后,我会将计算出的
m向上取整到最接近的机器字长(例如64的倍数)的整数,以便内存对齐,实现高效的位操作。”
Bloom filter 代码#
以下是注释详细的 C++ 布隆过滤器实现,包含了添加、查询、误判率计算和性能测试。
#include <iostream>
#include <vector>
#include <bitset>
#include <functional>
#include <cmath>
#include <string>
/**
* @brief 布隆过滤器 (Bloom Filter) 实现类
*
* @tparam Size 位数组的大小,以比特为单位。必须是编译期常量。
*/
template <size_t Size>
class BloomFilter {
private:
std::bitset<Size> bits; // 位数组,用于存储元素的存在信息
std::vector<std::function<size_t(const std::string&)>> hashFunctions; // 哈希函数集合
public:
/**
* @brief 构造函数,初始化指定数量的哈希函数
* @param numHashes 哈希函数的数量
*/
BloomFilter(size_t numHashes) {
// 使用简单的哈希函数种子来生成不同的哈希函数
for (size_t i = 0; i < numHashes; ++i) {
// 使用lambda捕获不同的种子来创建不同的哈希函数
hashFunctions.emplace_back([i](const std::string& item) {
std::hash<std::string> hasher;
return hasher(item + std::to_string(i)); // 通过添加不同的后缀来创建不同的哈希函数
});
}
}
/**
* @brief 向布隆过滤器中添加一个元素
* @param item 要添加的元素(字符串形式)
*/
void add(const std::string& item) {
for (const auto& hashFunc : hashFunctions) {
size_t hashValue = hashFunc(item);
size_t index = hashValue % Size; // 映射到位数组的位置
bits.set(index, true); // 将对应位置设为1
}
}
/**
* @brief 检查元素是否可能存在于布隆过滤器中
* @param item 要检查的元素
* @return true - 元素可能存在(有误判可能)
* @return false - 元素肯定不存在
*/
bool possiblyContains(const std::string& item) const {
for (const auto& hashFunc : hashFunctions) {
size_t hashValue = hashFunc(item);
size_t index = hashValue % Size;
if (!bits.test(index)) { // 如果任何一个位为0
return false; // 肯定不存在
}
}
return true; // 所有位都为1,可能存在
}
/**
* @brief 计算当前布隆过滤器的理论误判率
* @param insertedItems 已插入元素的数量
* @return double 预期的误判率 (0.0 ~ 1.0)
*/
double expectedFalsePositiveRate(size_t insertedItems) const {
if (insertedItems == 0) return 0.0;
// 理论误判率公式: (1 - e^(-k*n/m))^k
double exponent = -static_cast<double>(hashFunctions.size() * insertedItems) / Size;
return std::pow(1 - std::exp(exponent), hashFunctions.size());
}
/**
* @brief 获取位数组的使用率(已置为1的位数比例)
* @return double 使用率 (0.0 ~ 1.0)
*/
double getUsageRatio() const {
return static_cast<double>(bits.count()) / Size;
}
/**
* @brief 重置布隆过滤器,清空所有数据
*/
void reset() {
bits.reset();
}
/**
* @brief 获取位数组大小
*/
size_t size() const {
return Size;
}
/**
* @brief 获取哈希函数数量
*/
size_t hashCount() const {
return hashFunctions.size();
}
};
/**
* @brief 运行特定配置的测试
*/
template <typename BloomFilterType>
void runConfigurationTest(BloomFilterType& bloomFilter,
const std::string& sizeDesc,
size_t k,
size_t testItems) {
// 添加测试元素
for (int i = 0; i < testItems; ++i) {
bloomFilter.add("item_" + std::to_string(i));
}
// 测试误判率
int falsePositives = 0;
for (int i = 0; i < testItems; ++i) {
if (bloomFilter.possiblyContains("test_" + std::to_string(i))) {
falsePositives++;
}
}
double fpr = static_cast<double>(falsePositives) / testItems;
std::cout << "Size: " << sizeDesc << ", Hashes: " << k
<< ", FPR: " << (fpr * 100) << "%, Usage: "
<< (bloomFilter.getUsageRatio() * 100) << "%" << std::endl;
}
/**
* @brief 比较不同配置下的布隆过滤器性能
*/
void compareDifferentConfigurations() {
std::cout << "\n\n===== 不同配置性能比较 =====" << std::endl;
const size_t TEST_ITEMS = 1000;
const size_t sizes[] = {5000, 10000, 20000}; // 不同的位数组大小
const size_t hashes[] = {3, 7, 11}; // 不同的哈希函数数量
for (size_t size : sizes) {
for (size_t k : hashes) {
// 使用模板特化来支持不同大小
if (size == 5000) {
BloomFilter<5000> bf(k);
runConfigurationTest(bf, "5K bits", k, TEST_ITEMS);
} else if (size == 10000) {
BloomFilter<10000> bf(k);
runConfigurationTest(bf, "10K bits", k, TEST_ITEMS);
} else if (size == 20000) {
BloomFilter<20000> bf(k);
runConfigurationTest(bf, "20K bits", k, TEST_ITEMS);
}
}
}
}
/**
* @brief 测试布隆过滤器性能的函数
*/
void testBloomFilter() {
std::cout << "===== 布隆过滤器性能测试 =====" << std::endl;
const size_t BLOOM_FILTER_SIZE = 10000; // 位数组大小:10,000 位
const size_t NUM_HASHES = 7; // 哈希函数数量:7个
const size_t TEST_ITEMS = 1000; // 测试元素数量:1000个
// 创建布隆过滤器实例
BloomFilter<BLOOM_FILTER_SIZE> bloomFilter(NUM_HASHES);
// 生成测试数据
std::vector<std::string> insertedItems;
std::vector<std::string> testItems;
for (int i = 0; i < TEST_ITEMS; ++i) {
insertedItems.push_back("item_" + std::to_string(i));
testItems.push_back("test_" + std::to_string(i)); // 这些是不会被插入的测试项
}
// 1. 添加元素
std::cout << "正在添加 " << TEST_ITEMS << " 个元素..." << std::endl;
for (const auto& item : insertedItems) {
bloomFilter.add(item);
}
// 2. 检查已插入的元素(应该全部"可能存在")
std::cout << "\n检查已插入的元素:" << std::endl;
int truePositives = 0;
for (const auto& item : insertedItems) {
if (bloomFilter.possiblyContains(item)) {
truePositives++;
}
}
std::cout << "真正例数: " << truePositives << "/" << TEST_ITEMS
<< " (" << (truePositives * 100.0 / TEST_ITEMS) << "%)" << std::endl;
// 3. 检查未插入的元素(测量误判率)
std::cout << "\n检查未插入的元素(测量误判率):" << std::endl;
int falsePositives = 0;
for (const auto& item : testItems) {
if (bloomFilter.possiblyContains(item)) {
falsePositives++;
}
}
double actualFPR = static_cast<double>(falsePositives) / TEST_ITEMS;
double expectedFPR = bloomFilter.expectedFalsePositiveRate(TEST_ITEMS);
std::cout << "误判数: " << falsePositives << "/" << TEST_ITEMS << std::endl;
std::cout << "实际误判率: " << (actualFPR * 100) << "%" << std::endl;
std::cout << "理论误判率: " << (expectedFPR * 100) << "%" << std::endl;
// 4. 显示使用情况
std::cout << "\n布隆过滤器使用情况:" << std::endl;
std::cout << "位数组大小: " << bloomFilter.size() << " bits ("
<< (bloomFilter.size() / 8) << " bytes)" << std::endl;
std::cout << "哈希函数数量: " << bloomFilter.hashCount() << std::endl;
std::cout << "位数组使用率: " << (bloomFilter.getUsageRatio() * 100) << "%" << std::endl;
// 5. 演示"肯定不存在"的特性
std::cout << "\n演示'肯定不存在'特性:" << std::endl;
std::string nonExistentItem = "definitely_not_inserted_12345";
bool result = bloomFilter.possiblyContains(nonExistentItem);
std::cout << "检查未添加的元素 '" << nonExistentItem << "': "
<< (result ? "可能存在" : "肯定不存在") << std::endl;
}
int main() {
// 运行基本测试
testBloomFilter();
// 运行配置比较
compareDifferentConfigurations();
std::cout << "\n===== 测试完成 =====" << std::endl;
return 0;
}Output
~/Desktop ./bloom_filter
===== 布隆过滤器性能测试 =====
正在添加 1000 个元素...
检查已插入的元素:
真正例数: 1000/1000 (100%)
检查未插入的元素(测量误判率):
误判数: 4/1000
实际误判率: 0.4%
理论误判率: 0.819372%
布隆过滤器使用情况:
位数组大小: 10000 bits (1250 bytes)
哈希函数数量: 7
位数组使用率: 50.25%
演示'肯定不存在'特性:
检查未添加的元素 'definitely_not_inserted_12345': 肯定不存在
===== 不同配置性能比较 =====
Size: 5K bits, Hashes: 3, FPR: 8.7%, Usage: 45.2%
Size: 5K bits, Hashes: 7, FPR: 14.4%, Usage: 75.5%
Size: 5K bits, Hashes: 11, FPR: 31.2%, Usage: 88.94%
Size: 10K bits, Hashes: 3, FPR: 1.4%, Usage: 26.09%
Size: 10K bits, Hashes: 7, FPR: 0.4%, Usage: 50.25%
Size: 10K bits, Hashes: 11, FPR: 1.3%, Usage: 66.44%
Size: 20K bits, Hashes: 3, FPR: 0.1%, Usage: 13.955%
Size: 20K bits, Hashes: 7, FPR: 0%, Usage: 29.425%
Size: 20K bits, Hashes: 11, FPR: 0%, Usage: 41.945%
===== 测试完成 =====103. 常量数组和数组常量的区别?#
常量数组指数组元素是常量(如 const int arr[5]),内容不可修改;
数组常量指数组本身是常量(如 int* const arr),指针不可指向其他地址。
构造方式:常量数组用
const 类型名[]声明并初始化;数组常量需用类型* const声明并固定指向已分配内存。
104. 常量指针和指针常量区别?#
常量指针通常有两种表示方法:
const int* ptrint const* ptr
指针常量通常表示为:
double *const ptr
区分:从左往右读/看
const读作常量,*读作指针;const*就是常量指针,*const就是指针常量。const靠近谁就是谁不变;const char *p1靠近char *所以是内容不可变,char *const p2靠近 p2 所以是指针指向不可变。
常量指针:指向常量的指针,与下面相反,指针地址的内容值不能修改,但指针地址指向可以改。
指针常量:指的是指针本身就是个常量,注意这里说的是指针本身是常量,指针是用来指向某个对象的(指针也就是这个对象的地址)指针本身是常量,就是这个地址是个常量,不能更换,但是可以更换这个地址存放的值。
#include <iostream>
using namespace std;
int main() {
char ch = 'h';
char s = 'm';
const char *p1 = &ch; // 常量指针: 可以通过它更换指向的对象,但是不能改变指向对象的值;
char *const p2 = &ch; // 指针常量: 可以通过它更改对象的值,但是不能更改指向的对象;
p1 = &s; // 正确;
*p1 = 'k'; // 错误;
*p2 = 'k'; // 正确;
p2 = &s; // 错误;
}105. C++ 模板的原理?#
C++ 模板的原理本质上是一种编译期的代码生成机制,其核心是参数化多态。
当编译器遇到模板定义(如一个函数模板或类模板)时,它并不会立即生成任何实际的机器代码,而是将其视为一种生成代码的“蓝图”或“配方”存储在编译单元中。只有当编译器在源代码中看到模板被实例化(即提供了具体的模板参数,如 MyClass<int>)时,它才会执行模板实例化这个过程:将模板定义中的每个模板参数(如 typename T)替换为提供的具体类型(如 int),从而生成一个全新的、普通的类或函数的源代码副本(称为特化或实例)。这个过程是静态的,发生在编译阶段,因此不同的实例化会生成完全独立的类型(例如,vector<int> 和 vector<string> 是两个毫无关联的类),这导致了著名的“代码膨胀”现象,但也确保了类型安全和极高的运行时效率。最终,编译器再像处理普通手写代码一样,对这些生成的特化代码进行编译和优化,生成目标代码。
106. 命名空间的作用?#
命名空间用于解决标识符(变量、函数、类名)冲突问题,将代码逻辑分组封装,形成独立作用域。通过 namespace 关键字定义,使用时需指定命名空间(如 std::vector)或使用 using 声明,避免全局作用域污染。
107. 迭代器在 STL 中的作用?#
迭代器是 STL 中抽象化的指针,提供统一访问容器元素的方式(如遍历、修改),实现算法与容器的解耦。
它分为输入、输出、前向、双向、随机访问等类别,支持泛型算法(如 sort)无需关心底层容器实现。
108. 指针 * 和引用 & 的区别(进阶版)#
一、引用和指针的区别#
引用和指针本质上都是间接访问和操作其他对象的方式,但它们在语法、安全性和灵活性上有显著区别。
| 特性 | 引用 (Reference) | 指针 (Pointer) |
|---|---|---|
| 本质 | 是一个对象的别名,不是一个对象本身。 | 是一个独立的对象,存储的是另一个对象的地址。 |
| 初始化 | 必须被初始化(绑定到一个对象),且不能更改绑定。 | 可以声明时不初始化(但极度危险),可以随时改变指向。 |
| 空值 | 不能为空(NULL)。必须总代表某个合法对象。 | 可以为nullptr,表示不指向任何对象。 |
| 操作 | 所有操作都直接作用于其绑定的对象。 | 有取地址(&)、解引用(*) 等专门操作。 |
| 内存地址 | 引用自身不占用存储空间(通常由编译器在底层实现为指针)。 | 指针本身是一个对象,占用内存(通常是4或8字节)。 |
| 安全性 | 更安全,因为非空且无法重新绑定,避免了野指针等问题。 | 更灵活但也更危险,可能产生空指针解引用、野指针等问题。 |
| 多级间接 | 不支持多级引用(如引用的引用,实际是原对象的引用)。 | 支持多级指针(如 int** pp)。 |
二、二者的应用场景#
引用的主要应用场景#
-
函数参数传递(按引用传递):这是最常见用途。用于避免大型对象拷贝的开销,并允许函数修改传入的实参。
cppvoid swap(int& a, int& b) { // 修改实参 int temp = a; a = b; b = temp; } void printLargeObject(const BigClass& obj) { // 避免拷贝,且不允许修改 // ... 只读操作 } -
函数返回值(返回引用):常用于返回函数调用者可以修改的对象,如重载赋值运算符
=、下标运算符[]、流运算符<</>>。
cppclass MyVector { int data[100]; public: int& operator[](size_t index) { return data[index]; } // 返回引用,允许v[i] = 5; }; -
范围for循环:需要修改容器元素时,必须使用引用。
cppfor (auto& element : myVector) { element *= 2; // 修改容器内的元素 }
指针的主要应用场景#
-
动态内存管理:使用
new/delete或malloc/free在堆上分配资源时,必须用指针来管理。
cppint* array = new int[100]; delete[] array; -
多态和面向对象:通过基类指针来管理派生类对象,实现运行时多态。
cppclass Base { virtual void func(); }; class Derived : public Base { void func() override; }; Base* ptr = new Derived(); ptr->func(); // 调用的是Derived::func() delete ptr; -
需要表示“可选”或“可为空”的语义:当需要一个可能不指向任何对象的变量时,必须使用指针。
cppTreeNode* parent = nullptr; // 根节点的父节点为空 -
需要显式处理地址或进行底层操作:如操作硬件、数据结构(链表、树等)等。
cppstruct ListNode { int val; ListNode* next; // 指向下一个节点的指针 };
三、函数传递引用和传递指针的区别?#
这个问题更准确的表述是:函数按引用传递(Pass-by-Reference)和按值传递(Pass-by-Value)的区别?
| 方面 | 按值传递 (Pass-by-Value) | 按引用传递 (Pass-by-Reference) |
|---|---|---|
| 本质 | 在函数栈上创建实参的一个副本。 | 传递的是实参本身的别名(引用)或地址(指针)。 |
| 对原值的影响 | 函数内部对形参的任何修改都不会影响外部的实参。 | 函数内部对形参(引用或解引用的指针)的修改会直接影响外部的实参。 |
| 性能开销 | 如果实参是大型结构体或类,拷贝开销大。 | 几乎无开销,只是传递了一个别名或一个地址(通常是4/8字节)。 |
| 使用语法 | void func(MyType obj); | void func(MyType& ref); 或 void func(MyType* ptr); |
| 安全性 | 安全,函数内外的变量完全隔离。 | 需要小心,尤其是传递指针时,可能需检查是否为nullptr。 |
代码示例对比:
#include <iostream>
using namespace std;
// 1. 按值传递 - 拷贝副本
void byValue(int x) {
x = 100; // 只修改了副本,外部的num1不变
}
// 2. 按引用传递 - 传递别名
void byReference(int& x) {
x = 200; // 直接修改外部的num2
}
// 3. 按指针传递(本质也是按值传递,但传递的是地址的值) - 传递地址
void byPointer(int* x) {
*x = 300; // 解引用,修改x所指向的外部num3的值
}
int main() {
int num1 = 1, num2 = 2, num3 = 3;
byValue(num1);
byReference(num2);
byPointer(&num3); // 需要显式取地址
cout << num1 << endl; // 输出 1
cout << num2 << endl; // 输出 200
cout << num3 << endl; // 输出 300
return 0;
}总结:
- 按值传递:适用于不需要修改实参,且参数是内置类型(
int,double等)或小型结构体的情况。 - 按引用传递:适用于需要修改实参,或参数是大型对象需要避免拷贝开销的情况。使用
const引用(如const BigObj&)可以同时实现避免拷贝 + 不允许修改,是最佳的只读参数传递方式。 - 按指针传递:在C++中,除非需要表达“可选”语义(可能为
nullptr)或需要重新指向其他对象,否则优先使用引用。按指针传递在语法上更繁琐(需要&和*),且安全性更低。
109. noexcept 原理,noexcept 修饰函数内抛出异常怎么办?#
- 帮助编译器对“非抛出函数”进行优化
- 影响标准库的行为
- 异常传播处理
1. 帮助编译器对“非抛出函数”进行优化#
noexcept 关键字首先是一个给编译器的指令和承诺。当一个函数被标记为 noexcept(或 noexcept(true)),编译器会基于这个承诺进行两方面的优化:
-
简化异常处理代码生成:在通常情况下,编译器需要为可能抛出异常的函数生成复杂的“栈展开(Stack Unwinding)”代码。这套机制负责在异常抛出时,自动调用所有已构造的局部对象的析构函数,以保证资源的正确释放。对于
noexcept函数,编译器可以确信该函数执行过程中不会有异常抛出,因此完全可以省略这部分栈展开代码的生成。这使得生成的机器码更小、更紧凑。 -
启用更激进的代码优化:由于异常路径不存在,编译器的优化器可以更自由地对
noexcept函数的代码进行重组和简化。它不需要考虑在异常发生时保持一种可回滚的状态,从而可以更专注于优化正常的执行路径,这有可能带来性能上的提升。
核心思想:noexcept 通过提供一份“绝不会抛出异常”的保证,允许编译器生成更精简、更高效的代码。
2. 影响标准库的行为#
noexcept 更显著的作用是它会影响标准库组件的算法选择和行为,尤其是在与移动语义和资源管理相关的操作上。标准库会利用 noexcept 说明符在“强异常安全”和“性能”之间做出权衡。
-
移动操作与拷贝操作的抉择:最经典的例子是
std::vector的重新分配(reallocation)过程。当 vector 需要扩容时,它需要将旧元素移动到新内存中。如果元素的移动构造函数是noexcept的,vector 会安全地使用移动操作,因为这绝不会失败,效率极高。如果移动构造函数不是noexcept的,vector 为了保持“强异常安全”保证(如果移动中抛出异常,旧容器状态不变),则会保守地使用拷贝操作,即使拷贝通常更耗时。 -
std::move_if_noexcept:这个工具函数是上述行为的直接体现。它会在类型移动操作为noexcept时返回右值引用(以启用移动),否则返回常量左值引用(以禁用移动,促使调用拷贝操作)。 -
其他标准库操作:类似的行为也存在于
std::swap、std::sort等算法中,它们可能会在内部使用不同的策略来确保异常安全,而noexcept信息是决策的关键依据。
核心思想:noexcept 是标准库选择更高效算法(特别是移动操作)而非更安全但低效算法(拷贝操作)的“许可证”。
3. 异常传播处理#
这是关于契约违反后的处理机制,是面试中的关键考察点。
-
契约与承诺:将函数声明为
noexcept是程序员向编译器和用户做出的一个坚定承诺,保证该函数的执行绝不会导致异常传播到函数体外。 -
运行时行为:如果这个承诺在运行时被打破(即函数内部抛出了异常),C++ 标准规定程序必须立即调用
std::terminate()函数来终止执行。这个过程是不可捕获、不可恢复的。std::terminate()的默认行为是中止程序(abort),可能不会调用局部对象的析构函数。 -
设计哲学:这种行为背后的哲学是,违反
noexcept承诺是一个严重的逻辑错误,其后果是不可预期的。与其让异常在缺乏正确异常处理机制的上下文中传播,导致未定义行为,不如以一种明确、果断的方式终止程序,这保证了程序行为的确定性。
核心思想:在 noexcept 函数中抛出异常会导致程序立即强制终止(std::terminate()),这是一种“契约违反”的严厉惩罚机制,旨在防止更糟糕的未定义行为。
110. 虚函数表底层原理实现#
C++ 中的虚函数表(vtable)是实现运行时多态(动态绑定)的核心机制。
其底层原理是:编译器会为每个包含虚函数的类(或从该类继承的子类)秘密地创建一个虚函数表。这个表本质上是一个函数指针数组,其中的每个条目都指向该类的一个虚函数的具体实现。当一个类对象被创建时,编译器会自动在对象的内存布局的开头(或末尾,取决于编译器实现)插入一个隐藏的指针成员(vptr),该指针被初始指向这个类相应的虚函数表。当通过基类指针或引用调用虚函数时,代码会通过对象的 vptr 找到对应的 vtable,然后在 vtable 中查找并调用正确偏移量处的函数指针。这个过程是在运行时进行的,因此能够根据对象的实际类型来决定调用哪个函数,从而实现多态。如果子类重写了虚函数,那么子类的 vtable 中对应条目就会指向子类的函数,而非父类的。
111. async 和 thread pool 你在使用的时候是怎么选择的#
async是一个关键字或概念,用于声明一个函数是异步函数。它是现代编程语言(如 JavaScript, Python, C#, Rust, C++ 等)中处理并发操作的核心特性,其目的是为了更高效、更简洁地编写非阻塞的、基于 I/O 操作的代码。其核心思想是:让一个耗时的操作(如网络请求、文件读写、数据库查询)在后台等待完成,而不阻塞主线程的执行。程序可以在此期间去做其他工作,当那个耗时操作完成后,再回来处理它的结果。
一个用
async标记的函数,通常被称为协程 (Coroutine)。它与普通函数和线程都不同:
不同于普通函数:普通函数是“一路走到黑”的,从调用开始直到 return 语句返回结果,期间调用者必须等待。而异步函数被调用时,会立即返回一个承诺对象(通常叫
Promise,Future, 或Task),而不是最终结果。这个承诺对象代表一个“未来会完成的操作”。不同于线程:协程是单线程下的并发技术。多个协程在一个线程上交替运行,由事件循环 (Event Loop) 调度。当一个协程遇到
await(等待)关键字时,它会主动挂起(Suspends),将控制权交还给事件循环,事件循环 then 可以去执行其他就绪的协程。这避免了多线程带来的上下文切换开销和复杂的同步问题(如锁、死锁)。关键搭档:
await
async总是与await关键字配对使用。
async:用于声明一个函数是异步的。await:用于调用一个异步操作。它只能在async函数内部使用。当执行到await expression时,它会做两件事:
- 挂起当前
async函数的执行。- 等待
expression(通常是一个Promise/Future)完成。在等待期间,线程不会被阻塞,事件循环可以去执行其他代码。一旦等待的操作完成,事件循环会唤醒这个被挂起的协程,并从
await之后的地方继续执行,并获取最终结果。
我的选择标准主要基于任务的性质、对性能的控制需求以及资源的生命周期:
- 使用
std::async的场景:对于简单的、一次性的异步任务,我会优先选择std::async。它通过std::future提供了便捷的获取结果的机制,并且由标准库自动管理线程的创建和销毁(虽然可以通过启动策略std::launch::async强制创建新线程,或用std::launch::deferred延迟执行),代码非常简洁。这非常适合“发射后不管”或需要简单等待结果的任务,例如前端快速发起一个后台计算或查询。 - 使用
thread pool的场景:在高性能、高并发或需要精细控制的场景下,我一定会选择线程池。线程池的核心优势在于线程复用,它预先创建并维护一组工作线程,避免了频繁创建和销毁线程带来的巨大开销。这非常适合处理大量、短小、频繁的任务队列,例如 Web 服务器处理海量短连接请求。此外,线程池给予我更大的控制权,我可以明确管理线程数量、任务队列的饱和策略等,从而防止系统资源被无限增长的线程耗尽。
112. Python 和 C++ 语言区别和特点,什么时候用 Python 什么时候用 C++?#
Python 和 C++ 是两种设计哲学和应用领域截然不同的语言。
区别与特点:
- C++:是一种编译型、静态类型的系统级语言。它追求零开销抽象(Zero-overhead Abstraction),提供对硬件和内存的精细控制,性能极高。但代价是语法复杂,需要开发者手动管理内存等资源,开发迭代速度较慢。
- Python:是一种解释型、动态类型的高级语言。它强调代码的可读性和开发效率,语法简洁,拥有庞大的开源库生态。但其运行时性能远低于 C++, 由于其全局解释器锁(GIL)和动态特性。
选择标准:
- 使用 C++:当性能是首要目标,或需要直接与操作系统/硬件交互时。典型场景包括:游戏引擎、高频交易系统、浏览器/数据库等大型基础软件、嵌入式系统、性能关键的中间件等。
- 使用 Python:当开发速度和易用性更重要时。典型场景包括:Web 后端(Django/Flask)、数据科学/机器学习(NumPy/Pandas/TensorFlow/PyTorch)、自动化运维脚本、快速原型验证、以及作为“胶水语言”将各种 C++库粘合起来。
113. 有没有在 Window 上编译开发的经验#
我有在 Windows 平台上进行编译和开发的丰富经验。我的主要工具链是Visual Studio及其集成的 MSVC 编译器,我熟悉其项目属性配置、调试器以及各种构建选项。此外,为了保持项目的跨平台兼容性,我广泛使用 CMake 来生成 Visual Studio 的解决方案(.sln)文件。我也接触过 MinGW-w64 和 Cygwin 这样的 GCC 移植版本,以便在 Windows 上获得类 Unix 的编译环境。对于构建过程的管理,我除了使用 Visual Studio IDE,也熟练使用 MSBuild 命令行动态进行自动化构建和持续集成流程。
114. Linux 下用什么工具去编译#
在 Linux 下,编译的核心工具是 GCC(GNU Compiler Collection)和 Clang。它们是实际的编译器前端/后端,负责将源代码编译成目标文件。
- GCC:是 Linux 生态系统的传统标准,支持语言广泛,非常成熟。
- Clang:以其更快的编译速度、更友好的错误/警告信息以及作为 LLVM 项目的一部分而闻名,近年来应用非常广泛。
- 在实际开发中,我很少直接调用这些编译器,而是通过构建工具来管理复杂的编译过程:
- Make:是最基础和最通用的构建工具。它通过读取 Makefile 文件来定义源文件之间的依赖关系和构建规则,然后调用 GCC/Clang 等编译器进行增量编译和链接。
- CMake:是一个更高级的跨平台构建系统生成器。它读取开发者编写的
CMakeLists.txt文件,然后为底层构建工具(如 Make、Ninja)生成相应的构建文件(如 Makefile)。这使得项目可以轻松地在不同平台和 IDE 之间迁移。 - Ninja:是一个专注于速度的小型构建系统,其构建文件通常由 CMake 或 GN 等高级工具生成,在大型项目(如 Chrome)中能显著提升构建速度。
115. makefile 有什么格式#
Makefile的基本格式由一系列规则组成,每条规则定义了如何从一个或多个源文件(依赖)构建出目标文件。其标准结构如下:
target ... : prerequisites ...
recipe
...
...- target(目标):通常是需要生成的文件名(如
main.o)或一个动作的名称(伪目标,如clean)。 - prerequisites(前置条件/依赖):是生成
target所需要的文件或另一个目标。如果任何前置条件比目标新,make 就会重新构建目标。 - recipe(配方/命令):是make为了构建目标而需要执行的一条或多条Shell命令。这些命令必须以 Tab 字符开头,而不能是空格。
- 此外,Makefile还支持变量(如
CC = gcc)、自动变量(如$@代表当前目标,$^代表所有依赖)、隐含规则和指令(如include),用于使 Makefile 更简洁、更易于维护。
116. Linux 下的 select 和 epoll,这两个有什么不一样#
select和epoll都是 Linux 上用于 I/O 多路复用的系统调用,允许一个进程同时监视多个文件描述符(如 socket)的就绪状态,但它们在设计和性能上差异巨大。
select#
- 机制:采用轮询和线性扫描的方式。每次调用时,内核需要将所有用户传入的文件描述符集合从用户态拷贝到内核态,然后内核线性扫描所有描述符以检查就绪状态。调用返回后,用户程序也需要线性扫描整个集合来找出就绪的描述符。
- 缺点:
- 文件描述符数量有上限(通常为 1024)
- 每次调用都需要重复的拷贝和扫描开销,性能随描述符数量增加而线性下降;
- 需要用户程序自己遍历所有描述符来查找就绪项。
epoll#
- 机制:采用事件回调(基于红黑树和就绪链表)的方式。它通过
epoll_create创建一个上下文,通过epoll_ctl单独地添加或移除要监视的描述符(只需拷贝一次)。epoll_wait调用则等待事件发生,返回时只提供已经就绪的描述符列表,无需扫描全部。 - 优点:
- 支持的文件描述符数量是系统级别的,非常大;
- 避免了每次调用时重复的文件描述符集合拷贝和内核扫描,性能不会随描述符数量增加而显著下降,非常适合连接数巨大的场景;
- 直接返回就绪的描述符,用户程序无需遍历。
总结:
select是 POSIX 标准,跨平台性好,适用于连接数少且对兼容性要求高的场景。epoll是 Linux 特有的高性能机制,是现代高并发网络服务器(如 Nginx, Redis)的首选。
117. malloc 和 mmap 有什么区别,分别在什么场景下使用#
malloc 和 mmap 都用于分配内存,但它们是不同层次的机制,适用于不同场景。
malloc#
- 是 C 库提供的用户层内存分配函数
- 原理:它管理的是堆内存。
malloc通常会先通过系统调用(如brk或sbrk)从操作系统申请一大块内存作为堆,然后使用自己的算法(如ptmalloc)将这块大内存分割、管理,分配给应用程序。它处理的是相对小块的内存分配请求。 - 场景:适用于程序运行过程中频繁分配和释放中小块内存的通用场景,例如创建链表节点、临时字符串、小型数据结构等。它是程序员日常开发中最常用的分配方式。
mmap#
- 是直接由操作系统提供的系统调用
- 原理:它可以在进程的虚拟地址空间中直接创建一个新的内存映射。这个映射可以是匿名映射(不关联文件,只用于分配大块内存,相当于向操作系统直接要内存),也可以是文件映射(将文件直接映射到内存,便于对文件进行随机访问)。
- 场景:
- 分配大块内存:当需要分配的内存非常大(例如几十 MB 甚至 GB 级别)时,使用
mmap直接映射比通过malloc在堆上分配更高效,且避免碎片化问题。 - 文件 IO:用于实现内存映射文件,将文件直接映射到内存空间,这样对内存的读写操作就相当于对文件进行读写,非常高效。
- 进程间共享内存:通过映射同一个文件,可以实现多个进程间的共享内存通信。
- 分配大块内存:当需要分配的内存非常大(例如几十 MB 甚至 GB 级别)时,使用
118. 虚表是一个类有一个还是一个对象有一个?#
类与虚表的关系#
一个类有一个虚表!
编译器在编译期为每个含有虚函数的类生成一张虚表,里面存放该类所有虚函数(以及可能的 RTTI 信息)的函数指针。
如果子类重写(override)了某个虚函数,那么编译器在子类的虚表中把对应槽位替换为子类的函数指针。
对象与虚表的关系#
每个对象有一个虚表指针(vptr)!
当对象被构造时,构造函数会把 vptr 设置为指向该对象所属类的虚表。
因此,同一个类的所有对象共享同一张虚表,只是它们各自的 vptr 都指向这张表。
内存示意图#
struct Base {
virtual void foo();
virtual void bar();
};
struct Derived : Base {
void foo() override;
};编译器会生成两张虚表:Base::vtable 和 Derived::vtable。
在 Base::vtable 里,槽 0 → Base::foo,槽 1 → Base::bar。
🔥 在 Derived::vtable 里,槽 0 → Derived::foo(覆盖了),槽 1 → Base::bar。
每个 Base 或 Derived 对象的起始位置存放一个 vptr,分别指向对应的虚表。
119. 查虚表的时间复杂度是多少#
在 C++ 中,虚函数调用通过虚表实现,其查找过程只需要:从对象中取出虚表指针 vptr,根据已知的偏移量在虚表中找到对应的函数指针,然后执行间接跳转。由于这些步骤都是固定次数的指针访问和寻址操作,与对象数量或虚函数多少无关,所以查虚表的时间复杂度是 O(1),只比普通函数调用多一次间接寻址。
在多继承或虚拟继承中,一个对象可能有多个 vptr。这种情况下,调用某些虚函数时,编译器可能需要多一次指针调整(偏移修正)。但仍然是固定次数的操作,复杂度依然是 O(1)。
120. std::move 的原理(涉及移动吗)#
在 C++ 中,std::move 的作用是将一个对象显式地转换为右值引用,从而让编译器有机会调用该对象的移动构造函数或移动赋值运算符,而不是拷贝版本。
std::move 并不会真的“移动”数据,它只是做了一个 static_cast<T&&> 的强制类型转换,把传入的左值转为右值引用。
一旦对象被当作右值使用,如果该类型定义了移动构造或移动赋值函数,就会发生资源所有权的“转移”,通常只需要指针交换,效率比深拷贝高。
使用 std::move 后,被转移的对象仍然处于有效但未指定状态(可以析构或赋新值,但不能假设它保留旧值)。
121. 智能指针原理#
智能指针是 C++ 标准库中用来自动管理对象生命周期的类模板,本质上是一个“带有内存管理功能的指针包装器”。它的原理可以从以下几个方面理解。
核心思想#
- 普通指针需要手动
delete,容易造成内存泄漏或悬垂指针。 - 智能指针通过 RAII 原则,在智能指针对象析构时自动释放资源。
- 它对指针的操作符
*、->进行了重载,看起来像普通指针,但有更安全的内存管理机制。
std::unique_ptr#
- 独占所有权:同一时间只能有一个
unique_ptr拥有某个对象。 - 原理:
- 内部保存一个裸指针。
- 禁止拷贝(拷贝构造和赋值被
delete),但支持 移动语义(转移所有权)。 - 析构时自动
delete管理的对象。
简化实现
template <typename T>
class unique_ptr {
T* ptr;
public:
explicit unique_ptr(T* p = nullptr) : ptr(p) {}
~unique_ptr() { delete ptr; }
unique_ptr(const unique_ptr&) = delete;
unique_ptr& operator=(const unique_ptr&) = delete;
unique_ptr(unique_ptr&& other) noexcept : ptr(other.ptr) {
other.ptr = nullptr;
}
unique_ptr& operator=(unique_ptr&& other) noexcept {
if (this != &other) {
delete ptr;
ptr = other.ptr;
other.ptr = nullptr;
}
return *this;
}
T& operator*() { return *ptr; }
T* operator->() { return ptr; }
};std::shared_ptr#
- 共享所有权:多个智能指针可以共同管理一个对象。
- 原理:
- 除了指针,还维护一个 引用计数(control block)。
- 每次拷贝
shared_ptr时,计数 +1;析构时,计数 -1;当计数归零,释放对象。
简化实现
template <typename T>
class shared_ptr {
T* ptr;
int* count;
public:
explicit shared_ptr(T* p = nullptr) : ptr(p), count(new int(1)) {}
~shared_ptr() {
if (--(*count) == 0) {
delete ptr;
delete count;
}
}
shared_ptr(const shared_ptr& other) : ptr(other.ptr), count(other.count) {
++(*count);
}
shared_ptr& operator=(const shared_ptr& other) {
if (this != &other) {
if (--(*count) == 0) {
delete ptr;
delete count;
}
ptr = other.ptr;
count = other.count;
++(*count);
}
return *this;
}
};std::weak_ptr#
- 弱引用:不影响对象生命周期,避免
shared_ptr的循环引用问题。 - 原理:
- 持有指向控制块的弱引用计数。
- 不能直接解引用,需要通过
lock()临时获取shared_ptr。 - 当对象已销毁时,
lock()返回空指针。
122. 假设有一个 1KB 的大对象,move 能节省拷贝吗#
当我们在 C++ 中处理一个 1KB 甚至更大的对象时,是否使用 std::move 对性能会有明显影响。如果只进行拷贝,编译器会调用拷贝构造函数或拷贝赋值函数,把这 1KB 的数据逐字节复制到新的内存空间里,这个过程的复杂度是 O(n),而且对象越大,时间和内存消耗就越高。但如果使用 std::move,它会把对象转化为右值引用,从而触发类型的移动构造函数或移动赋值运算符。在标准库容器和大多数现代类的实现中,移动操作通常只是把内部资源的指针或句柄“偷走”,并将源对象的指针清空,这样就避免了逐字节拷贝,复杂度降为 O(1)。换句话说,std::move 并不是直接完成“移动”的动作,而是告诉编译器“这个对象可以被当作右值处理”,从而让类的移动语义生效。结果是:对于像 std::string、std::vector 这样内部依赖堆内存的大对象,使用 std::move 能显著节省拷贝成本,把原本昂贵的内存复制过程简化为一次指针交换,从而大幅提高效率。
123. new 和 malloc 有什么区别呢#
1. 类型安全与返回值#
new:返回的是指定类型的指针,不需要强制类型转换,例如int* p = new int;。malloc:返回void*,必须显式转换为目标类型,例如int* p = (int*)malloc(sizeof(int));。
2. 构造/析构函数调用#
new:除了分配内存,还会自动调用对象的 构造函数,初始化对象;delete会调用 析构函数。malloc:只分配原始内存块,不会调用构造函数;对应的free也不会调用析构函数。
3. 异常与错误处理#
new:分配失败时会抛出std::bad_alloc异常(除非用new(std::nothrow)版本),所以更符合 C++ 的异常处理方式。malloc:分配失败时返回NULL,需要手动检查指针是否为空。
4. 内存大小计算#
new:不需要显式写sizeof,编译器根据类型自动计算内存大小。malloc:必须手动传入字节数,例如malloc(sizeof(MyClass) * 10)。
5. 重载与自定义#
new/delete:可以被用户重载,支持自定义内存分配策略(如内存池)。malloc/free:是 C 语言库函数,不能被重载,只能按标准方式分配。
6. 使用场景#
- 推荐使用
new/delete:管理 C++ 对象,保证构造/析构函数的调用。 malloc/free主要用于 C 接口:或者需要与 C 库交互的场景。
124. 用 new 生成的对象,可以用 free 释放吗#
在 C++ 中,内存管理是成对出现的:
new必须对应deletenew[]必须对应delete[]malloc必须对应free
原因
- 构造/析构函数
new不仅分配内存,还调用对象的构造函数。delete在释放内存之前,会先调用析构函数,再释放内存。- 如果用
free去释放new出来的对象,析构函数不会被调用,会造成资源泄漏(比如没有关闭文件、释放锁、释放堆内存等)。
- 运行时实现不同
- C++ 编译器对
new/delete可能有自己的内存分配策略(比如对象对齐、内存池)。 malloc/free走的是 C 语言标准库的堆分配接口。- 混用可能导致堆结构损坏,甚至程序崩溃。
- C++ 编译器对
正确做法
- 用
new分配 → 用delete释放。 - 用
new[]分配数组 → 用delete[]释放。 - 用
malloc分配 → 用free释放。
125. 如果 new 基础类型,比如整型,可以用 free 释放吗#
即使是 int 这样的基础类型,用 new 分配的对象也必须用 delete 来释放,而不能用 free,因为在 C++ 中 new/delete 与 malloc/free 属于两个完全不同的内存管理体系,虽然 int 没有构造和析构函数,看似没有区别,但 new 在分配时可能会附加一些编译器特定的元信息,释放时需要 delete 正确处理,否则就会触发未定义行为;因此,哪怕是最简单的基础类型,也要严格遵循成对使用 new/delete、malloc/free 的规则,才能保证程序的正确性和可移植性。
126. 用 new 创建数组时,释放的时候需要写出元素个数吗#
用 new 创建数组时,释放的时候并不需要写出元素个数,只要保证使用 delete[] 而不是 delete 即可。比如:
int* arr = new int[10];
delete[] arr; // 不需要写 10这是因为编译器在用 new[] 分配数组时,通常会在分配的内存块里额外保存数组的大小信息(比如在头部存储元素数量),这样在执行 delete[] 时,它就能自动知道有多少个元素需要调用析构函数。反过来,如果你错误地用 delete arr; 来释放一个 new[] 出来的数组,就只会对第一个元素调用析构函数,其余元素不会被正确销毁,导致资源泄漏或未定义行为。
127. std::map 和 B+ tree 有什么区别呢#
std::map 多用于内存里的有序关联容器,底层常用红黑树实现,而 B+ 树是数据库和文件系统常用的磁盘友好型索引结构,前者注重通用性和内存效率,后者注重降低磁盘 I/O 和范围查询性能。
数据结构和实现
std::map:在 C++ 标准库里通常实现为 红黑树(自平衡二叉查找树)。它的每个节点存储一个键值对(key, value),树高大约是O(log n),支持快速查找、插入和删除。- B+ 树:属于多路平衡查找树,常用于数据库和文件系统。B+ 树的节点可以存放多个键,非叶子节点只保存索引信息,所有数据都放在叶子节点,叶子节点之间用链表相连,便于范围查询和磁盘顺序访问。
时间复杂度
两者在理论上的查找、插入、删除复杂度都是 O(log n)。区别在于:
std::map的红黑树一般是二叉树,高度相对较高(大约log₂ n)。- B+ 树是多路的(阶数可达上百甚至上千),树高很低(大约
logₘ n,m 通常远大于 2),因此在磁盘 I/O 场景下效率更高。
内存和存储
std::map是内存型数据结构,适合内存中存储少量到中等规模数据。- B+ 树设计初衷就是面向磁盘,节点大小通常和磁盘页对齐(比如 4KB),减少磁盘 I/O 次数,特别适合大规模数据的索引结构。
范围查询
std::map可以通过迭代器顺序遍历,但元素分布在树节点里,缓存局部性较差。- B+ 树所有数据存储在叶子节点,并且叶子节点通过链表连接,天然支持高效的范围查询和顺序扫描,非常适合数据库中的
BETWEEN查询。
使用场景
std::map:内存中需要有序字典映射的场景,如符号表、配置表等。- B+ 树:数据库索引、文件系统目录、键值存储引擎等大规模、基于磁盘的数据管理。
128. 红黑树与 B+ Tree 的性能、内存空间占用对比#
从性能角度比较 std::map(红黑树) 和 B+ 树,主要差异在于它们设计时针对的场景不同:
性能#
1. 内存场景#
在内存中存放数据时:
std::map往往更合适。它是二叉平衡树,节点存储较紧凑,指针操作简单;对查找、插入、删除的复杂度都是O(log n),常数因子较小。- B+ 树 在内存里因为是多路节点,访问时需要在节点内部做一次线性查找或二分查找,常数因子比红黑树大一些,在数据量不算特别大时反而不如红黑树快。
2. 磁盘/大数据场景#
当数据量非常大、不能完全放入内存,需要频繁访问磁盘时:
- B+ 树 更高效。它的节点大小和磁盘页对齐(比如 4KB 一页),一次磁盘 I/O 可以读入几十甚至几百个键,树高非常低(常见情况下只有 2~4 层),大大减少了磁盘访问次数。
std::map设计时并没有考虑磁盘访问,二叉树节点很分散,局部性差,如果把它用在磁盘数据结构上,I/O 开销会非常大。
3. 范围查询#
- B+ 树 的叶子节点用链表串联起来,做范围查询或顺序遍历时几乎是顺序扫描,效率很高,适合数据库中的
WHERE x BETWEEN ...。 std::map也能用迭代器遍历,但因为节点分散在内存,缓存命中率差,性能不如 B+ 树。
空间占用#
1. std::map(红黑树)#
- 每个节点只保存一个键值对
(key, value),外加几个指针(父、左、右,可能还有颜色位)。 - 因为是二叉树,指针开销相对较大,尤其是当 key 和 value 本身比较小的时候,指针反而成了主要开销。
- 节点分散在堆上分配,内存局部性差,缓存命中率低。
举例:一个
std::map<int, int>节点,数据只占 8 字节,但可能要额外存储 3–4 个指针(24–32 字节),加上对齐,内存开销可能是实际数据的几倍。
2. B+ 树#
- 一个节点存储多个键和子指针,通常会填满一个固定大小的页(比如 4KB)。
- 因为是多路树,树高更低,指针数量远少于红黑树。
- 数据集中存放在叶子节点,且叶子节点通过链表连接,空间利用率更高,局部性也更好。
- 在数据库中,B+ 树的节点大小一般和磁盘页对齐,因此不仅节省内存,还能最大化磁盘 I/O 的效率。
3. 对比总结#
- 内存占用上:红黑树(
std::map)因为每个节点只存一个元素,加上大量指针,空间效率偏低;B+ 树每个节点存很多元素,指针摊薄,空间效率明显更好。 - 局部性上:B+ 树更紧凑、连续,缓存命中率高;红黑树分散,缓存命中率差。
129. 为什么数据库里选择 B+Tree 而不是红黑树?#
数据库里选择 B+Tree 而不是红黑树,核心原因是二者的设计目标不同:
1. 磁盘访问成本#
数据库面对的是远超内存容量的大规模数据,数据通常存放在磁盘里。
- B+Tree:多路搜索树,一个节点可以容纳上百甚至上千个关键字,正好对应一个磁盘页(如 4KB)。一次磁盘 I/O 就能读入很多关键字,树的高度非常低(常常 2~4 层),意味着一次查询只需要少量磁盘访问。
- 红黑树:二叉树,每个节点只存一个关键字,树高约为
log₂n,高度远高于 B+Tree。查找时要访问更多的节点,对应更多的磁盘 I/O,性能会非常差。
2. 顺序访问和范围查询#
数据库里非常常见的操作是范围查询,比如 WHERE age BETWEEN 20 AND 30。
- B+Tree:所有数据都在叶子节点,叶子节点之间用链表相连,顺序遍历或范围扫描时只需要顺着链表走,效率极高。
- 红黑树:虽然中序遍历可以得到有序结果,但节点分散,指针跳转频繁,对磁盘和缓存都不友好,顺序扫描效率低。
3. 空间与局部性#
- B+Tree:节点内的数据是连续存放的,空间利用率高,局部性好,CPU 缓存和磁盘预读都能发挥作用。
- 红黑树:每个节点单独分配,指针开销大,内存局部性差,缓存和预读效果差。
4. 实际应用#
- B+Tree:被广泛用于数据库索引(MySQL、PostgreSQL、Oracle)和文件系统(NTFS、HFS+ 等),因为它能有效减少磁盘 I/O 并支持高效范围查询。
- 红黑树:常用于内存场景,比如 C++ STL 的
std::map、std::set,在内存里做有序字典或集合很合适。
130. 在 STL 里,内存池是怎么实现的,有怎样的结构?#
在 SGI STL 中,内存分配器分了两层。第一层直接调用 malloc/free,主要处理大块内存(一般大于 128 字节),这种情况下它不再做额外优化。第二层才是所谓的 内存池机制,专门用来管理小对象(≤128 字节)。
这层内存池内部维护了 16 个自由链表(free lists),每个链表对应固定大小的内存块,大小从 8 字节到 128 字节,按 8 字节递增。比如需要分配 20 字节时,分配器会把它“上调”到 24 字节,然后从 24 字节对应的自由链表中取一个小块。如果链表里有可用内存,就直接返回;如果为空,就调用一个名为 refill 的函数。
refill 的作用是一次性从堆里申请一大块内存(比如 4KB),把它切成若干个小块挂到自由链表上,供后续使用。这样下一次再分配同样大小的小对象时,就可以直接从链表里取,而不必再调用 malloc。这种批量获取、切分、回收的方式大大减少了系统调用次数。
在结构设计上,每个小块内存的前几个字节都会存储一个指针,指向同类下一个空闲小块,从而形成单链表。释放对象时,并不会真的把内存交还给系统,而是把小块重新挂回对应的链表,等待下次复用。这样回收操作也只需要修改指针,几乎是 O(1) 的操作。
除了自由链表,SGI STL 的内存池还维护一个全局的“内存起始指针”和“内存结束指针”,用来追踪尚未切分的小块。当某个自由链表需要补充小块时,就从这段区域里分配,如果不够再向系统申请更大的内存块。
对比现代 C++ 标准库的 std::allocator,它通常只是对 ::operator new 的简单封装,不会自带复杂的池化机制。但由于 STL 容器都通过分配器抽象来管理内存,所以你完全可以自己实现类似 SGI STL 的 allocator,然后把它作为模板参数传给容器,从而让 STL 容器使用内存池。
其结构和工作原理如下:
- 核心结构:自由链表
- 内存池维护一个自由链表数组(例如16个),每个链表管理一种特定大小(8B, 16B, 24B…通常为8的倍数)的内存块。
- 每个空闲内存块的开头是一个指向下一个空闲块的指针(
union _Obj { _Obj* _M_free_list_link; ... }),将这些块串成一个链表。
- 分配过程(allocate):
- 计算所需内存大小,对齐后找到对应的自由链表。
- 如果链表不为空,直接从链表头取出一块内存返回给用户。这只需要修改几个指针,速度极快。
- 如果链表为空,则调用
_S_refill函数向内存池“申请批发”。- 内存池会一次性分配一大块内存(例如20个对象的大小)。
- 将这大块内存切割成一个个小块,并用指针串起来,形成新的自由链表。
- 然后从这条新链表中取出一块返回给用户。
- 释放过程(deallocate):
- 收到用户释放的指针,根据其大小找到对应的自由链表。
- 直接将这块内存插回对应链表的头部(修改指针即可)。它不会立即归还给操作系统,而是留在链表中以备下次分配。
131. 执行 vector<int> v(4, 100) 会发生什么,在栈上还是堆上分配?#
当你写下 vector<int> v(4, 100); 时,首先会调用 std::vector 的构造函数,它接收两个参数 (size_type n, const T& value),表示创建一个长度为 n 的向量并将所有元素初始化为 value。在这个例子里,n = 4,value = 100,所以最终生成的是一个长度为 4 的向量,内容为 [100, 100, 100, 100]。
需要注意的是,v 本身是一个局部变量,它作为一个对象存放在栈上,其中保存着三个核心信息:指向存储区的指针、当前元素个数 size 和当前容量 capacity。而那 4 个 int 元素并不是直接放在栈里的,而是由 vector 内部通过动态内存分配(通常使用 new)在堆上申请一块连续的内存空间来存放的。这样做的好处是容器可以根据需要扩容,而不受栈空间大小的限制。
因此,整体过程可以总结为:vector<int> v(4, 100); 会生成一个长度为 4、所有元素值都为 100 的向量,其中容器对象本身在栈上,而实际存储元素的空间在堆上。
132. 那如果是 new vector<int>(4,100) 呢#
当你写成 new vector<int>(4, 100) 时,和直接 vector<int> v(4, 100) 的区别主要在于 容器对象本身的位置。
在 vector<int> v(4, 100); 这种形式里,v 是一个局部变量,它作为对象存放在栈上,里面包含了三个核心成员:指向堆上元素存储区的指针、size、capacity。而那 4 个 int 元素依然是通过 new 在堆上分配的一块连续内存保存的。
而在 new vector<int>(4, 100) 这种形式里,情况就变成了两层堆分配:
new vector<int>本身会在堆上生成一个vector对象,这个对象里包含指针、size和capacity。- 在构造函数执行过程中,
vector内部还会在堆上再分配一块内存,存放那 4 个int元素,并全部初始化为100。
因此,可以总结为:
vector<int> v(4, 100);→ 对象在栈上,元素在堆上。new vector<int>(4, 100)→ 对象本身在堆上,元素依然在堆上。
使用 new 的版本返回的是一个指针(类型为 vector<int>*),所以一般需要用 delete 手动释放,否则会造成内存泄漏;而直接定义在栈上的 vector,在作用域结束时会自动调用析构函数,释放堆上的元素存储区,更加安全。
133. 如何拿到类中私有成员变量的值?#
在语法层面,私有成员就是不能直接访问的,这是 C++ 的语言设计。你如果真要拿到值,只能靠 友元(正规的方式)或者通过 指针偏移、调试器、反射库 之类的手段绕过,但这些都破坏了封装性,容易出问题。
正规途径#
- 提供访问接口:最推荐的做法是类内部提供
getter方法,或者通过友元(friend)函数/类来获取。这样遵循语法规则,保证代码可维护性。 - 友元机制:可以显式指定某个函数或类为友元,从而访问私有成员。
非正规途径(绕过语法限制)#
这些方法属于“黑科技”,更多是为了学习/调试用,工程里一般不建议:
通过指针偏移(内存布局)#
类对象的内存里,私有成员和公有成员是按编译器布局存放的,访问权限只存在于编译阶段。拿到对象地址后,可以通过 reinterpret_cast 或指针算偏移,直接读到对应位置的数据。
class Test {
private:
int a = 42;
};
int main() {
Test t;
int* p = (int*)&t; // 直接把对象地址转成 int*
std::cout << *p << std::endl; // 打印出私有成员 a
}这种做法利用了内存布局,但属于未定义行为,不可移植。
宏/模板技巧#
有些人会用模板 + 偏特化或者宏展开来“欺骗”编译器访问私有成员,不过实现复杂,常用于 C++ 奇技淫巧展示。
gdb#
在调试环境下,可以通过 gdb/lldb 等调试器直接读取对象内存,或者用 Boost.PFR(Precise Function Reflection)等库在编译期推断对象的字段布局。
134. 有一个二维数组里面都有值,想要给每个数都加 100,行遍历和列遍历有什么区别?#
在一个二维数组里,如果你要给每个元素都加 100,从结果上看,无论是按行遍历还是按列遍历,数组中的所有数都会变大 100,结果完全相同。但这两种遍历方式在底层运行效率上差别很大。
二维数组在 C/C++ 中是 行优先存储(row-major order)的,也就是说,一整行的数据在内存中是连续存放的,不同行之间是隔开的。行遍历时,访问顺序与内存布局一致,CPU 每次加载的缓存行和虚拟内存页都会被充分利用,缓存命中率高,虚拟内存的局部性原理得以发挥,性能较好。而列遍历则不同,相邻元素在内存中相隔一个整行的大小,访问时会“跳着走”。这导致 CPU 每次加载的缓存行里只有极少数数据被使用,缓存利用率低,大数组时还会频繁触发新的虚拟页调入和缓存替换,带来额外的开销。
所以,从虚拟内存和缓存的角度看,行遍历符合空间局部性,效率高;列遍历破坏局部性,效率低。在数据量小的时候差别可能不明显,但在大规模数组或矩阵计算里,性能差距会非常显著,这也是科学计算和数据库引擎里都特别强调数据访问模式与存储布局匹配的原因。
135. 关于静态多态和动态多态原理 (Leelham)#
静态多态#
静态多态都是通过 name mangling 实现的。name mangling 是一种编译器技术,用于为程序中的变量和函数生成唯一的内部名称。mangling 规则具体看编译器。
具体包括:
- 函数重载:指在同一个作用域内,名称相同的函数参数类型或参数个数不同,从而可以根据调用时提供的实参来确定实际调用的函数
函数重载实现参数多样性。函数返回值多样性可以用 variant(可以再传一个模板参数,内部基于模板参数对 variant 进行转化)
- 隐藏:指在子类中定义父类同名同参数函数
- 模板:指编译时根据传递的模板参数不同,生成不同的代码
- CRTP(奇异模板递归):通过继承自己(在子类中使用父类模板),允许在编译时进行多态操作,避免动态分发查虚表的开销。
std::enable_shared_from_this即通过 CRTP 实现。玄学:就像在心理学中,自我认知(Self-awareness)是理解个体行为的关键一样,CRTP 通过使基类能够“意识”到其派生类的类型,从而在编译时实现多态性
- interface 内部可以配合
if constexpr和std::is_same_v对某些类型做特殊处理
cpp// CRTP 基类 template<typename Derived> class Base { public: void interface() { // 静态多态:在编译时调用Derived的implementation static_cast<Derived*>(this)->implementation(); } // 一些公共的接口和实现... }; // CRTP 派生类 class Derived : public Base<Derived> { public: void implementation() { // 特定于Derived的实现... } }; int main() { Derived d; d.interface(); // 调用Derived的implementation } - interface 内部可以配合
动态多态#
-
动态多态原理:虚函数实现,底层通过虚函数表实现。
- 对于含有虚函数的类,编译器会在编译阶段创建一个虚函数表 vftable(按照虚函数的声明顺序保存虚函数的地址),并在创建类对象时插入一个虚函数表指针 vfptr,该指向 vftable 的首地址(也就是第一个虚函数的地址)。
- 虚函数表是静态的,供该类的所有对象共享,在编译期确定,存放在全局(静态)变量区的 .rodata 段。
- 虚函数表指针是动态的,该类的每个对象都有一个,在运行期确定,存放位置和对象的存放位置相同(堆区/栈区)。
- 继承时,子类会深拷贝一份父类的虚函数表,如果子类重写了虚函数,那么子类的虚函数表中对应的虚函数地址会被覆盖为重写的虚函数地址。
-
为什么多态函数传参是传指针或者引用,按值传大概率不行?
- 按值传递会导致切片问题,对象的派生特征都会被截切掉,导致派生类的信息丢失,从而无法实现多态;
- 按值传递需要拷贝副本,性能开销大;
-
构造函数和析构函数可以定义为虚函数吗?
- 构造不可以:在继承中,先构造基类再构造子类。如果构造函数是虚函数,则需要通过虚函数表调用,但是此时对象还没有实例化,没有虚函数表指针 vfptr,无法访问虚函数表
- 析构可以:父类不是虚析构,使用父类指针指向子类,就只会调用父类的析构函数,导致子类动态分配的资源无法释放(如果子类数据成员都是基本类型,不使用虚析构函数不会内存泄漏)
-
哪些函数不能是虚函数?
- 构造函数、静态成员函数(编译期确定,不能动态绑定)、友元函数(不能继承)、内联函数(编译器展开,不能动态绑定)
-
菱形继承
-
virtual 关键字虚继承,保证派生类只保留一份间接基类的成员。
-
继承多个类,会导致具有多个 vptr
-
136. 构造函数和析构函数可以定义为虚函数吗?#
- 构造不可以:在继承中,先构造基类再构造子类。如果构造函数是虚函数,则需要通过虚函数表调用,但是此时对象还没有实例化,没有虚函数表指针 vfptr,无法访问虚函数表
- 析构可以:父类不是虚析构,使用父类指针指向子类,就只会调用父类的析构函数,导致子类动态分配的资源无法释放(如果子类数据成员都是基本类型,不使用虚析构函数不会内存泄漏)
137. 哪些函数不能是虚函数?#
构造函数、静态成员函数(编译期确定,不能动态绑定)、友元函数(不能继承)、内联函数(编译器展开,不能动态绑定)
138. 关于构造函数#
-
拷贝构造/赋值函数
默认构造函数、有参构造函数、拷贝构造函数(传参必须是引用方式,否则会无穷递归,因为按值传递时候会继续调用拷贝构造函数)
-
移动构造/赋值函数
- 移动构造函数(必须要加
noexcept,否则如 vector 之类的在扩容时不会调用移动构造,只会调用拷贝构造)。 - 用于将资源所有权从一个对象转移到另一个对象
- 移动构造函数(必须要加
-
深拷贝与浅拷贝
- 浅拷贝:仅复制对象的基本数据类型和指针成员的值,但是不会赋值指针指向的资源,可能导致两个对象共享相同资源;
- 深拷贝:不仅拷贝对象的基本数据类型和指针成员的值,还会拷贝指针所指向的资源。
-
右值引用与完美转发
- 值分为左值(可以取地址,有名字)和右值(不可以取地址,无名字)。
std::move用于将左值引用强制转变为右值引用(而非所有权转移)。 - 右值赋值给右值引用变量就有了名字,变为左值,可以被左值引用捕获。
std::forward用于保证函数参数的左值或右值特性被保留,允许函数将参数以几乎完全相同的形式转发给其他函数。
- 值分为左值(可以取地址,有名字)和右值(不可以取地址,无名字)。
139. 关于关键字#
const- 修饰变量:只读变量,不能修改
- 修饰函数:修饰函数的返回值,表示函数的返回值只读,不能被修改;
- 修饰指针:常量指针(int* const)、指向常量的指针(const int*)
- 修饰成员函数:不能修改任何成员变量,因此也只能调用常成员函数
violate:指示变量可能被外部因素更改,防止编译器优化。常见场景:- 多任务环境下各任务间共享的标志应该加 volatile;
- 存储器映射的硬件寄存器通常也要加 volatile 说明,因为每次对它的读写都可能有不同意义
define和inline- define宏定义只在预处理阶段起作用,仅仅是简单的文本替换,没有类型检查;
- inline 在编译阶段进行替换,有类型检查
- 内联的好处
- 减少函数调用开销,函数调用涉及压栈、传参、弹栈,内联展开避免了这些开销,直接在调用点插入函数体;
- 减少跳转和缓存不命中
static- 修饰全局变量
- 将变量作用域限制在当前文件中,其他文件无法访问;
- static 变量可以定义在头文件中,并不破坏单一定义原则
- 修饰局部变量:静态局部变量在函数调用结束后并不会被销毁,而是保留其值,并在下一次调用该函数时继续使用;
- 修饰成员变量:成为静态成员变量,属于整个类,在所有实例之间共享;
- 修饰成员函数:静态成员函数,可以直接通过类名来访问,而无需创建对象,没有 this 指针。
- 修饰全局变量
extern- 声明外部变量或函数,使得不同的源文件共享相同的变量或者函数
- extern “C”:可以让 C++ 来调用 C 语言当中的变量或函数(因为 C++ 函数会进行 name mangling,C 的不会,所以不能直接调用)。不使用该关键字,直接调用 C 语言中的变量或函数会发生链接错误。
- 类型转化(
static_cast用于编译期安全的类型转换(如基本类型转换、父类子类指针转换);dynamic_cast用于多态类型的向下转换,在运行时检查类型安全性,失败返回空指针;const_cast用于移除或添加 const/volatile 属性;reinterpret_cast用于低层次的强制类型转换(如指针转整数),不进行类型检查,需谨慎使用)static_cast:基本数据类型间转换,如 int 转为 double,也可以用于基类和派生类间的上行转换(派生类指针—>基类指针)。dynamic_cast:主要用于基类和派生类间的安全类型转换,运行时执行安全检查,要求基类必须有虚函数。流程:- 首先,dynamic_cast 通过查询对象的 vptr 来获取其 RTTI;
- 然后,dynamic_cast 比较请求的目标类型与从 RTTI 获得的实际类型。如果目标类型是实际类型或其基类,则转换成功;
- 如果目标类型是派生类,dynamic_cast 会检查类层次结构,以确定转换是否合法;
- 如果在类层次结构中找到了目标类型,则转换成功;否则,转换失败。
const_cast:去 const 属性,常量指针转换为非常量指针,并且仍然指向原来的对象。不可以用在 const 成员方法里复用非 const 成员方法reinterpreter_cast:仅仅重新解释类型,但没有进行二进制的转换
struct和class区别:- struct:结构体中的成员和继承默认都是 public 属性的。
- class:结构体中的成员和继承默认都是 private 属性的,且可以用于定义模板参数
noexcept:表示函数内部不会抛出异常,有助于简化调用该函数的代码,而且编译器确认函数不会抛出异常,它就能执行某些特殊的优化操作。- new/delete 和 malloc/free 区别
new/delete是 C++ 风格,分配/回收空间同时会调用构造/析构,而malloc/free仅管理原始内存,不会自动初始化对象- malloc 需要传入分配的大小返回一个 void 指针。大多数中 malloc 分配的内存前加一个头部,用于存储分配大小以进行 free;new 传入类型信息会自动计算构造对象的大小,delete 不需要额外存储长度,但 delete[] 可能会在内存前存储数组大小。
- 内存不足时,malloc 返回空指针;默认版本 new 会抛出异常 std::bad_alloc,或者使用 new(std::nothrow) 不抛出异常
- new 可以 placement new 就地构造(emplace 相关方法实现原理)
mutable- 修饰类的成员变量,表示可以在 const 成员函数中修改
- 修饰 lambda 函数,表示可以修改值捕获的成员
auto与decltype(C++ 11):编译器在编译期自动推导表达式类型thread_local:指示对象拥有线程存储期,指示对象的存储在线程开始时分配,在线程结束时析构- 可以与 static 和 extern 用于指定内部或外部链接(除了静态数据成员始终拥有外部链接),但附加的 static 不影响存储期
- 只用于于命名空间作用域的对象、块作用域的对象、静态数据成员
补充 push_back 和 emplace_back
// vector emplace_back 和 push_back 实现原理
template<typename T>
class Vector {
private:
T* data_;
size_t size_;
size_t capacity_;
public:
template<typename... Args>
void emplace_back(Args&&... args) {
if (size_ >= capacity_) {
reserve(capacity_ == 0 ? 1 : capacity_ * 2);
}
// 使用 placement new 在末尾直接构造对象
new (data_ + size_) T(std::forward<Args>(args)...);
++size_;
}
void push_back(const T& value) {
if (size_ >= capacity_) {
reserve(capacity_ == 0 ? 1 : capacity_ * 2);
}
// 需要拷贝构造(可能产生不必要的拷贝)
data_[size_] = value; // 或者 new (data_ + size_) T(value);
++size_;
}
};140. 关于内存管理#
-
内存空间(从低到高)
- 代码段:存放程序的二进制机器码
- 数据段 data:存放初始化的全局变量、静态变量和常量
- bss 区:存放未初始化的全局变量和静态变量
- mmap 区:存放动态库(共享库)、匿名映射(malloc 大块内存)和文件映射(mmap 文件);动态内存管理
- 堆区:由低向高增长。用于动态分配内存(malloc/free,new/delete),如果没有及时释放内存会造成内存泄漏。因为存在内存管理、地址映射等复杂操作,故效率较低。此外还会产生内存碎片影响效率。但空间大
- 栈区:由高向低增长。存放局部变量、函数参数值、形参等。由编译器分配和释放,栈区只需要改变栈指针的位置,因此效率高。但栈区空间小
-
各种变量存放位置
- 直接声明的变量、函数实参存储在栈区;
- new 创建的对象,较小的对象存放在堆区,较大的对象存放在共享内存区;
- 常量和静态变量存放在静态存储区中的非代码区;
- 所有函数存放在静态存储区中的代码区;
- 字符常量也存放在代码区。
-
allocator 与 placement_new:原来,new = 内存分配 + 调用构造函数,借助这两个工具实现内存分配与对象构造分离。
- allocator 可以实现自定义内存分配回收的逻辑,分配回收不会调用构造/析构
http://www.cnblogs.com/wpcockroach/archive/2012/05/10/2493564.html ↗
- stl 容器支持传入自定义的 allocator。
- placement_new 用于在指定的内存地址上构造对象,需要保证可用空间 ≥ 对象实际大小
- 可用于实现标准库的 emplace 方法,原地构造对象
- allocator 可以实现自定义内存分配回收的逻辑,分配回收不会调用构造/析构
-
内存泄漏:申请了一块内存空间,使用完毕后没有释放掉。
- 设计上:基于 RAII,借助智能指针避免资源泄露。
- 检测方法:
- 使用 GDB,执行某个函数前后,call malloc_stats(),对比 in use bytes 大小是否变化
- 使用 valgrind,
valgrind --leak-check=yes program arg1 arg2 - 修改代码,在 new/delete 处加一个计数器检测
-
如何区分 32 位机器和 64 位机器?用
sizeof(void*)- 在 32 位系统 中,指针是 4 字节,可以寻址 4GB 内存。
- 在 64 位系统 中,指针是 8 字节,可以寻址 16GB 内存。
141. 关于内存对齐#
-
对齐系数
- 绝对对齐系数:每种类型数据在内存中的首地址必须是绝对对齐系数内存系数的整数倍。在默认情况下,绝对对齐系数等于该类型数据的默认对齐系数。
- 相对对齐系数:结构体内的数据相对于结构体起始地址的偏移量,单位为字节,结构体成员在结构体中的偏移量必须是该成员相对对齐系数的整数倍。在默认情况下,相对对齐系数等于该类型数据的默认对齐系数。
-
默认对齐系数:绝对对齐系数和相对对齐系数等于默认对齐系数(数据的固有属性)。
-
对于基本数据类型,默认对齐系数等于该数据类型占用字节大小。在内存中的地址必须是其自身大小(以字节为单位)的整数倍;
-
对于结构体类型:(1) 结构体的起始地址必须是结构体成员中占用空间最大的基本数据类型的整数倍,且结构体大小也必须是其整数倍;(2) 结构体内的成员,在结构体中的偏移量必须是该成员相对对齐系数的整数倍。
由于默认对齐的原因,
struct {char a; int b; }的 size 是 8 字节
-
-
显式内存对齐
- #pragma pack(N)(编译器支持):N 需要为 2 的正数
- 当
N大于该结构体的默认对齐系数时候,结构体绝对对齐系数被设置为N,当N小于该结构体的默认对齐系数时候,结构体绝对对齐系数维持为默认对齐系数。 - 当
N小于该结构体的默认对齐系数时候,结构体内所有成员的相对对齐系数被设置为N,当N大于该结构体的默认对齐系数时候,结构体内成员的相对对齐系数维持为默认对齐系数。
- 当
- alignas(N):仅指定结构体的绝对对齐系数(规则同上),不能指定相对对齐系数
- alignof(T):用于获取指定类型的对齐系数
- std::aligned_storage:创建固定大小和满足对齐要求的未初始化内存
- #pragma pack(N)(编译器支持):N 需要为 2 的正数
-
用途
-
提高性能:字是 CPU 在一次内存读写操作中能处理的最大数据块。变量占据内存大小等于字长,如果其首地址在字长的整数倍处,CPU只需要读内存一次;如果其首地址不在字长整数倍处,CPU则需要读地址两次,影响程序性能。
-
避免伪共享问题:多个 CPU 同时对同一个缓存行的数据进行修改,导致 CPU cache 的数据不一致,缓存失效,需要频繁从内存中重新读取数据
为什么伪共享只发生在多线程的场景,而多进程的场景不会有问题?这是因为 linux 虚拟内存的特性,各个进程的虚拟地址空间是相互隔离的,也就是说在数据不进行缓存行对齐的情况下,CPU 执行进程 1 时加载的一个缓存行的数据,只会属于进程 1,而不会存在一部分是进程 1、另外一部分是进程 2。
-
SIMD 指令需要内存对齐
x86 平台下的 SSE (Streaming SIMD Extensions)指令为例来说明内存对齐在 SIMD 中的应用。该架构使用128位的向量寄存器,数据总线长度位128位,每次能读取16字节。
cppalignas(16) float A[4]; alignas(16) float B[4]; alignas(16) float C[4]; for (int i = 0; i < 4; i++) { C[i] = A[i] + B[i]; }由于浮点数默认是按照 4 字节对齐的,数组的首地址是4的倍数,因此如果数组没有进行显式对齐,那么每次计算4个浮点数可能就需要进行两次内存读写。然而,由于数组已经按照16字节对齐,每次计算4个浮点数就只需要进行一次内存读写。
-
direct I/O 需要内存对齐
-
142. 关于异常#
- 异常处理:当异常发生时,会进行栈展开 stack unwinding:
- 将暂停当前函数的执行,开始查找匹配的 catch 子句:首先检查 throw 本身是否在 try 块内部,如果是,检查与该 try 相关的 catch 子句,看是否有匹配的 catch。如果不能处理,就退出当前函数,并且释放当前函数的局部对象,继续到上层的调用函数中查找,直到找到一个可以处理该异常的 catch 。当处理该异常的 catch 结束之后,紧接着该 catch 之后的点继续执行。
- 未捕获的异常将终止程序:如果找不到匹配的 catch,程序就会调用库函数 std::terminate
- 异常安全:stack unwinding 只对栈上的变量进行析构,堆上的动态分配的 new 不会自动析构,所以可能内存泄漏
- 不希望抛出异常的函数
-
析构函数(会导致异常不安全)
- 析构函数往往不仅仅释放一个资源。当前一个资源释放时抛出异常,此时跳过异常点后面的代码,使得后一块资源没有释放,造成内存泄漏。
- vector 析构所有元素时,那么当有一个元素抛出异常,此时 catch 之后的处理显然是继续销毁剩下的元素,但是假设运气很不好,又有一个元素抛出异常,c++此时无能为力,要么结束执行,要么发生不预期的行为
-
移动赋值函数
- 在 STL 标准库中很多容器在 resize 时都会通过
std::move_if_noexcept模板来判断元素是否提供了 noexcept 的移动赋值,如果提供那么 move,否则调用拷贝赋值函数。所以不抛出异常的移动赋值函数效率会更高。
- 在 STL 标准库中很多容器在 resize 时都会通过
-
swap 函数
- 根据 copy and swap 惯用法,swap 是移动赋值基时。swap 不抛异常,移动赋值才不抛异常。
-
- 析构函数发生错误(c++11 之后,默认会把析构函数看成
noexcept(true),这意味着如果析构函数抛出异常,直接std::terminal):- try catch 吞下异常,除记录日志外,不做任何事
- 直接终止程序
- 释放会失败的资源,释放放在非析构函数中,由程序手动操作
- copy - and -swap
- 好处:强异常安全、自复制安全、代码复用
- 强异常安全:如果 new 失败,即在值传递时,创建新的副本就会发生异常,此时 this*被没有被 delete。不会出现 this * 被 delelte,而 new 失败导致对象不完整的情况
- 自复制安全:因为值传递是开辟新的副本,所以赋值没有问题,至于自拷贝的效率问题,一般不怎么出现自拷贝,所以在其他优点下,这点效率小瑕疵就忽略不计
- 代码复用:拷贝赋值运算、移动赋值运算符、swap 函数共用一份代码。对于赋值函数只需写值传递的
operator=(T),无需同时写operator=(const T&)和operator=(T&&)。
- swap 实现:分为 member和non-memeber。
- member:由于 non-member 不能访问类成员,所以我们先实现 member,然后 non-member 调用
cppfriend void swap(dumb_array& first, dumb_array& second) noexcept { using std::swap; swap(first.mSize, second.mSize); swap(first.mArray, second.mArray); // std::swap这里是非常高效的,只是换指针 } - non-member:非模板类可以直接全特化 std::swap;模板类由于 std::swap 不支持偏特化,需实现第三方 swap。在外界调用 swap 时,拒绝直接写
std::swap,而应该写using std::swap; swap(item1,item2);,得益于 ADL(argument dependent lookup)机制,总是能匹配正确的 swap。 通过 using,把 std::swap,还有参数的类型 widget 所在命名空间下的 swap 都纳入函数候选集,在这个候选集中找到最优匹配的函数:class template 类匹配到 WidgetStuff 命名空间的 swap,而其他会匹配到std::swap。
cppint main(){ Widget widget1,widget2; using std::swap; swap(widget1,widget2); }
- member:由于 non-member 不能访问类成员,所以我们先实现 member,然后 non-member 调用
- 实现:实现参数构造和拷贝构造,用 swap 实现移动构造,用
operator=(T)同时实现operator=(const T&)和operator=(T&&)。如果是左值那么会调用拷贝构造函数去初始化函数参数;如果是右值那么会调用移动构造函数去初始化函数参数。
- 好处:强异常安全、自复制安全、代码复用
143. 关于编译/链接#
误区 1:区分动态/静态链接 and 动态/静态库。前者是一个过程,包括合并符号、复制代码段、利用重定位表回填外部符号等;后者是可链接的文件,由于静态/动态链接需要,有不同的数据结构。
误区 2:静态库含义是说链接时,其代码会拷贝到最终可执行文件中,而不是说其存储自身依赖库的代码。其只是在符号表中记录依赖关系,链接静态库时仍然需要链接静态库本身依赖的库。
-
符号重定义(Symbol Redefinition):指的是在同一个作用域内多次定义同名标识符(包括变量、函数、类等)
- 预处理阶段错误:同名宏
- 编译错误
- 名称冲突:同一作用域或不同作用域内出现了相同的符号名定义
- 头文件多重包含:当一个源文件包含多个头文件时,某个头文件可能会包含一个已经包含过的头文件,导致同一个函数或变量的定义被重复包含
- 链接错误:多个编译单元中出现了相同的符号定义而导致的。这种错误会在链接时被检测到,表示无法解析符号引用,因为有多个定义存在。 目标文件头 ELF Header 内存放有符号信息,把多个目标文件链接到一起的时候,若发现文件头内有同名符号,就会报链接期符号重定义错误。符号表结构如下:
- 运行期错误:在动态链接库或共享对象中,函数或变量可以在运行时加载和卸载。如果在两个动态链接库中定义了相同名称的函数或变量,它们可能会导致符号重定义错误。
-
解决符号重定义方法
- 命名空间:解决同名宏、名称冲突
#pragma once或者使用#ifdef包裹#include:解决头文件多重包含- 解决链接冲突
static关键字:将变量或函数限制在当前文件的作用域内,即使两个目标文件有同名变量,也不会报符号重定义错误。在目标文件 ELF 符号表中,被
static修饰的变量会被标记为本地符号 (Local Symbols),链接器检测到两个或者多个目标文件 ELF 符号表内有同名符号,若这个符号是本地符号,则认为它们是不同变量。inline关键字:将函数或者变量声明为内联类型时,即使两个目标文件有同名变量,也不会报符号重定义错误。在 ELF 符号表中,被
inline修饰的函数会被标记为弱符号(Weak Symbol),链接器检测到两个或者多个目标文件 ELF 符号表内有同名符号,那么选择其中占用空间最大的那一个,比如变量 a 在目标文件 A 中是 int,在目标文件 B 中是 double,那么选择 double 型的符号进行链接。extern关键字:在一个编译单元中使用extern关键字来声明一个变量或函数,并在另一个编译单元中定义该变量或函数,在链接时不会发生符号重定义的问题。在 ELF 符号表中,被
extern声明的符号会被标记为未定义,链接器检测到两个或者多个目标文件 ELF 符号表内有同名符号,若这些符号只有一个已定义,其余都是未定义,则认为这些符号共用这一个已定义的值。const关键字:将变量或函数限制在当前文件的作用域内,即使两个目标文件有同名变量,也不会报符号重定义错误。在目标文件 ELF 符号表中,默认情况下,被
const修饰的变量会被标记为本地符号 (Local Symbols),链接器检测到两个或者多个目标文件 ELF 符号表内有同名符号,若这个符号是本地符号,则认为它们是不同变量。
-
编译流程
- 预处理(
gcc -E):主要处理 #include 指令,宏替换,条件编译等,生成 .i 文件 - 编译(
gcc -S):对源代码进行语法分析、词法分析,生成汇编代码,产生 .s 文件, - 汇编(
gcc -c):将汇编代码翻译成机器码,生成 .o 目标文件 - 链接(
gcc):将目标文件和库文件链接在一起,生成最终的可执行文件
- 预处理(
-
ELF 文件:分为可执行文件和可链接文件。可链接文件有:目标文件、动态链接库、静态链接库
- ELF Header(ELF 文件头):文件的开头部分,记录了文件的基本信息,通过其中的字段信息可以找到 Section Header Table 的位置;
- Section Header Table(节区头表):描述 ELF 文件中所有 section 的位置信息;
- 用于链接的 Section
- Symbol Table(符号表)存放有当前文件内所有符号——文件内定义的符号,以及在当前文件内被使用但未定义的符号。符号表记录了每个符号的符号名以及符号值,即与这个符号对应的函数或者变量地址。
- Relocation Table(重定位表)只存放了当前文件内被使用但未定义的符号。重定位表记录了这些符号的符号名以及地址。和符号表中的地址不同,这里的地址,指的是需要被重定位的指令(或数据)在代码段(或数据段)中的偏移位置。例如,需要对跳转指令
callq xxxx进行重定位,这里的地址指的是xxxx所在位置的地址,而不是xxxx指向的地址。
- 动态库的 Section
- GOT 表(Global Offset Table)全局地址偏移量表:在动态链接库被加载时被填充。GOT 表用于保存所有用到的函数或者变量地址。
- PLT 表(Procedure Linkage Table)代码段表:每个外部符号在 PLT 表中都有一个对应的代码段,这些的执行逻辑都是一样的,负责延迟绑定。
-
动态链接与静态链接
- 静态链接:静态库中的代码和数据是链接时复制到可执行文件中的,而不是运行时加载到进程中的。
- 读取每个可链接文件中的符号表,将所有符号表合并到一张总的符号表中,并且对符号表进行排序和去重;
- 将可链接文件合并;
- 遍历每个可链接文件中的重定位表,然后对于每个重定位项:根据符号名从总的符号表中查找到与符号名对应的函数或者变量的实际地址,将重定位项的地址信息替换成实际地址。
- 动态链接:动态库的代码和数据运行时加载到进程中。可执行文件只包含了程序本身的代码和一些对共享库函数的调用,但是并未复制共享库代码到可执行文件中。
- 读取每个可链接文件中的符号表,将所有符号表合并到一张总的符号表中,并且对符号表进行排序和去重;
- 把各个可链接文件,映射到同一个虚拟地址空间中;
- 遍历每个可链接文件中的重定位表,然后对于每个重定位项:将重定位项的地址信息替换成 PLT 表某一项的地址;
- 当程序第一次调用某个外部函数时,跳转到 PLT 表,执行 PLT 表项内的代码,PLT 代码段会先根据总的符号表信息,查找到外部函数地址,填写到 GOT 表中,并跳转到外部函数所在地址,执行函数;
- 当程序再次调用该外部函数时,仍然是先跳转到 PLT 表,执行 PLT 表项内的代码,不同的是它会从 GOT 表中获取外部函数地址,然后跳转到外部函数所在地址,执行函数。
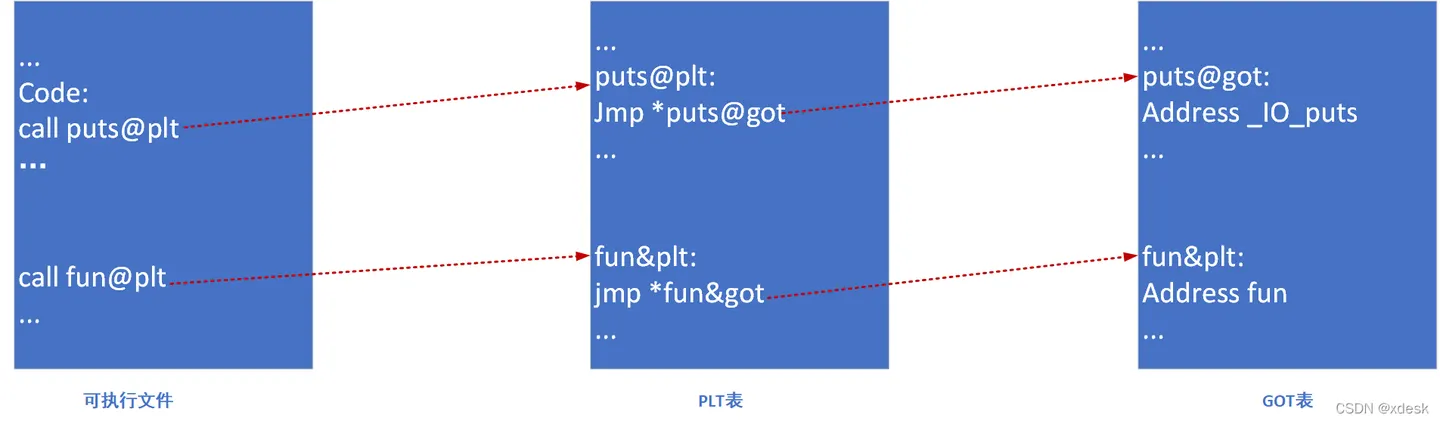
- 区别:本质、执行效率、空间占用、可维护性
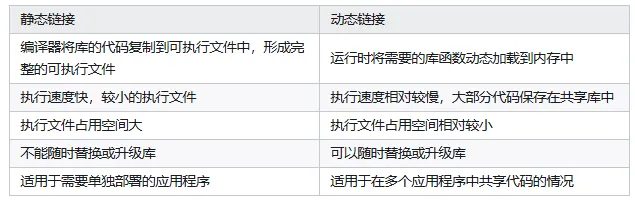
- 静态链接:静态库中的代码和数据是链接时复制到可执行文件中的,而不是运行时加载到进程中的。
-
gcc 链接库时注意顺序问题
- 链接器在考察库文件 (.a) 的时候,不是把库文件看做一个整体,而是将打包在其中的目标文件(.o)作为考察单元。连接时,每个库只扫描一遍,每个库中没用任何符号被使用的 .o 文件会被丢弃。
链接器在工作过程中,维护 3 个集合:需要参与连接的目标文件集合
E、一个未解析符号集合U、一个在E中所有目标文件定义过的所有符号集合D。目标文件按照顺序解析, 如果目标文件没有包含任何一个集合U中的符号就会被丢弃。扫描结束时如果 U 非空就会编译错误。因此需要基于依赖的拓扑序排列 -l(前面库依赖后面库)。如果存在循环依赖,gcc 提供 Xlinker 选项。
-
强制使用静态库编译(可能导致出错,因为有些库只有动态库从而出现 undefined symbol 错误)
- 默认是优先链接动态库,动态库不存在链接静态库
- -static:指定全用静态链接,但可能有些库只有动态链接,会出现问题。
- -Wl,-Bstatic … -Bdynamic:局部开关。-Wl 用于传递链接器参数,-Bstatic 指定接下来优先使用 static 链接,直到遇到 -Bdynamic
144. 关于并发编程#
-
join()和detach()join() 或 detach() 和线程的资源释放问题有关:
- 线程的资源将在调用 t.join() 后且线程执行完成后被回收。
- t.detach() 会将线程 t_thread 与当前线程分离。但其归属权和控制权都将转移给 C++ 运行时库(runtime library,又名运行库),由此保证线程退出时与之关联的资源可以被正确回收。
如果没有调用过 join() 或 detach(),也没有转移 std::thread 对象的所有权,那么它的 joinable() 返回值为 true。直接调用析构会导致整个进程结束。
cpp~thread() { if (joinable()) std::terminate(); } -
线程对象何时是 joinable 的?
- 其是默认构造的。
- 如果其已经被用来使用移动构造或赋值构造创建了另一个 std::thread 对象。
- 其成员函数 join() 或 detach() 已经被调用过。
-
注意点
-
被创建的 std::thread 需要调用 join() 或者 detach()
-
有关联的线程仍然活跃(是 joinable 的)的 std::thread 不能被销毁,否则报错 “terminate called without an active exception”
-
std::thread 参数必须是可调用的或者可以转成右值,传入非常量引用需要 std::ref 套一下
线程是有自己的内存存储空间的,在 std::thread 类的构造中,参数会先按照默认方式复制到线程的存储空间中,然后新创建的线程才能访问它们。这些副本被当做临时变量,以右值的方式传递给新线程上的函数或者可调用对象。即便函数相关的参数按设想应该是引用。
-
145. 怎么设计哈希表,负载因子设置为多少,有什么办法提高哈希表的填充率?#
小红书 搜广推 C++ 一面
设计哈希表需要综合考虑哈希函数、冲突解决机制、扩容策略和内存管理。
哈希函数应具有良好的分布性和计算效率,常见的有 MurmurHash、CityHash 等;冲突解决可采用链地址法(链表存储冲突元素,简单稳定)或开放寻址法(线性探测、二次探测、双哈希,缓存友好但易产生聚集)。
扩容因子(负载因子) 是哈希表中已存储元素数量与哈希表总容量的比值,用于衡量哈希表的填充程度和触发扩容的时机。
一般是达到 0.75 后,直接扩容为原来的 2 倍
负载因子通常设置为 0.75,这是经验证能在时间效率和空间利用率间取得最佳平衡的阈值——超过此值冲突概率急剧上升,低于此值则内存浪费明显。
提高填充率的核心方法包括:优化哈希函数减少冲突,使用二次探测或双哈希降低初级聚集,实现动态扩容(通常翻倍扩容并重哈希),采用布谷鸟哈希通过多个哈希函数和踢出机制提升空间利用率至 95%+,以及实现渐进式 rehash 避免扩容时的服务中断,这些技术能显著提升哈希表在保持高性能的同时的空间利用效率。
146. 哪些设计模式利用了虚函数的特点?#
高德 C++ 一面
设计模式中,模板方法、策略、工厂方法、抽象工厂、观察者、装饰器、访问者、状态、职责链和命令等模式都深度依赖于虚函数实现的运行时多态性:这些模式通过在基类或接口中定义抽象的虚函数,并在各个具体子类中提供不同的实现,使得相同的接口调用能在运行时表现出不同的行为。这种机制使得程序架构能够将稳定的框架逻辑与易变的具体实现解耦,让算法骨架(模板方法)、对象创建(工厂)、行为策略(策略模式)、事件响应(观察者)、功能扩展(装饰器)等核心要素可以在不修改现有代码的前提下灵活扩展和替换,从而实现了面向接口而非实现的编程范式,为软件设计提供了强大的灵活性和可维护性。
147. 多重继承下(C 继承 A 和 B),C 类的对象内存布局是怎样的?#
🔥 虚函数必知前提#
- 一个虚函数表对应一个类(前提有 virtual)
- 一个类可能不止一个虚函数表(多重继承的情况下)
- 派生类和基类都有各自的虚函数表(派生类拷贝基类虚函数表后,重写虚函数则覆盖函数地址,新增虚函数则增加函数地址)
- 多重继承下 C 类有两个虚函数表:第一个 vptr_a 指向的虚函数表包含 A 和 C 的虚函数,第二个 vptr_b 指向的虚函数表包含 B 和 C 的虚函数
多继承场景的内存布局(C 类有 2 张虚函数表,其中 1 张为主表)#
C 对象的内存布局:
+----------------+ <-- C* 指针, A* 指针
| AC的虚表指针 | --> C 虚函数表 1: [ &C::funcA, &A::~A, &C::funcC ]
+----------------+
| A::a_data |
+----------------+
| BC的虚表指针 | --> C 虚函数表 2: [ &thunk_to_C::funcB, &C::~C ]
+----------------+
| B::b_data |
+----------------+
| C::c_data |
+----------------+
A 的虚函数表:
[0] &C::funcA // C重写的funcA
[1] &A::~A // 析构函数
[2] &C::funcC // C自己的虚函数
B 的虚函数表:
[0] &thunk_to_C::funcB // 需要调整this指针的跳转函数
[1] &B::~B // 析构函数为什么要调整 this 指针#
不调整 Base2 的 this 指针时,默认是直接指向第二个虚函数表指针的位置(因为这样 Base2 可以直接在首地址访问到第二个虚表指针,快速调用自己重写的虚函数,但是对象首地址应该是第一个虚函数表指针的位置 —— 整体对象首地址),这会造成所有成员访问都会错位!
让我详细解释为什么非首基类调用需要调整this指针。
1. 根本原因:内存布局导致的指针偏移#
class Base1 {
public:
int b1_data;
virtual void func() { /* 期望this指向Base1开始 */ }
};
class Base2 {
public:
int b2_data;
virtual void func() { /* 期望this指向Base2开始 */ }
};
class Derived : public Base1, public Base2 {
public:
int d_data;
void func() override { /* 需要访问所有数据:b1_data, b2_data, d_data */ }
};2. 具体内存布局分析#
Derived对象内存布局:
+----------------+ <-- Derived* = 0x1000 (完整对象起始地址)
| Base1虚表指针 |
+----------------+
| Base1::b1_data | // 偏移量 +0
+----------------+
| Base2虚表指针 | <-- Base2* = 0x1008 (Base2子对象起始地址)
+----------------+
| Base2::b2_data | // 偏移量 +8 (相对于Base2*)
+----------------+
| Derived::d_data| // 偏移量 +16 (相对于Base2*)
+----------------+3. 问题所在:this 指针不匹配#
通过不同指针调用时
Derived derived;
Base1* b1_ptr = &derived; // b1_ptr = 0x1000
Base2* b2_ptr = &derived; // b2_ptr = 0x1008 (偏移了8字节!)
b1_ptr->func(); // 传入的this = 0x1000 ✓
b2_ptr->func(); // 传入的this = 0x1008 ✗ 问题!Derived::func() 需要访问的数据:
void Derived::func() {
// 这些访问都基于完整的Derived对象地址
cout << b1_data; // 在偏移量 +8 处
cout << b2_data; // 在偏移量 +16 处
cout << d_data; // 在偏移量 +20 处
}4. 如果不调整 this 指针,所有成员访问都会错位!#
// 假设不调整this指针,直接调用:
b2_ptr->func(); // this = 0x1008
// 在Derived::func()中:
cout << b1_data; // 实际访问 0x1008 + 8 = 0x1010 (错误!应该是0x1008)
cout << b2_data; // 实际访问 0x1008 + 16 = 0x1018 (错误!应该是0x1010)
cout << d_data; // 实际访问 0x1008 + 20 = 0x101C (错误!应该是0x1014)148. 当 C 类继承 A 类时,A 和 C 的构造函数与对象的虚函数表指针之间存在什么样的交互关系?#
我们来详细拆解 C 类继承 A 类时,构造函数和虚函数表指针的关系。简单来说,构造函数负责为本类及其基类“初始化”虚函数表指针,使其指向正确的虚表。
下面是详细的步骤和关系:
1. 对象的内存布局(继承时)#
假设我们有如下代码:
class A {
public:
virtual void vfunc1() { }
virtual void vfunc2() { }
int a_data;
};
class C : public A {
public:
virtual void vfunc1() override { } // 重写
virtual void vfunc3() { } // 新的虚函数
int c_data;
};一个 C 类对象在内存中的典型布局如下:
|------------------------|
| A::vptr (虚函数表指针) | <- 对象开头,通常只有一个vptr
|------------------------|
| A::a_data |
|------------------------|
| C::c_data |
|------------------------|关键点:在单继承情况下,派生类对象通常只包含一个虚函数表指针,这个指针位于对象的起始位置,由基类 A 引入。
2. 构造函数的执行过程与 vptr 的初始化#
当你创建一个 C 对象时(C* obj = new C();),构造函数的调用和 vptr 的设置流程如下:
步骤 1: 分配内存#
- 操作系统为
C类对象分配足够的内存(包含 A 部分 + C 部分)。
步骤 2: 进入 C 的构造函数#
- 在进入
C的构造函数体 之前,编译器会插入代码,将对象的 vptr 设置为指向 C 类的虚函数表。 - 然后调用基类
A的构造函数。
步骤 3: 进入 A 的构造函数#
- 在进入
A的构造函数体 之前,编译器会插入代码,将对象的 vptr 设置为指向 A 类的虚函数表。 - 执行
A的构造函数体。
步骤 4: 返回 C 的构造函数#
A的构造函数执行完毕后,返回到C的构造函数。- 此时,编译器会再次将对象的 vptr 重新设置为指向 C 类的虚函数表。
- 最后执行
C的构造函数体。
3. 虚函数表指针的变化流程#
这个过程中,vptr 的变化可以用以下伪代码表示:
// 创建 C 对象时的幕后代码
C* obj = operator new(sizeof(C)); // 1. 分配内存
// 2. 开始构造 C
obj->vptr = &C::vtable; // 先指向C的虚表(临时)
A::A(obj); // 3. 调用基类构造函数
// 在 A::A 内部:
obj->vptr = &A::vtable; // 指向A的虚表
// ... 执行A的构造函数体 ...
// 从 A::A 返回后
obj->vptr = &C::vtable; // 重新指向C的虚表(最终)
// ... 执行C的构造函数体 ...4. 重要结论和影响#
为什么要在构造函数中这样设置 vptr?#
- 类型安全:在
A的构造函数中调用虚函数时,应该调用A版本的实现,而不是可能依赖C中未初始化数据的C版本重写。 - 构造顺序:对象是从基类到派生类依次构造的,在构造
A时,C还没有构造完成。
虚函数表的内容#
- A 的虚表:
{ A::vfunc1, A::vfunc2 } - C 的虚表:
{ C::vfunc1, A::vfunc2, C::vfunc3 }(注意vfunc1被替换了)
在构造函数中调用虚函数#
class A {
public:
A() {
vfunc1(); // 这里调用的是 A::vfunc1,不是 C::vfunc1!
}
virtual void vfunc1() { cout << "A's vfunc1\n"; }
};
class C : public A {
public:
virtual void vfunc1() override { cout << "C's vfunc1\n"; }
};
// 执行:
C obj; // 输出 "A's vfunc1",而不是 "C's vfunc1"总结#
构造函数和虚函数表指针的关系:
- 构造顺序决定 vptr 设置:在进入每个类的构造函数体之前,vptr 被设置为指向当前类的虚表。
- vptr 会多次变化:在构造过程中,vptr 会随着构造流程在基类和派生类的虚表之间切换。
- 最终指向派生类:构造完成后,vptr 最终指向最派生类(本例中的
C)的虚表。 - 保证构造安全:这种机制确保了在构造函数中调用虚函数时,不会调用到尚未构造完成的派生类重写版本。
这就是 C++ 对象构造与多态机制协同工作的精妙之处。
149. 在基类构造函数中调用虚函数,此时是调用基类还是派生类?那如果在派生类构造函数中调用虚函数呢?(上一个问题有提及)#
类型安全:在
A的构造函数中调用虚函数时,应该调用A版本的实现,而不是可能依赖C中未初始化数据的C版本重写。构造顺序:对象是从基类到派生类依次构造的,在构造
A时,C还没有构造完成。
基类构造函数中调用虚函数:基类(此时派生类还没有构造好,因为构造顺序是先父类再派生类)
派生类构造函数中调用虚函数:
- 调用的是派生类重写的虚函数:派生类
- 调用的是派生类未重写的虚函数:基类(因为未重写,虚函数表未覆盖原有的虚函数地址,仍然指向基类的虚函数地址)
150. 你知道可重入锁吗?如何实现可重入锁?具体的字段和函数如何设计?#
“重入”指的是同一个线程,在已经持有某个锁的前提下,可以再次成功获取该锁,而不会被自己阻塞。
可重入锁允许同一个线程多次获取锁而不被自己阻塞,但这不影响锁的基本互斥特性——其他线程仍然必须等待当前线程完全释放锁后才能获取。
#include <mutex>
#include <thread>
#include <condition_variable>
#include <atomic>
#include <stdexcept>
class ReentrantLock {
private:
std::thread::id owner_; // 当前持有锁的线程ID
std::atomic<int> count_; // 重入计数
std::mutex mutex_; // 保护内部状态
std::condition_variable cond_; // 等待条件变量
public:
ReentrantLock() : count_(0) {}
// 获取锁
void lock() {
std::unique_lock<std::mutex> lock(mutex_);
std::thread::id this_thread = std::this_thread::get_id();
// 如果锁被其他线程持有,等待
while (count_ > 0 && owner_ != this_thread) {
cond_.wait(lock);
}
// 现在可以获取锁
owner_ = this_thread;
count_++;
}
// 释放锁
void unlock() {
std::unique_lock<std::mutex> lock(mutex_);
std::thread::id this_thread = std::this_thread::get_id();
if (count_ <= 0 || owner_ != this_thread) {
throw std::logic_error("Attempt to unlock a lock not owned by current thread");
}
count_--;
if (count_ == 0) {
owner_ = std::thread::id(); // 清空所有者
cond_.notify_one(); // 唤醒一个等待线程
}
}
// 尝试获取锁
bool try_lock() {
std::unique_lock<std::mutex> lock(mutex_);
std::thread::id this_thread = std::this_thread::get_id();
if (count_ == 0 || owner_ == this_thread) {
owner_ = this_thread;
count_++;
return true;
}
return false;
}
// 获取重入次数(主要用于调试)
int get_count() const {
return count_.load();
}
// 检查当前线程是否持有锁
bool is_owned_by_current_thread() const {
return count_ > 0 && owner_ == std::this_thread::get_id();
}
};151. 常见的内存安全问题有哪些?#
内存安全问题主要源于程序对计算机内存(如堆、栈)的错误访问或管理,通常会导致程序崩溃、数据损坏或严重的安全漏洞(如被攻击者利用以执行任意代码)。
以下是常见的内存安全问题分类和详解:
1. 缓冲区溢出#
这是最经典、最危险的内存安全问题之一。当程序向一个分配好大小的缓冲区(如数组)写入数据时,写入的数据量超过了缓冲区的容量,导致覆盖了相邻的内存区域。
- 栈缓冲区溢出:溢出发生在栈上,可能会覆盖函数的返回地址。攻击者可以精心构造数据,将返回地址指向其注入的恶意代码,从而控制程序流程。
- 堆缓冲区溢出:溢出发生在堆上,可能会破坏堆中相邻的数据结构(如堆块头、其他对象等),导致程序行为异常或为攻击者提供利用机会。
示例:
void copy_string(char *input) {
char buffer[16]; // 栈上分配一个16字节的缓冲区
strcpy(buffer, input); // 如果input长度超过15字节(+1个结束符),就会发生溢出!
}2. 解引用空指针或野指针#
- 空指针解引用:试图访问内存地址
0x0(通常表示空指针)的内容。这会导致程序立即崩溃(段错误)。 - 野指针解引用:指针指向的内存已被释放或未初始化,但其值未被置空。此时解引用它,行为是未定义的——可能读到垃圾数据、写入到已不属于它的内存,导致难以调试的错误。
示例:
int *ptr = NULL;
*ptr = 5; // 解引用空指针,崩溃!
int *wild_ptr = (int*)malloc(sizeof(int));
free(wild_ptr); // 内存已释放...
*wild_ptr = 10; // ...但指针仍指向那里,现在是一个野指针,解引用它行为未定义!3. 使用后释放#
这是野指针问题的一种常见形式。内存被释放后,指向它的指针仍然存在。如果该内存被重新分配用于其他用途,那么通过野指针修改它就会破坏新数据,造成信息泄露或控制流劫持。
示例:
char *ptr = (char*)malloc(100);
free(ptr); // 内存释放,ptr现在是野指针
// ... 一段时间后,系统可能将这块内存分配给另一个对象
strcpy(ptr, "Hello"); // 破坏了新对象的数据!4. 双重释放#
对同一块动态分配的内存进行多次 free() 操作。这会破坏内存管理器的数据结构(如glibc的堆元数据),可能导致程序崩溃或让攻击者插入恶意代码。
示例:
int *ptr = (int*)malloc(sizeof(int));
free(ptr);
free(ptr); // 错误:双重释放!5. 内存泄漏#
程序动态分配了内存(如使用 malloc, new),但在使用完毕后忘记释放。不断的内存泄漏会逐渐消耗掉系统的所有可用内存,最终导致程序或系统变慢甚至崩溃。虽然它不直接让攻击者利用,但会降低系统稳定性。
示例:
void leak_memory() {
while(1) {
int *ptr = (int*)malloc(1024); // 每次循环都分配1KB,但从不释放
// ... 使用ptr ...
// 忘记 free(ptr);
}
}6. 未初始化的内存读取#
变量(尤其是栈或堆上的变量)在分配后没有赋初值就直接读取。此时读到的内容是之前留在内存中的随机值(垃圾值),会导致程序逻辑错误和不稳定。
示例:
int value; // 未初始化
printf("%d", value); // 可能输出任意值,行为不确定7. 整数溢出与回绕#
在进行算术运算时,结果超出了该整数类型所能表示的范围。这可能导致缓冲区大小的计算错误,进而引发缓冲区溢出。
- 无符号整数回绕:
UINT_MAX + 1会变成0。 - 有符号整数溢出:行为在C/C++标准中是未定义的,但常见实现是回绕。
示例:
uint32_t buffer_size = count * sizeof(int); // 如果count很大,乘法可能回绕成一个很小的数
int *buffer = (int*)malloc(buffer_size); // 现在分配的空间远小于所需
// 后续向buffer写入数据会导致堆缓冲区溢出8. 迭代器失效#
在C++等语言中,当修改容器(如 vector, deque)时(例如插入、删除元素),指向容器元素的迭代器可能会变得无效。继续使用这些失效的迭代器会导致未定义行为。
示例:
std::vector<int> vec = {1, 2, 3};
auto it = vec.begin();
vec.push_back(4); // 可能导致vector重新分配内存,使所有迭代器失效
*it = 5; // 错误!使用已失效的迭代器152. vector 扩容采用深拷贝还是浅拷贝?#
深拷贝,避免资源 double free。
std::vector 在扩容时(例如,当 push_back 新元素导致 size() > capacity() 时),会执行以下步骤:
- 分配新内存:在自由存储区(堆)上分配一块新的、更大的内存空间。
- 拷贝(或移动)元素:将旧内存空间中的所有元素逐个转移到新的内存空间中。
- 释放旧内存:销毁旧内存空间中的对象并释放内存。
关键在于第2步:“逐个转移”。
- 如果 vector 中存储的是 内置类型 或 可平凡拷贝的类型,这个“拷贝”在行为上和 “逐位浅拷贝” 效果相同,但因为调用的是对象的拷贝构造函数或移动构造函数,所以从语言机制上,我们依然称之为“拷贝”(一种高效的、按值复制的深拷贝)。
- 如果 vector 中存储的是 自定义类对象,那么这个过程会明确地调用每个对象的拷贝构造函数 或 移动构造函数。此时 vector 分配新内存,然后简单地将旧内存中的
MyObject指针(即data成员)复制到新内存中。现在,两个MyObject对象(旧内存和新内存中的)的data成员指向了同一块堆内存。vector 紧接着会释放旧内存。在释放过程中,它会调用旧内存中每个MyObject对象的析构函数,导致delete data;。结果就是,新内存中的MyObject对象的data指针变成了一个悬空指针。当你后续尝试通过它访问数据时,行为未定义(通常是程序崩溃)。更糟糕的是,当这个 vector 最终被销毁时,它会再次delete同一块内存,导致双重释放。
如果你的对象支持移动语义,vector 在扩容时会优先使用移动构造函数,这比深拷贝更高效,因为它“窃取”旧对象的资源,而不是复制它们。对于这样的类,vector 扩容时会调用“移动构造”,只是转移了指针所有权,没有进行昂贵的内存分配和值复制。
class MyObject {
public:
int* data;
MyObject(int value) {
data = new int(value);
}
// 深拷贝拷贝构造函数
MyObject(const MyObject& other) {
data = new int(*(other.data)); // 分配新内存,并复制值
std::cout << "拷贝构造被调用" << std::endl;
}
// 深拷贝拷贝赋值运算符 (通常还需要实现)
MyObject& operator=(const MyObject& other) {
if (this != &other) {
delete data; // 释放原有资源
data = new int(*(other.data));
}
std::cout << "拷贝赋值被调用" << std::endl;
return *this;
}
// 移动构造函数 (noexcept 很重要,便于vector优化)
MyObject(MyObject&& other) noexcept : data(other.data) {
other.data = nullptr; // 使旧对象处于有效但可析构的状态
std::cout << "移动构造被调用" << std::endl;
}
// ... 相应的移动赋值运算符 ...
~MyObject() {
delete data;
}
};153. 析构函数什么情况下才需要设置为虚析构?什么时候可以不用?#
需要虚析构函数的情况:
- ✅ 类被设计为基类,且可能通过基类指针删除派生类对象
- ✅ 类包含虚函数(有虚函数通常意味着多态使用)
- ✅ 类有派生类且派生类需要资源清理(避免资源泄漏)
不需要虚析构函数的情况:
- ❌ 类不会被继承(如工具类、值类型)
- ❌ 类标记为
final - ❌ 不会通过基类指针删除对象
- ❌ 类没有虚函数且不打算多态使用
经验法则:如果一个类有任何一个虚函数,那么它的析构函数也应该是虚的。
154. 钻石继承(虚继承)的内存布局#
class Base {
public:
int base_data = 0xBB;
virtual void base_func() { cout << "Base::base_func" << endl; }
};
class Mid1 : virtual public Base { // 虚继承
public:
int mid1_data = 0xM1;
virtual void mid1_func() { cout << "Mid1::mid1_func" << endl; }
};
class Mid2 : virtual public Base { // 虚继承
public:
int mid2_data = 0xM2;
virtual void mid2_func() { cout << "Mid2::mid2_func" << endl; }
};
class Bottom : public Mid1, public Mid2 {
public:
int bottom_data = 0xBT;
void base_func() override { cout << "Bottom::base_func" << endl; }
};Bottom对象内存布局:
+----------------+ <-- Bottom*, Mid1*
| Mid1虚表指针 | --> [ &Mid1::mid1_func, ... + 虚基类信息 ]
+----------------+
| mid1_data |
+----------------+
| Mid2虚表指针 | --> [ &Mid2::mid2_func, ... + 虚基类信息 ]
+----------------+
| mid2_data |
+----------------+
| bottom_data |
+----------------+
| Base虚表指针 | --> [ &Bottom::base_func, ... ]
+----------------+
| base_data |
+----------------+
虚表数量:3张
1. Mid1部分的虚表
2. Mid2部分的虚表
3. Base部分的虚表(共享)155. delete 和 delete[] 有什么区别?#
delete vs delete[]
delete p:销毁一个对象,调用其析构,随后调用对应的operator delete释放内存。delete[] p:销毁数组中的每个元素(通常逆序调用析构),再调用operator delete[]。- 成对使用:
new→delete,new[]→delete[];混用是未定义行为(无法知道元素个数)。
delete[] 的释放过程
- 运行时需要知道元素个数以逐个析构——常见实现会在分配块前留“数组 cookie”记录个数(标准不强制,但做法通行)。
- 调用每个元素的析构(通常逆序)。
- 调
operator delete[]释放整块内存。
156. delete[] 怎么知道删除几个元素?额外记录元素个数不会影响索引访问吗?#
不会出问题的。数组 “cookie” 放在内存块起始处,返回给你的指针仍然指向第 0 个元素,所以用下标访问完全正常。更具体点:
p = new T[n];的典型内存布局大致是[ cookie | 可能的对齐填充 | T(0) | T(1) | ... | T(n-1) ]这里p等于&T(0),而不是指向 cookie。你做p[i]、*(p+i)都是在元素区间里算术,和 cookie 没有任何交集。- cookie 仅供
delete[] p使用:实现会在删除时把p向前回退到隐藏头(或使用“带大小”的 delete 接口),取出元素个数,按需要逐个析构,再释放整块内存。正常访问阶段你看不到它。 - 对齐不会被破坏:分配器会多分配一些字节,确保把
p调整到满足alignof(T)(对于超对齐类型还会用到对齐版的operator new[]),因此p的对齐是正确的。 - 一些实现/场景甚至不需要 cookie(例如使用“带大小”的
operator delete[](void*, std::size_t)或 trivially destructible 的类型),但这对你的索引访问没有影响。
真正会出问题的情况是未定义行为:
- 用
new T[n]却配delete p,或new T配delete[] p——删除路径不匹配,运行时找不到正确的元素个数,轻则泄漏,重则崩溃。 - 对
p做越界/负向指针运算(例如试图访问*(p-1)想“看到 cookie”)——这是未定义行为。 - 自己实现/重载
operator new[]/delete[]却没有正确处理对齐与大小信息。
总结:正常写法下,索引访问只落在元素区域内,和 cookie 完全隔离;记得 new/delete、new[]/delete[] 要成对使用就行。
157. 什么是右值引用?必须用 move 才能转为右值吗吗?#
不必须。std::move 只是把一个左值显式地“转成将亡值(xvalue)” 的工具(本质是 static_cast<T&&> 的封装),以便命中移动重载。得到右值/触发移动还有很多途径:
什么时候不必用 move 也会移动#
-
临时对象/返回值(prvalue)
cppstd::string s = std::string("hi"); // 直接构造/拷贝省略;不需要 move std::string f() { return std::string("hi"); } // 返回值是右值 auto t = f(); // 若未省略拷贝,则优先用移动构造C++17 起很多场景保证拷贝消除,连“移动”都省了。
-
return 局部对象(隐式移动)
cppstd::string g() { std::string x = "hi"; return x; // x 是本地对象、同类型返回——隐式当成右值(或直接省略) } -
“值传参再返回”/sink 参数
cppvoid set_name(std::string s) { name_ = std::move(s); } // 调用处传实参时会移动 set_name(std::move(tmp)); // 显式 set_name(f()); // f() 返回值本就是右值 -
容器的
emplace_\*/ 工厂函数
cppv.emplace_back(100, 'x'); // 直接就地构造,没有 move 的必要 auto p = std::make_unique<Foo>(); // 返回右值 -
迭代器适配器
cppstd::vector<std::string> a, b; b.insert(b.end(), std::make_move_iterator(a.begin()), std::make_move_iterator(a.end())); // 把范围“视作右值”
确实需要 move 的典型场景#
-
把一个“有名字的对象”(左值)当右值用
cppstd::string s = "hi"; v.push_back(std::move(s)); // 不写 move 就会拷贝 -
类内转移所有权
cppholder(ptr p) : p_(std::move(p)) {}
模板里应当用 forward(而非一律 move)#
-
完美转发:只在参数本来是右值时才转成右值
cpptemplate<class T, class... Args> T make(Args&&... args) { return T(std::forward<Args>(args)...); }
常见误区 & 边界#
-
std::move不会“移动”,它只是一个无开销的强制类型转换;是否真的走移动构造/赋值,要看目标类型是否提供相应重载。 -
对
const对象用std::move往往没有意义:得到的是const T&&,大多数类型的移动构造签名是T(T&&)(非常量),因此会退化为拷贝。
cppconst std::string s = "hi"; std::string t = std::move(s); // 通常走拷贝,而不是移动 -
移动后对象仍然有效但处于“资源被转移”的状态,只保证可析构/可赋新值,不保证内容。
结论#
- 右值不等于必须
std::move。临时对象、返回值、隐式移动、emplace/工厂函数、move_iterator等都能产生/利用右值。 - 当且仅当你手里是一个左值且你确实要把它的资源转移时,才需要写
std::move;模板里用std::forward保留原本的值类别。
158. 内存上的问题:一种代码有好几种写法,他可能实现的功能都差不多,但是性能可能会有很大的差异,关于这点具体有什么要注意的地方,或者说你有什么要分享给我的?#
1) 数据布局(决定缓存命中)#
高性能往往从“内存长相”开始:把 AoS(struct{...} 的数组)改成 SoA(每个字段单独一块连续数组),让 CPU 一次线性扫到成批需要的字段,利于向量化与硬件预取;把“总被一起用”的字段挪到相邻位置,把大而冷的成员(如 std::string/std::vector)拆出去,形成“热-冷分离”,减少不必要的 cache line 装载;按自然对齐排布字段,避免错误使用 #pragma pack 或位域导致跨行和非对齐访问;利用小对象优化(SBO)减少堆分配,但要盯住对象尺寸别超过 SBO 阈值;在构造路径用 emplace/拷贝省略、在读路径用 string_view/span 等无拷贝视图(同时记住生命周期边界),这些都能显著降低 L1/L2 Miss 和内存带宽压力。
2) 分配与生命周期(降低 malloc/free 压力)#
频繁的小分配是吞吐杀手:容器预留容量(vector::reserve/string::reserve)能一次到位,避免指数扩容的反复搬运;对“批量创建—一次性丢弃”的工作负载(解析、编译、RPC)用 Arena/Pool,把释放从“逐个 free”变成“批量 reset”;用 PMR(polymorphic_allocator)或自定义分配器,让一批相关容器共享内存资源,减少碎片和锁争用;同型小对象密集创建销毁用 slab/pool 固定大小块加速;跨层传递数据优先“指针/视图”而非拷贝(I/O 路径上用 readv/writev、sendfile、splice、mmap)实现零拷贝;写入容器使用 emplace 或 push_back(std::move(x)),把昂贵的深拷贝变为常数级的指针交换。
3) Cache/CPU 友好(L1/L2/TLB/分支)#
让访问“像读磁带”而不是“打地鼠”:尽量把热点算法改成顺序扫描,超大数组分块(tiling)匹配 L1/L2 容量;避免链表/指针森林等随机追指,用扁平数组+索引(压平)减少跳转;可预测的遍历可加 __builtin_prefetch 让硬件提前搬运;大数据吞吐可选 2MB hugepage 降 TLB Miss;分支方面把常走路径写成“卫语句”提早返回,结合 likely/unlikely 提示,减少 BTB 失误;能内联就别虚函数,必要时去虚化(CRTP/静态多态);数据已 SoA 时再开启 -O3 -march=native,很多循环可自动向量化,或用 intrinsics 明确使用 SIMD 指令,I-cache 命中与指令级并行都能上一个台阶。
4) 并发与假共享(false sharing)#
多线程下的“无形开销”常来自 cache line 抖动:对不同线程各自频繁写的计数/状态,结构体上用 alignas(std::hardware_destructive_interference_size)(常见 64B)或手动填充把它们“隔一行”;队列/环形缓冲尽量批处理 push/pop 降低同步频率,避免在共享结构上长时间自旋;跨 NUMA 机器要做“first-touch”初始化并绑定线程亲和,尽量让线程就近访问本地内存;原子操作别一律用 seq_cst,看依赖选择 release/acquire/relaxed,弱化内存屏障带来的流水线冲刷;高争用路径可以用 MPSC/SPSC 队列、分片计数(per-thread 计数+汇总)等结构,既稳又快。
5) I/O 与系统层(与页缓存配合)#
顺序大读可用 mmap 配合 madvise(MADV_SEQUENTIAL) 让内核预读更积极,随机大写用 pwrite 加 posix_fadvise(DONTNEED) 避免脏页把缓存顶爆;网络/磁盘路径善用零拷贝原语(sendfile、splice、readv/writev)减少用户态-内核态往返与内存拷贝;对延迟敏感的落盘要意识到 fsync/barrier 极贵,采用写前日志+组提交(group commit)把多次同步合并成一次;离线/批处理任务可显式调大 readahead,在线请求则要避免“把冷数据抖进页缓存”影响热点;若 I/O 成为瓶颈,优先做批量与合并(coalescing),其次再考虑线程/异步模型切换。
6) 语言/库层面的易错点(以 C++ 为例)#
容器与抽象的选择影响巨大:中小规模、读多改少的映射用 flat_map(排序向量 + 二分)常优于 unordered_map/map,因为 cache 友好且无哈希/指针追逐;shared_ptr 的原子引用计数在高频路径很贵,能用 unique_ptr 别上共享,或采用侵入式计数/分离控制块减少原子写;循环中逐个 erase 容器元素会导致 O(n²) 搬运,改为“打标签→一次性 stable_partition/erase_if”;std::function 捕获大对象导致隐式堆分配,性能关键路径用模板/可调用对象直传或小型闭包;异常不应走热路径(抛掷与栈展开昂贵且破坏预测),把可预期分支改成状态返回或 expected 类型更稳。
7) 度量方法(别猜,用数据说话)#
优化从测量开始:先用 perf record -g + 火焰图找前两大热点(80/20 原则),再用 perf stat -e cycles,instructions,LLC-load-misses,branch-misses 看指令/CPI/缓存/分支画像;需要定位缓存行为时跑 valgrind --tool=cachegrind 得到每函数/每行的 I/D-cache 失效率;内存分配与泄漏用 heaptrack 或 Valgrind Massif 观察分配次数与峰值;遇到偶发长尾,结合 perf top 抽样、反复 gdb -p 抓多份线程栈,或上 eBPF/系统跟踪(lttng、bcc)给出系统调用与调度视角;所有实验都要可复现(固定数据/随机种子/并发度)并记录参数与版本,用基线对比量化收益。
8) 一个“改法对比”的实操范式#
将“慢但易写”的实现按层次替换:①把链表/树改为 vector 扁平结构并 reserve;②把结构体数组拆成 SoA,循环里只取必要字段;③移除虚派发,改模板/策略类让编译器内联;④把元素处理改成块内循环(block size≈几 KB)以提升局部性;⑤若算法是简单算子(加减比较),尝试向量化(自动或 intrinsics)并适当 prefetch 下一块;⑥若还不够,把内存管理切到 arena/池、把 I/O 改为批量/零拷贝。每一步做小型 A/B,对照 perf stat 与火焰图,定位收益来自哪一层,避免“盲目堆技巧”。
9) 优先级与工作流程(落地打法)#
别想一次把所有细节做满:先跑基准拿火焰图,只盯 Top2 热点;先改数据布局(SoA/压平/reserve),通常直接带来 2×—10×;若热点在并发/锁上,优先拆分成 per-thread 数据加批处理;若热点在 I/O,同步落盘合并到后台队列并组提交;每改一次都跑同一基准核实收益与正确性(单测+长时间 stress),收益达标就收工并写下原因/结论,避免“继续优化反而回退”;最后把关键开关做成可配置(SBO 阈值、块大小、是否 hugepage 等),便于在不同机器与负载上快速调参。
159. 还有哪些对内存强相关的且影响性能的点?#
高性能分配器的选择与争用#
系统默认的 malloc(如 glibc malloc)在多线程下容易产生锁争用与碎片。服务端场景优先试 jemalloc 或 tcmalloc:它们用线程局部/分级缓存降低加锁和跨核流量,明显减少分配/释放抖动。配合对象池/arena,把“高频小对象”从通用分配器挪走,进一步降低碎片与 TLB 压力。排查方法:统计分配次数与尺寸分布,观察 CPU 在 malloc/free 上的火焰图占比。
缺页开销(minor/major fault)与预热#
初次触碰页会触发 minor fault,冷热数据回收后再触碰可能变 major fault(磁盘 I/O),两者都能拉高尾延迟。批量初始化(first-touch)把数据预热到内存;对大块内存启动阶段做“线性预读”或后台预热,把故障集中到启动期而不是请求关键路径。
THP/大页与 TLB 命中#
透明大页(Transparent Huge Pages)或显式 2MB/1GB 大页能显著降低 TLB miss,适合大数组/长循环。但 THP 的自动折叠在写放大场景可能抖;对延迟敏感业务考虑手动 madvise(MADV_HUGEPAGE) 或显式大页分配,并监控 THP 命中率与折叠开销。
NUMA 本地性与跨节点访问#
跨 NUMA 读写等同“远程内存”,延迟/带宽大幅劣化。采用“线程绑核 + first-touch 初始化”,让每个工作线程初始化并处理自己的数据分区;共享结构按节点分片,避免频繁跨节点写。必要时用 numactl/mbind 固定内存到本地节点,监控远程访问比例。
写分配(write-allocate)与非临时写#
普通写 miss 会先把整行读入(write-allocate),对“仅写一次”的大数组是浪费。能预测是“流式一次写”的路径可用非临时存储(如 _mm_stream* 或 std::hardware_constructive_interference_size 配合布局优化),减少读放大;相反,对会被很快读到的数据保留默认策略更好。
预取策略(硬件+软件)#
硬件预取器偏好线性/规律访问。跨 stride 大、间隔不稳定、间接寻址时就会失效。把循环改成规则访问(SoA/压平/分块),在稳定模式下用 __builtin_prefetch(addr, rw, locality) 提前装入下一块。别到处乱加预取:只在高 cache miss 的热点里加,且要基准验证。
拷贝路径与 memcpy/memset 微优化#
反复小拷贝(几十到几百字节)会吃掉大量周期。把“拷贝-处理-丢弃”的流水改成就地处理或视图(string_view/span),把多次小拷贝合并为一次大拷贝;初始化大对象尽量延迟到真正需要时,避免“无意义 memset”。编译器通常会内联小 memcpy,但跨 cache line、未对齐时收益骤降,关注结构体对齐与大小。
COW(写时复制)与 fork 的隐形成本#
使用 COW 的 fork+exec 模式在父进程频繁写(尤其是大堆)时会触发大量页级写时复制,造成 TLB 抖动与页故障。上线前把大对象移动到子进程初始化阶段,或用 posix_spawn/vfork 降低 COW 写放大;把“写多”的共享页分离到单独映射,避免 fork 后的写爆炸。
页回收策略与 swappiness/overcommit#
内核回收策略不合适,会让热点页被回收、触发频繁 major fault。对在线服务,降低 swappiness、避免与大批量离线作业争内存;限制 overcommit 或为大分配使用 mmap(MAP_NORESERVE) 的权衡清晰可控。监控 pgfault/pgmajfault、kswapd CPU 占比来发现问题。
缓存一致性与跨核写放大#
多核共享数据频繁写会触发 MESI/CHI 的行失效风暴。把“写多”的计数/队列分片为 per-thread/per-core,再做周期性汇总;写少读多的数据用 RCU/复制-更新(copy-on-write)模式,把写入改成构建新副本后原子切换,避免不断对共享行做写入。
对象大小与 cache line 对齐#
让热点对象恰好“装进一行”能把命中率拉满;超过一行就会带来多次装载。对热结构体做字段重排/拆分,让“常用字段”落在前 64B 内;需要并发写隔离的成员,用 alignas(64) 单独放一行避免假共享。
容器增长策略与重新散列#
unordered_map 重hash 与 vector 扩容搬运都可能成为尖刺。对“已知规模”的工作负载在构造时给足 reserve(N)/rehash(N);对长寿命容器采用几何增长的默认策略通常更优,但对短生命周期/可预估尺寸的容器,改为一次性预留最省。
页着色/冷热分离与指令缓存#
除了数据缓存,I-cache 也会成为瓶颈。把“热循环”与“慢路径/错误处理”分离到不同函数,减少 I-cache 抖动;数据侧做冷热分离,把日志/元信息等冷字段挪出热点结构。大代码基下,开启 LTO/PGO(基于配置文件优化)让编译器按真实热点布局代码和数据。
内存屏障与原子序语义的成本#
seq_cst 在多核上会导致全局序列化,性能代价极高。按需选择 acquire/release/relaxed,用更弱的序保证实现正确性;对复合操作用“单生产者/单消费者”结构避免重栅栏;跨核通信用一次性发布-订阅(std::atomic<T*> 指针发布 + 不变量)替代频繁的强序列化。
压缩/解压与解引用延迟的权衡#
在“内存带宽”受限的场景,用轻量压缩(如 LZ4、Zstd 低等级)把冷数据压缩后驻留内存,减少带宽与 cache 占用;热路径先解压再批量处理,往往比直接扫未压缩冷数据更快。关键是分层:热数据常驻、温数据轻压缩、冷数据更高压缩。
监控与门槛值(阈值要暴露为配置)#
把关键内存参数做成可调:分配器种类、arena/池块大小、对象池上限、容器 reserve 值、块处理大小(tile size)、是否启用 THP、是否对齐到 cache line。不同机器与负载特征差异巨大,参数可调 + 基准脚本比硬编码更能长久保证性能。
160. 你了解过哪些锁(或同步机制)?这些锁的应用场景分别是哪些?#
🔥互斥锁(mutex)/ 递归锁 / 带超时的 mutex#
最常用的排它同步;临界区较长、需要睡眠等待时首选阻塞型 mutex。递归锁仅在“同线程可重入”老代码里兜底,能不用尽量不用;带超时用在避免死等(比如调用外部组件)或做降级/回退策略。
自旋锁(spinlock)/ ticket spinlock#
临界区极短、线程之间切换成本高或在内核/中断上下文中使用;适合“锁住就几条指令”的场景。若临界区可能阻塞或调度,禁止使用;在多核竞争高时用 ticket/队列式自旋锁减少饥饿。
读写锁(rwlock、shared_mutex)#
读多写少;读者共享、写者独占。写者饥饿要注意(选择公平策略或写优先);若读临界区很短、竞争高,rwlock 可能比 mutex 还慢,此时更适合 RCU/版本化读。
条件变量(condvar)/ 事件(event/futex)#
等待“状态变化”的典型工具:生产者-消费者、工作队列、状态机推进等。要配合外层 mutex;避免“丢信号”靠“while + 条件检查”。Linux 用户态可用 futex 走快速路径。
信号量(semaphore、counting/binary)#
计数控制并发度(连接池、限流“令牌桶”),或跨进程同步(POSIX sem)。和条件变量相比,信号量更像“资源票据”,支持先 post 后 wait。
原子操作(atomic)与内存序(relaxed/acquire/release/seq_cst)#
构建轻量同步或无锁结构的基石:计数器、标志位、一次性发布。选择恰当的内存序能显著降低屏障成本:大多场景 release/acquire 足够,seq_cst 少用。
RCU(Read-Copy-Update)/ Epoch 回收 / Hazard Pointers#
读密集写稀少:读路径无锁、写时复制并原子切换指针;回收由 epoch/hazard 保障安全。典型用于只追加或少量更新的配置、路由表、元数据快照。
Seqlock(序列锁)/ 版本化读#
读方乐观读取两次版本号一致即成功,写方独占更新并递增版本。适合写少且读可重试的结构(时间戳、统计信息);缺点是读可能反复重试。
屏障(barrier)/ 栅栏#
阶段性并行任务的“对齐点”,常见在并行算法的阶段切换;要避免过度细分导致闲等。
锁分片 / 分区锁(sharding / striping)#
把一个大热点拆成多把锁(或 per-core/per-thread 数据),大幅降低竞争:哈希桶、分片计数器、分段 LRU。
文件锁 / 进程间锁(flock/fcntl、named semaphore、共享内存 + futex)#
跨进程协调:单实例守护、批处理互斥、文件轮转。注意 flock 和 fcntl 语义差异与 NFS 兼容性。
分布式锁(ZK/etcd/Redis RedLock)#
跨主机/服务实例的互斥:任务选主、全局限流。要考虑 租约(TTL)、时钟/网络分区与“最少一次/至多一次”的副作用,尽量设计成可重入、幂等的业务操作。
161. 你遇到最复杂的多线程场景是什么?你具体怎么解决?对于你今后在分析问题有什么考量?#
代表性案例(读多写少的热点索引 + 多生产者/多消费者队列 + NUMA)
症状:QPS 上不去且尾延迟抖动。Perf/火焰图显示 30% CPU 烧在 pthread_mutex_lock,锁等待和 cache miss 居高;top -H 与 thread apply all bt 暴露热点是“全局索引读路径用同一把大锁”,加上队列端有假共享(多个线程写同一 cache line 的队头/队尾),在双路 NUMA 上跨节点访问严重。
诊断步骤
1)稳定复现与基准:固定负载与数据集,记录 P50/P99、CPU/LLC miss/TLB miss。
2)轮廓画像:perf record -g + 火焰图定位锁热点、perf stat 看 CPI/branch/TLB;TSan 验证无数据竞争。
3)锁分析:统计加锁点的平均持有时间与竞争度(埋点或 eBPF uprobes),确认“读路径被大锁覆盖”。
4)硬件/拓扑:numactl --hardware 查看节点,hwloc-ls 看 CPU/内存拓扑,采样远程内存比例。
重构与优化
- 读路径去锁化(RCU/版本化):把热索引改为“不可变快照 + 写时复制”,读线程直接读当前指针;写线程构建新副本并一次性切换。读延迟大幅降低且几乎无竞争。
- 分片锁 + 局部化:对仍需加锁的子结构按 key 哈希分段(64/128 把锁),并将每段数据绑定到 NUMA 节点;读写都尽量落在同核/同节点。
- 队列无锁化与假共享修复:MPSC 改为 per-producer 环 + 单汇聚 或使用经过验证的 MPMC(如 moodycamel),并对头尾指针用
alignas(64)隔离,避免 false sharing。 - 批处理与背压:消费者批量出队、合并写 I/O(group commit),用条件变量或信号量替自旋,减少无效轮询。
- 内存管理:对象池/arena 降低
malloc/free抖动;对大数组启用 hugepage 降 TLB miss。 - 锁顺序与死锁预案:明确全局锁级别与获取顺序,跨组件使用
try_lock+ 回退策略,配合超时与诊断日志避免“无声死锁”。
效果与验收:读路径 P99 从毫秒级降到百微秒内,锁等待时间下降 >90%,LLC/TLB miss 显著减少;在 NUMA 绑定后远程访问下降,尾延迟收敛。留下一套基准与回归测试(压力 + 混沌/抖动),并把关键参数(分片数、批大小、是否 RCU)做成可调。
今后分析问题的考量清单
- 选择最弱同步:能原子就不加锁,能分片就不全局,能读重试就不阻塞。
- 读写比/临界区长度:读多写少优先 RCU/版本化;短临界区可自旋,长临界区用阻塞。
- 竞争度与可分割性:先量化锁竞争,再考虑分区/分层;避免把“不可分”的资源放进热路径。
- NUMA 与内存亲和:first-touch、线程绑核、数据分区;跨节点代价要显式评估。
- 可恢复与可观测:超时、降级、try_lock 回退,日志能定位“谁拿着锁、持有多久”。
- 正确性优先:无锁/乐观结构要配套内存回收(epoch/hazard)与 ABA 防护;单测 + TSan/模型检查覆盖边界。
- 度量驱动:每一次改动都用同一基准验证 P50/P99 与 CPU/缓存计数,避免“感觉良好型优化”
162. 手撕无锁队列#
设计要点
- 结构:单向链表 + 虚拟哑元(dummy)头结点;两个原子指针:
head、tail。 - 入队(enqueue):尝试把
tail->next从nullptrCAS 成新结点;成功后再把tail向后推进(CAS)。若tail->next非空,先帮助推进tail。 - 出队(dequeue):读
head、tail、head->next;若head == tail且next==nullptr队列空;否则把headCAS 到next,返回next->value。并延迟释放旧头(见回收)。 - ABA & 回收:
- ABA:由于我们只单向推进,不会把已删除的节点再插回队列,可用epoch-based reclamation (EBR) 避免悬挂回收;或用 Hazard Pointers(更复杂)。
- 这里实现一个轻量 EBR:每线程进入“临界区”时标记活跃 epoch,退出现有“安全点”;只有当所有活跃线程都不可能再见到某些旧节点时,才回收它们。
注意:真实生产可引入成熟 HP/EBR 库;此处给出教学用、可工作的极简 EBR。
163. 手撕并发哈希表,如何设计细粒度锁#
设计要点#
- 结构:分
S个分片(segment/stripe);每片包含若干桶(拉链法),每片一把shared_mutex。- 查找:读锁该片,遍历桶链。
- 插入/更新/删除:写锁该片,操作对应桶。
- 扩容(再哈希):
- 简洁稳妥做法:全局写锁(短时)阻止并发写,重建
buckets并迁移;查找可用读锁和版本号防止看到中间态。 - 或做增量迁移(复杂):分阶段把旧桶迁到新表,读写需能同时查两处。这里给工程友好的“全局写锁扩容”。
- 简洁稳妥做法:全局写锁(短时)阻止并发写,重建
- 负载因子:达到阈值(如 0.75)触发
rehash(2x)。 - 注意:锁分片比“每桶一把锁”更经济,也更容易控制扩容一致性;热键均衡取决于哈希质量。
代码#
// striped_hash_map.hpp
#pragma once
#include <vector>
#include <shared_mutex>
#include <optional>
#include <functional>
#include <atomic>
#include <list>
#include <utility>
template<class K, class V,
class Hash = std::hash<K>,
class KeyEq = std::equal_to<K>>
class StripedHashMap {
struct BucketKV { K k; V v; };
struct Segment {
mutable std::shared_mutex mtx;
std::vector<std::list<BucketKV>> buckets; // separate chaining
size_t size = 0; // 元素数(仅此 segment)
Segment(size_t nb=8): buckets(nb) {}
};
std::vector<Segment> segs;
Hash hasher;
KeyEq eq;
std::atomic<size_t> total{0};
float max_load = 0.75f;
// 一把全局写锁,仅用于 rehash(频度低)与全局操作
mutable std::shared_mutex global_rw;
public:
explicit StripedHashMap(size_t segments = 64, size_t buckets_per_seg = 8)
: segs(segments, Segment(buckets_per_seg)) {}
// 不存在则插入,存在则更新,返回是否新插入
bool upsert(const K& k, const V& v) {
auto [seg_idx, b_idx] = index_of(k);
Segment& s = segs[seg_idx];
{
std::unique_lock lk(s.mtx);
auto& lst = s.buckets[b_idx];
for (auto& kv : lst) {
if (eq(kv.k, k)) { kv.v = v; return false; }
}
lst.push_front(BucketKV{ k, v });
++s.size;
++total;
}
maybe_rehash(); // 放锁后尝试触发扩容
return true;
}
// 如果键不存在则构造,存在则不变,返回 (引用, 是否新插入)
template<class... Args>
std::pair<V&, bool> get_or_emplace(const K& k, Args&&... args) {
auto [seg_idx, b_idx] = index_of(k);
Segment& s = segs[seg_idx];
{
std::unique_lock lk(s.mtx);
auto& lst = s.buckets[b_idx];
for (auto& kv : lst) {
if (eq(kv.k, k)) return { kv.v, false };
}
lst.emplace_front(BucketKV{ k, V(std::forward<Args>(args)...) });
++s.size; ++total;
return { lst.front().v, true };
}
}
std::optional<V> find(const K& k) const {
auto [seg_idx, b_idx] = index_of(k);
Segment const& s = segs[seg_idx];
std::shared_lock lk(s.mtx);
for (auto const& kv : s.buckets[b_idx]) {
if (eq(kv.k, k)) return kv.v;
}
return std::nullopt;
}
bool erase(const K& k) {
auto [seg_idx, b_idx] = index_of(k);
Segment& s = segs[seg_idx];
std::unique_lock lk(s.mtx);
auto& lst = s.buckets[b_idx];
for (auto it = lst.begin(); it != lst.end(); ++it) {
if (eq(it->k, k)) {
lst.erase(it);
--s.size; --total;
return true;
}
}
return false;
}
size_t size() const noexcept { return total.load(std::memory_order_acquire); }
private:
std::pair<size_t,size_t> index_of(const K& k) const {
size_t h = hasher(k);
size_t seg_idx = h % segs.size();
size_t b_idx = (h / segs.size()) % segs[seg_idx].buckets.size();
return { seg_idx, b_idx };
}
void maybe_rehash() {
// 轻量判断是否需要扩容(近似全局负载)
size_t n = total.load(std::memory_order_acquire);
size_t total_buckets = 0;
for (auto& s : segs) total_buckets += s.buckets.size();
if (static_cast<float>(n) / static_cast<float>(total_buckets) < max_load) return;
// 全局写锁,避免与并发 find/upsert 的重入扩容冲突
std::unique_lock gL(global_rw);
// Double-check
n = total.load(std::memory_order_acquire);
total_buckets = 0;
for (auto& s : segs) total_buckets += s.buckets.size();
if (static_cast<float>(n) / static_cast<float>(total_buckets) < max_load) return;
// 扩容:每个 segment 加独占锁,重建桶并迁移
for (auto& s : segs) s.mtx.lock();
auto unlock_all = [&]{ for (auto& s : segs) s.mtx.unlock(); };
for (auto& s : segs) {
size_t new_nb = s.buckets.size() * 2;
std::vector<std::list<BucketKV>> nb(new_nb);
for (auto& lst : s.buckets) {
for (auto& kv : lst) {
size_t h = hasher(kv.k);
size_t bidx = (h / segs.size()) % new_nb;
nb[bidx].push_front(std::move(kv));
}
}
s.buckets.swap(nb);
}
unlock_all();
}
};